10,000-Word Guide: Technical Principles and Implementation of Structured Output in Large Language Models
# Alibaba Insights
**Advanced Guide to Structured Output in Large Language Models (LLMs)**
---
This article explores the **technological evolution**, **core methodologies**, and **future trends** in generating structured outputs with LLMs. It is designed to help engineers, researchers, and AI practitioners build reliable, machine-readable outputs for scalable applications.
---
## Overview
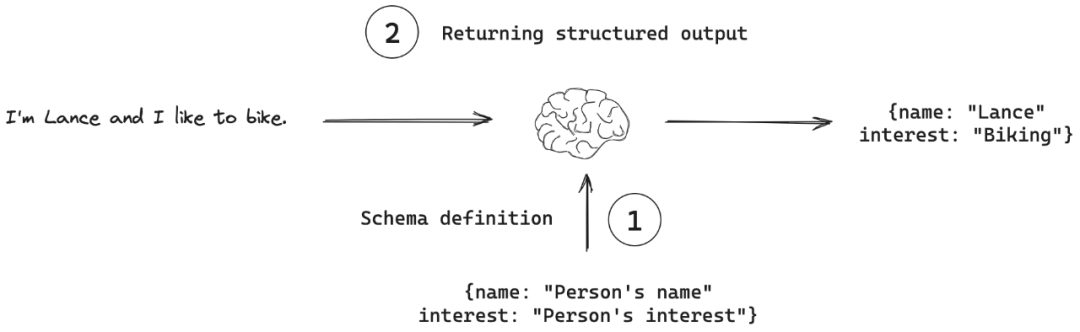
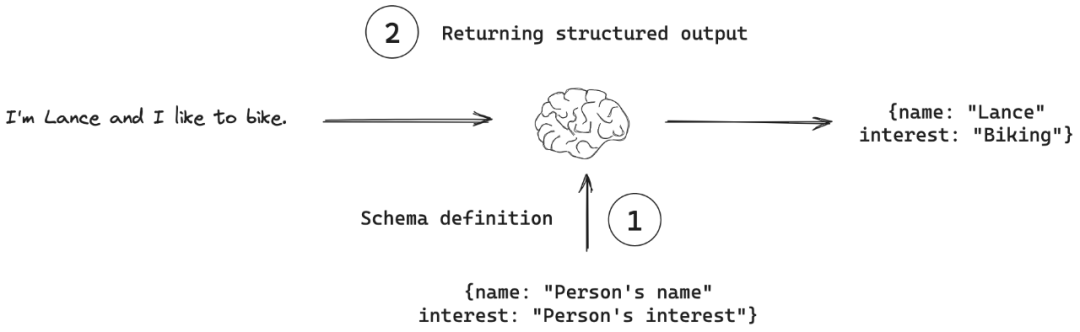
Traditionally, LLMs are optimized for **free-form text output** — great for human readability but difficult for direct machine parsing.
**Structured output** ensures responses adhere to **specific, predefined formats** such as JSON, XML, tables, or fixed templates, enabling:
- Direct integration with APIs, databases, and workflows
- Reduction in post-processing complexity
- Lower incidence of hallucinations and irrelevant data
**Key Insight:** Structured output capability is the *bridge* between **model engineering** and **traditional software engineering**.
---
## 0. Introduction: Paradigm Shift in LLM Outputs
### 0.1 Value & Challenges
Early LLM output:
- **Pros:** Coherent, informative
- **Cons:** No fixed format, parsing ambiguity, error-prone for machine use
Structured output solves this by enforcing consistent, schema-compliant formats:
- **Predictability & consistency**
- **Machine-readability**
- Seamless integration into software pipelines
### 0.2 Technical Paths Explored
We examine **six core techniques**:
1. **Prompt-Guided Generation** – Soft guidance via crafted prompts
2. **Validation & Repair Frameworks** – Post-generation verification
3. **Constrained Decoding** – Hard constraints during generation
4. **Supervised Fine-Tuning (SFT)** – Training with structured datasets
5. **Reinforcement Learning Optimization** – Feedback-driven improvements
6. **API Capabilities** – Built-in schema enforcement and format control in LLM APIs
---
## 1. Prompt-Guided Generation
### 1.1 Principles & Best Practices
Prompt-guided generation uses **descriptive instructions, examples, and templates** to nudge the model toward desired formats.
**Strategies:**
- **Format Anchoring**: Clearly specify required fields and types
- **Few-shot Examples**: Show the model multiple correct samples
- **Error-Tolerant Design**: Add redundancy and clarify instructions
Example:{
"title": "Title",
"content": "Content",
"tags": ["Tag1", "Tag2"],
"metadata": {
"created_at": "Creation Time",
"author": "Author"
}
}
### 1.2 Limitations
- Non-deterministic reliability (~85% in research)
- Small deviations can snowball into broken output
- Requires post-processing in production
---
## 2. Validation & Repair Frameworks
### Workflow:
1. **Define Structure** using schemas (Pydantic, JSON Schema)
2. **Automatic Validation** after generation
3. **Repair via Reask** — request corrections iteratively until compliant
**Benefits:** Raises structural compliance, integrates with multiple LLM providers.
---
## 3. Constrained Decoding
### 3.1 What it Does
Applies **grammar or rule-based constraints** *during* token generation, ensuring each token complies with syntax rules.
### 3.2 Logit-Free Challenge
- Traditional approach needs access to token probabilities
- **Sketch-Guided Constrained Decoding** solves this for black-box models
### 3.3 Pros & Cons
**Pros:** Guarantees syntax correctness
**Cons:** Can degrade reasoning ability under tight constraints
---
## 4. Supervised Fine-Tuning (SFT)
### How it Helps
- Internalizes structured response patterns via labeled datasets
- Uses techniques like **LoRA** for cost-effective fine-tuning
### Challenges
- **Dataset quality is critical**
- “SFT Plateau”: adding more data may not improve performance for high-complexity reasoning tasks
---
## 5. Reinforcement Learning Optimization
### 5.1 Why RL Works
RL provides **dynamic, fine-grained feedback** — improving structured generation beyond SFT’s memorization abilities.
### 5.2 Schema Reinforcement Learning (SRL)
**Stages**:
1. Sampling structured output candidates
2. Rewarding valid schema compliance
3. Updating policy via PPO or similar
### 5.3 Thoughts of Structure (ToS)
Adds a reasoning step before output to improve schema adherence.
---
## 6. API-Level Structured Output Capabilities
### 6.1 Evolution
- From manual prompt design → JSON mode → direct schema enforcement via API parameters
### 6.2 Grammar Constraints (CFG)
Allows precise format control (e.g., SQL, DSLs) in GPT-5 via grammar definitions.
Example:grammar = """start: expr ..."""
### Advantages
- Lower dev burden
- Type safety
- Suitable for enterprise reliability needs
---
## 7. Evaluating Structured Outputs
**Two-Layer Approach**:
1. **Structural Compliance**
- Format validity
- Field completeness
- Type correctness
- Schema consistency
2. **Semantic Accuracy**
- Quality assessment via LLM-as-a-Judge
---
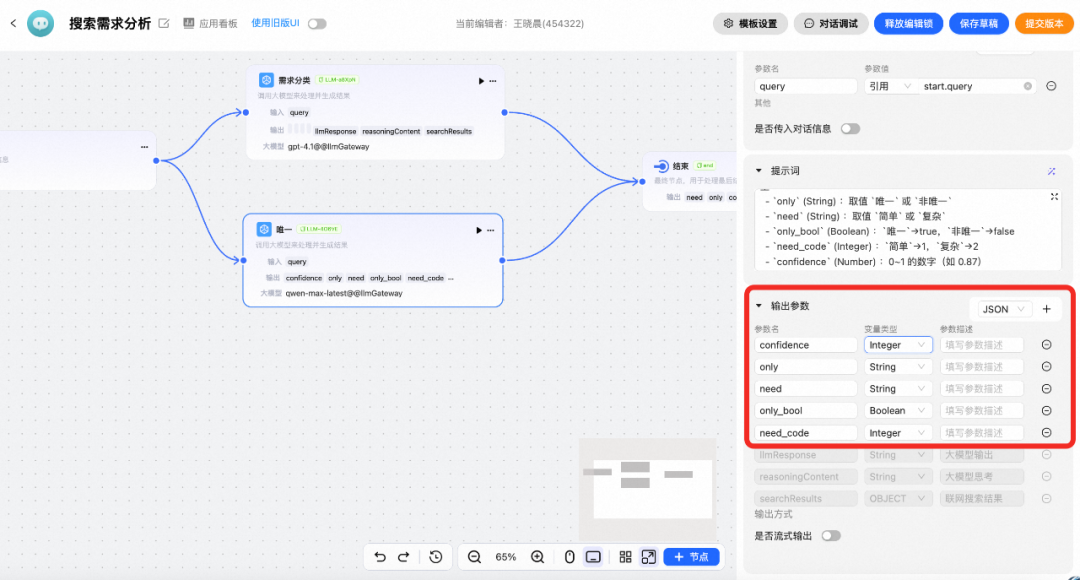
## 8. Gaode LLM Application Platform
Provides **ready-to-use** structured output capability with stable formats and minimal tuning.
---
## 9. Conclusion & Future Trends
### Key Directions:
- **Multimodal Structured Generation**
- **Adaptive Decoding Strategies**
- **Tighter SFT & RL Integration** for balanced generalization and specialization
Structured output is now **foundational** for scalable, reliable AI applications.
Future LLMs will act as **intelligent infrastructure** producing trusted, structured data for automated workflows.
---
## References
- [Guardrails](https://github.com/guardrails-ai/guardrails)
- [Sketch-Guided Constrained Decoding](https://arxiv.org/abs/2401.09967)
- [Schema Reinforcement Learning](https://arxiv.org/abs/2502.18878)
- [LoRA: Low-Rank Adaptation](https://arxiv.org/abs/2106.09685) 


