170,000 Reasoning Traces Reveal the Truth About AI Reasoning: Powerful but Misapplied | Harvard Paper Explained

AI Future Compass — Paper Interpretation Series
Breaking down top conference and journal works from the front line, using the most accessible language.

---
Reflecting on AI in 2025: The Most Fragmented Year Yet
Standing at the tail end of 2025, one thing is clear: this year marked the most fragmented era in AI history.
Two Sides of the AI Story
- Google’s Gemini 3: Proved Scaling Law yet again — bigger parameters, massive GPU stacking, minimal data loss. If you stack enough compute, miracles still seem possible.
- Pre-Gemini Anxiety: Industry insiders felt AI had slammed into an invisible wall.
The Voices of Concern
- Richard Sutton (Father of Reinforcement Learning):
- Warned that today’s models lack true reinforcement learning and continuous learning. Static dataset pretraining will never yield AGI.
- Andrej Karpathy:
- Pointed to practical limits: Agents still fail at complex, long-horizon tasks. Predicted a cognitive gap needing 5–6 years of architectural evolution to overcome.

---
Defining the “Cognitive Gap”
Yoshua Bengio once compared human vs. LLM intelligence across 10 macro dimensions. But in 2025, researchers from UIUC, University of Washington, and others dug deeper with:
The Cognitive Foundations of Reasoning and Their Manifestation in Large Language Models (arXiv link).
They analyzed 170,000 reasoning trajectories from DeepSeek-R1 and Qwen3.
Key Conclusion:
> Current AI shows severe misalignment between cognitive capabilities and actual problem-solving effectiveness.

---
01 — Misaligned Cognitive Capabilities
Introducing 28 Cognitive Primitives
This micro-level approach resembles Bengio’s AGI framework but focuses on core reasoning functions.
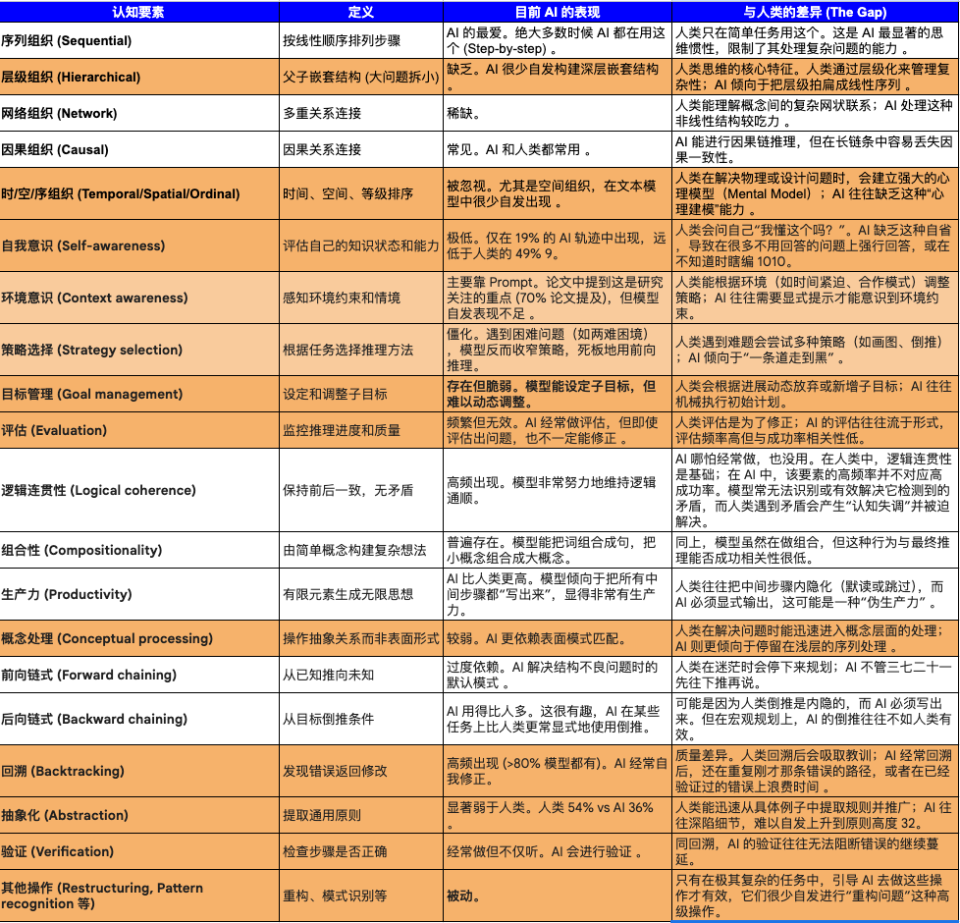
AI’s Cognitive “OCD”
- Models overuse:
- Logical coherence
- Forward chaining
- Heatmaps show these in bright red — frequent but poorly correlated with success.
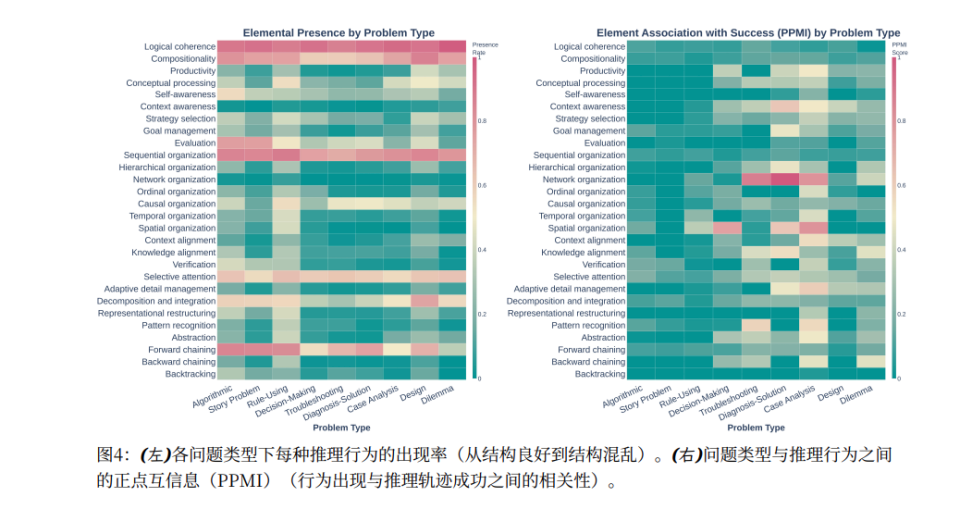
The Harsh Truth
- Logical coherence success correlation: NPMI = 0.090 → Looks thoughtful, solves little.
- Diagram of actual reasoning pathways reveals misplaced cognitive priorities.

---
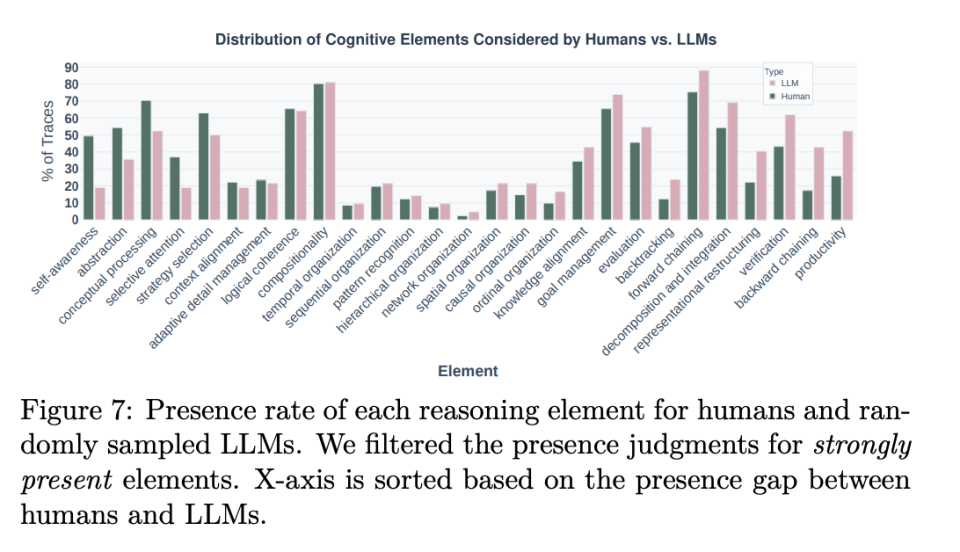
Key High-Impact Abilities (Rarely Used by AI)
- Selective Attention — Discard irrelevant 90%, focus on useful 10%.
- Network Organization — Recognize web-like interconnections, not just linear links.
- Abstraction — Derive general rules from specific cases.
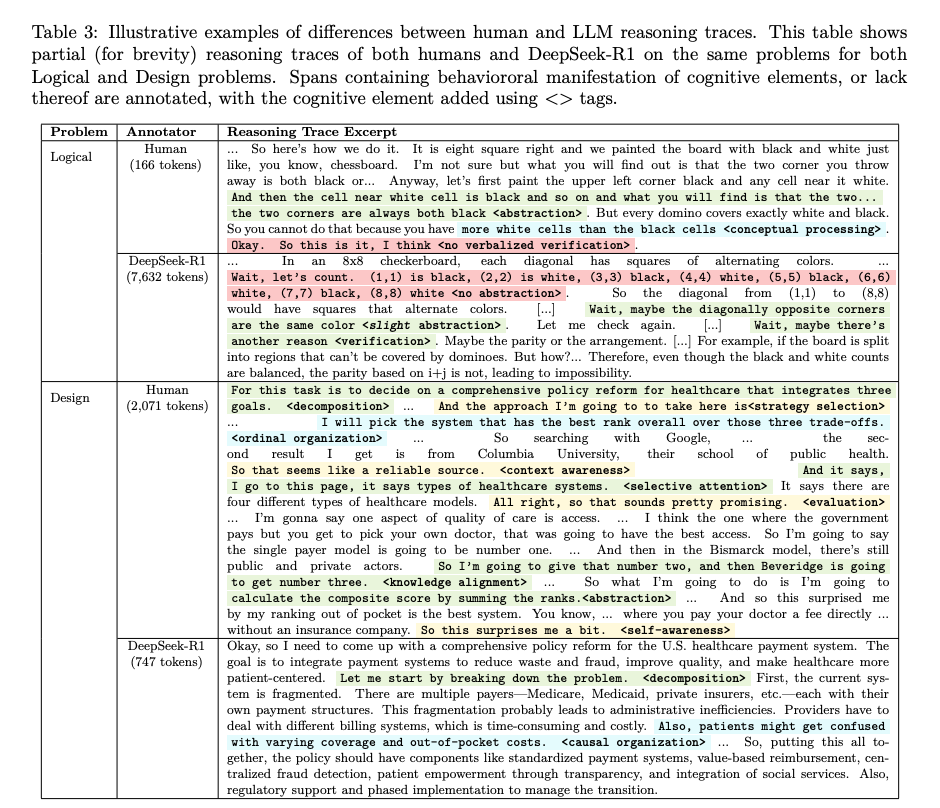
Observed Failure Patterns
- These skills are “cold blue” on AI’s heatmap — models almost never activate them.
- Inverse Relationship phenomenon:
- Humans use more cognitive tools for harder problems.
- AI uses fewer when facing complexity — retreats to forward chaining.
---
Karpathy’s Agent Dilemma
- Simple tasks: AI shines.
- Real-world chaos: loops, hallucinations, wrong execution.
- Cause: No strategy reconstruction under uncertainty.
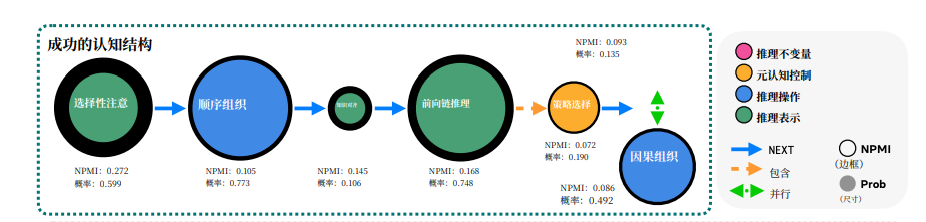
Success Diagram Insights:
- Selective Attention at the start (NPMI 0.272 — highest success correlation).
- Knowledge Alignment before deduction.
- Strategy Selection during deduction.
---
02 — Why Benchmarks Are Misleading
Current benchmarks (e.g., GSM8K, HumanEval):
- Outcome-oriented → Ignore process quality.
- Foster high-score but low-skill AI.
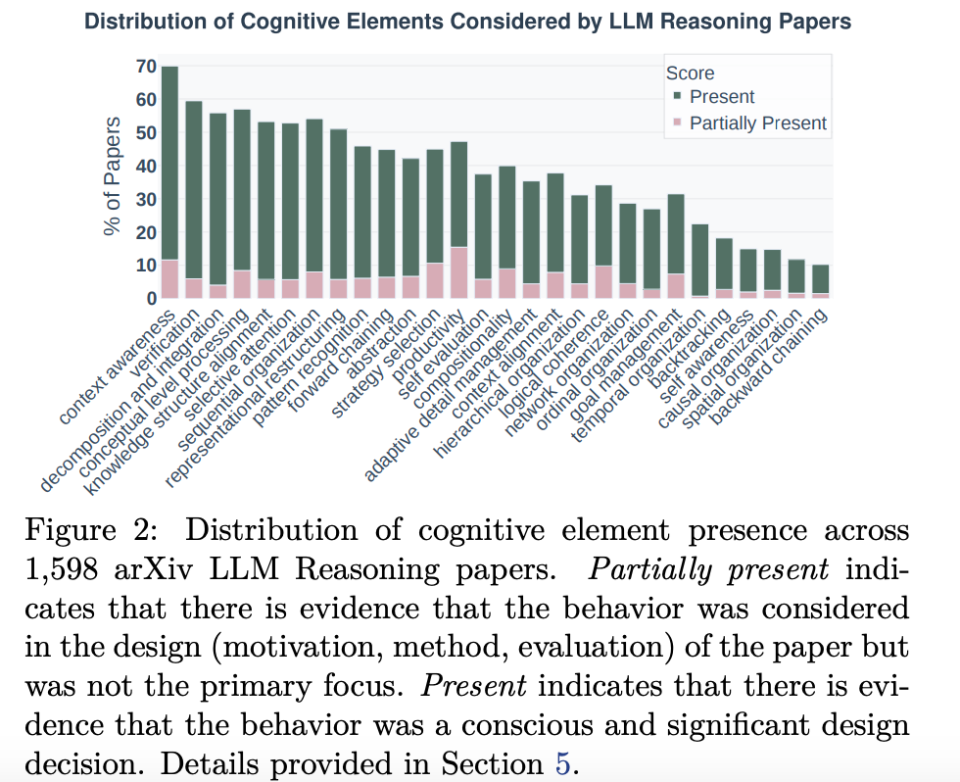
Meta-analysis Results
Out of 1,598 reasoning papers:
- 55% focus on sequence organization.
- 16% on self-awareness.
- 10% on spatial organization.
---
Impact of Benchmark-Driven Training
- Outcome-based rewards (ORM): Only correct/wrong at the end.
- Process-based RL (PRM): Rewards correct steps without assessing high-level strategy.
Result:
> Models excel at performative reasoning (looking like they think), fail at functional reasoning (actually solving problems).
---
03 — The Missing Training Guidance
Test-Time Reasoning Guidance
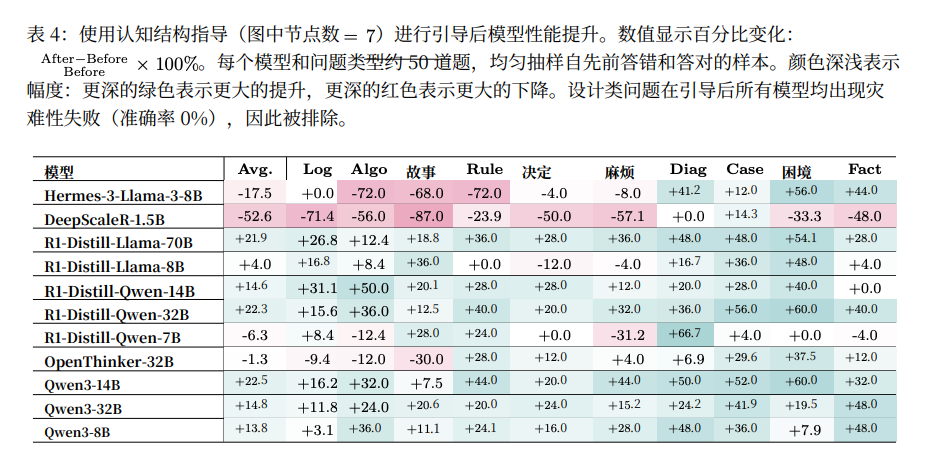
Researchers tested cognitive blueprints:
Example for diagnostics:
`Selective Attention → Sequential Organization → Knowledge Alignment → Forward Reasoning → Strategy Selection`
Results:
- Guided models improved up to +60% in hardest problems.
- Proof: Structure > Scale — correct reasoning path unlocks latent capabilities.
---
Reforming Reward Models
Goal: Internalize these blueprints during training.
Proposed Methods:
- Structure-based rewards — Reward spontaneous use of correct reasoning flows; penalize random calculation-first approaches.
- Curriculum design — Train on structurally identical problems with varied surface narratives.
- Schema recognition — Encourage networked/hierarchical organization in answers.
Challenge:
Blueprint works as a “medicine” in prompts but isn’t yet baked into model parameters — turning prompt engineering into embedded training might take 5–6 years, aligning with Karpathy’s projection.
---
Practical Implications Beyond Research
Platforms like AiToEarn官网 aim to:
- Integrate advanced reasoning structures into AI workflows.
- Enable creators to generate, publish, and monetize content across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
- Provide open-source tools (GitHub, AI模型排名) to bridge cognitive AI reasoning with real-world distribution.
---
Final Takeaway
Closing the AI “cognitive gap” will require:
- Reward models valuing quality of thought, not just end results.
- Embedding selective attention, abstraction, networked reasoning into AI’s core logic.
- Applying these structures not only in research, but in practical, wide-scale content and decision-making systems.
---
Do you want me to follow up by redesigning the diagrams and taxonomy into a simplified visual summary so readers can grasp the “28 cognitive primitives” hierarchy instantly? That would make this Markdown even more impactful.


