A Model That Lets Robots Learn the World Through “Imagination” — Co-created by PI Founding Research Group & Tsinghua’s Chen Jianyu Team
CTRL-WORLD: Controllable Generative World Model for Robotics
Background
In recent days, Physical Intelligence (PI) co‑founder Chelsea Finn has expressed strong support for a new robotics world model project from Stanford, co‑developed with Chen Jianyu’s team at Tsinghua University.
Finn emphasizes:
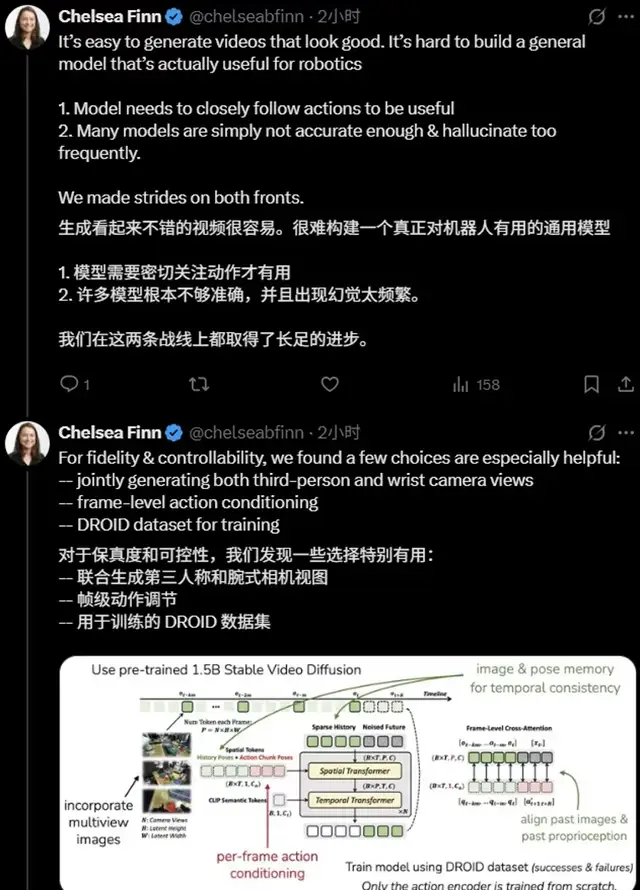
> “It’s easy to generate videos that look good; the hard part is building a truly general-purpose model that’s actually useful for robots — it needs to closely track actions and remain accurate enough to avoid frequent hallucinations.”
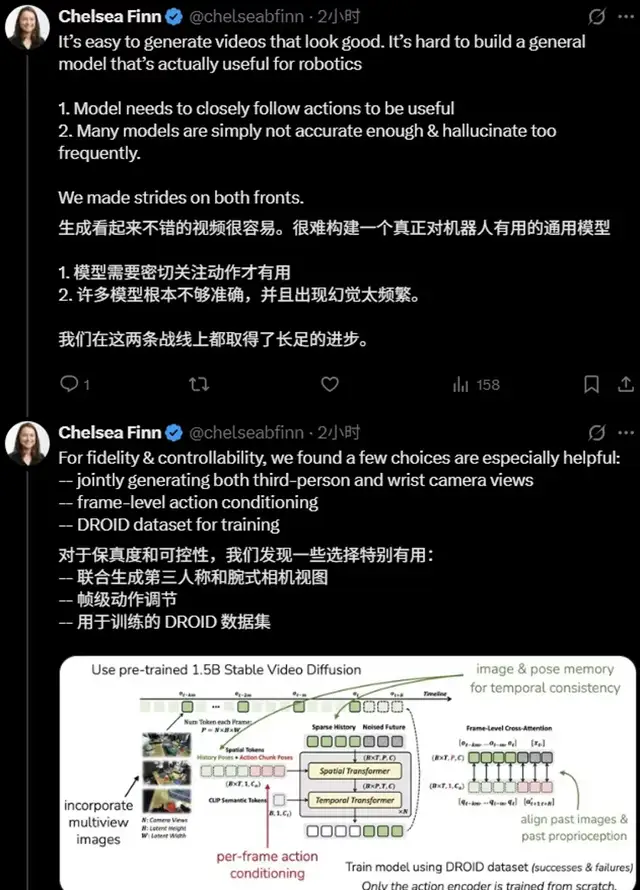
---
What is CTRL-WORLD?
The controllable generative world model CTRL‑WORLD enables robots to:
- Perform task simulations
- Conduct strategy evaluation
- Self‑iterate entirely in an imagination space
Key result:
Using zero real‑world robot data, the model boosts instruction‑following success rates in some downstream tasks from 38.7% → 83.4%, an average improvement of 44.7%.
📄 Paper: CTRL-WORLD: A Controllable Generative World Model for Robot Manipulation — arXiv

---
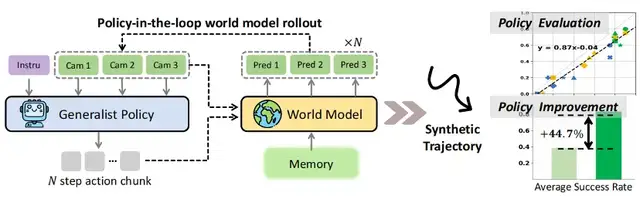
Core Purpose
CTRL-WORLD is specifically designed for policy‑in‑the‑loop trajectory simulation for general-purpose robot policies.
It offers:
- Multi‑view prediction (including wrist‑camera perspectives)
- Fine‑grained motion control via frame‑level conditional control
- Long‑horizon stability via pose‑conditioned memory retrieval
This enables:
- Accurate strategy evaluation in imagination space aligned with real‑world trajectories
- Targeted strategy improvements using synthetic rollouts
---
Why CTRL-WORLD Was Needed
Challenge 1 – High Cost of Strategy Evaluation
Testing robots in the real world is:
- Expensive — physical damage risk and consumables cost
- Time‑consuming — multi‑day processes
- Incomplete — can’t cover all possible scenarios
Example: Grasping objects requires varying material, lighting, textures, and hundreds–thousands of trials.
---
Challenge 2 – Difficulty in Strategy Iteration
Even large‑scale trained VLA models (e.g., π₀.₅ on DROID dataset) drop from 95k trajectories → only 38.7% success on unfamiliar tasks.
Problems:
- Human expert annotations take too long and cost too much
- Coverage gaps for unusual instructions and objects
---
Limitations of Traditional World Models
While simulators can let robots "train in imagination," most prior models can’t interact deeply with policies.
Three critical pain points:
- Single‑view hallucinations
- Partial observability: can’t see wrist‑object contact
- Object “teleports” into gripper without real contact
- Lack of fine control
- Only coarse text/image conditions
- Subtle motion changes ignored (e.g., 6 cm vs 4 cm on Z‑axis)
- Poor long‑term consistency
- Temporal drift over time → no reference to real physics
---
CTRL-WORLD Innovations
Joint Stanford–Tsinghua design tackles fidelity, controllability, and long‑horizon coherence via:
- Multi‑view joint prediction
- Frame‑level action‑conditioned control
- Pose‑conditioned memory retrieval
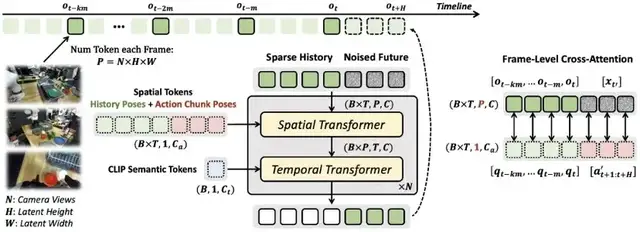
Multi‑View Input
Combines third‑person and wrist‑camera views:
- Third‑person: global object and environment layout
- Wrist view: precise contact states & micro‑interaction details

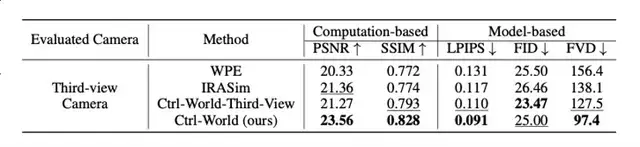
Impact:
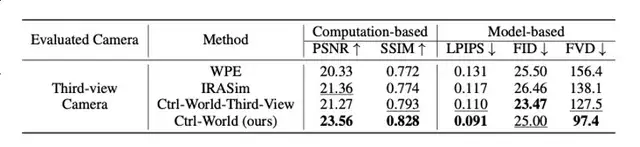
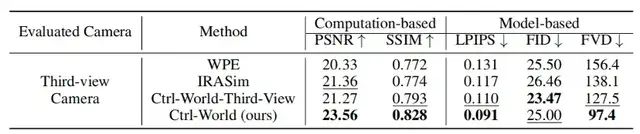
Lower hallucination rates, PSNR 23.56 vs baseline WPE 20.33, SSIM 0.828 vs 0.772.
---
Frame‑Level Action Binding
Creates strong causal link between actions & visuals:
- Robot joint velocities → Cartesian arm pose parameters
- Cross‑attention aligns each visual frame to its pose
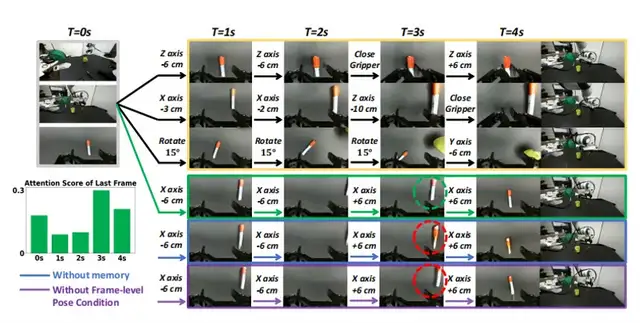
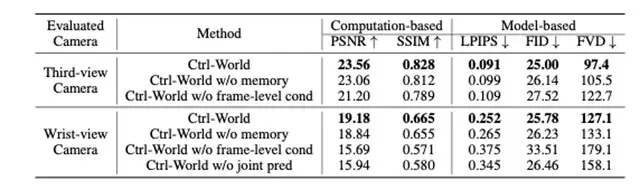
Impact:
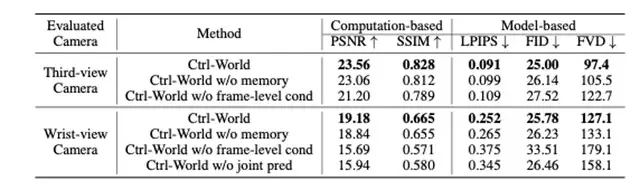
Removing action conditioning drops PSNR 23.56 → 21.20, confirming precise control is core.
---
Pose‑Conditioned Memory Retrieval
Prevents temporal drift:
- Sparse Memory Sampling — pick key historical frames
- Posture‑Anchored Retrieval — match similar poses to calibrate predictions

Impact:
Generates coherent trajectories beyond 20s
FVD = 97.4 vs baselines 156.4 / 138.1
---
Experimental Results
Test platform: Panda robotic arm + wrist camera + 2 external cameras
10s rollouts, 256 random clips:
- PSNR: 23.56 (↑15–16% over baselines)
- SSIM: 0.828 (↑~7%)
- LPIPS: 0.091 (lower, better perceptual quality)
- FVD: 97.4 (↑ 29–38% temporal coherence)
Generalization: Handles new camera layouts in zero‑shot fashion.
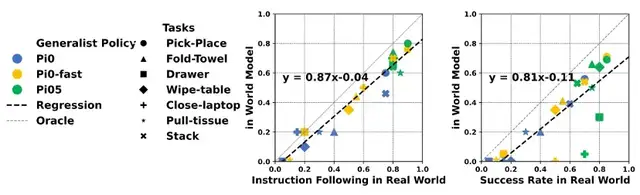
Correlation with real-world:
Command-following rate corr = 0.87
Task success rate corr = 0.81
---
Simulation-to-Reality Optimization
Pipeline (per paper’s Algorithm 1):
- Virtual Exploration
- Rephrase instructions
- Reset initial states randomly
- Generate 400 novel task trajectories
- Filter High‑Quality Data
- Human labelers select 25–50 successful trajectories
- Supervised Fine‑Tuning
- Fine-tune π₀.₅ with filtered virtual data
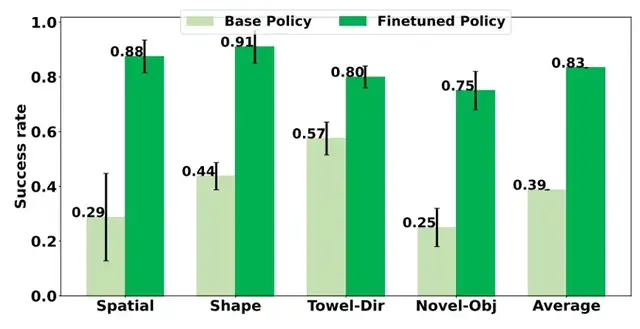
Task Success Rate Improvements:
- Spatial understanding → 28.75% → 87.5%
- Shape understanding → 43.74% → 91.25%
- Towel folding → 57.5% → 80%
- New objects → 25% → 75%
Average: 38.7% → 83.4% with no real-world cost.
---
Current Limitations & Future Work
- Physical modeling gaps — liquid, high-speed collisions
- Sensitivity to initial input quality — poor first frame leads to error accumulation
Planned directions:
- Integrating reinforcement learning
- Expanding datasets to more extreme environments
---
Potential Impact
CTRL-WORLD replaces traditional:
> Real Interaction → Data Collection → Model Training
with
> Virtual Pre‑Run → Evaluation → Optimization → Real Deployment
Benefits:
- Industrial: Commissioning cycle reduced from 1 week → 1 day
- Household robots: Faster adaptation to personalized tasks
---
Links
---
Related Platforms
Emerging ecosystems such as AiToEarn官网 can:
- Publish & monetize AI content across major platforms
- Integrate analytics, model ranking (AI模型排名)
- Support rapid dissemination of innovations like CTRL‑WORLD
👉 AiToEarn文档 | AiToEarn博客
---
Summary:
CTRL-WORLD delivers multi‑view fidelity, precise controllability, and long‑horizon stability, achieving large real‑world performance gains without real‑world training data — a major step forward in simulation-driven robot learning.


