A New Model Lets Robots “Imagine” the World — Joint Release by PI Co‑Founders & Tsinghua’s Chen Jianyu Team
CTRL-WORLD: A Controllable Generative World Model for Robot Manipulation
In recent days, Chelsea Finn, co‑founder of Physical Intelligence (PI), has been engaging with a new world model research project from her Stanford group.
> Generating visually appealing videos is easy — the challenge is building a truly general‑purpose model for robots that follows actions precisely and avoids frequent hallucinations.

Overview
This research introduces CTRL‑WORLD, jointly developed by Finn’s Stanford team and Jianyu Chen’s group at Tsinghua University.
It is a breakthrough system enabling robots to rehearse tasks, evaluate strategies, and iterate autonomously — all within an “imagination space.”
Key Result: Using zero real robot data, the model improves instruction‑following performance in downstream tasks — boosting success rates from 38.7% to 83.4% (average +44.7%).
📄 Paper: CTRL-WORLD: A Controllable Generative World Model for Robot Manipulation

---
Design Purpose
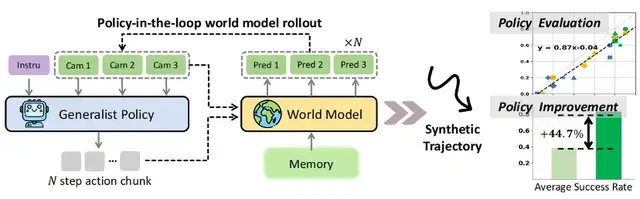
CTRL‑WORLD is built specifically for policy‑in‑the‑loop trajectory rollouts in general robot manipulation, featuring:
- Joint multi‑view predictions (including wrist‑view)
- Fine‑grained motion control via frame‑level conditional inputs
- Coherent long‑term dynamics through pose‑conditioned memory retrieval
These enable:
- Precise policy evaluation in imagination aligned with real-world rollouts.
- Targeted policy improvements using synthetic trajectories.
---
Motivation: Challenges in Open‑World Robotics
Challenge 1 — High‑Cost, Inefficient Policy Evaluation
Policy evaluation demands extensive trial‑and‑error across tasks and conditions.
Example: “Grasping objects” — requires varied size, shape, material, lighting, and hundreds/thousands of repetition cycles.
Issues:
- Arm collisions (~5–8% failure rate)
- Object breakage (> ¥1,000 per evaluation round)
- Cycles often span days
- Sampled tests fail to cover all real‑world conditions
Challenge 2 — Hard Policy Iteration, Limited Real Data
Despite large datasets (e.g., DROID: 95k trajectories, 564 scenes), π₀.₅ achieves only 38.7% success on unseen instructions/objects.
Manual improvement:
- Requires expert annotation
- 100 high quality towel‑folding trajectories → 20h work, > ¥10,000 cost
- Still can’t cover all novel cases
---
Pain Points of Traditional World Models
While world models aim to reduce real‑world dependence, most target passive video prediction — lacking active interaction with advanced policies.
Three main limitations:
- Single‑View → Hallucination
- Missing wrist‑object contact leads to unrealistic predictions.
- Coarse Action Control
- Fail to bind high‑frequency fine‑motion signals — small numerical errors drift over time.
- Poor Long‑Term Consistency
- Small errors accumulate, causing “temporal drift” in extended rollouts.
---
CTRL‑WORLD Innovations
Teams from Stanford & Tsinghua jointly propose CTRL‑WORLD — precise, long‑term stable, and reality‑aligned virtual training.
Adaptation Process:
Initialized from pretrained video diffusion → transformed into controllable, temporally consistent world model.
Core Designs:
- Multi‑view input & joint prediction
- Frame‑level action‑conditional control
- Pose‑conditioned memory retrieval
---
Multi‑View Prediction
Traditional: single third‑person view → partial observation.
CTRL‑WORLD: third‑person + wrist‑view → accurate, physically consistent future trajectories.

Fusion: Spatial transformer merges tokens from multiple 192×320 images → 24×40 latent features.
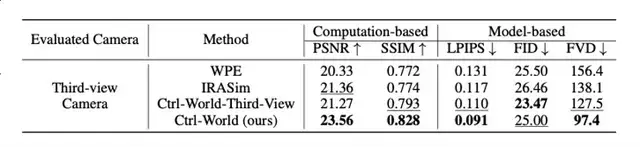
Impact:
- Wrist view captures contact state → fewer phantom grasps
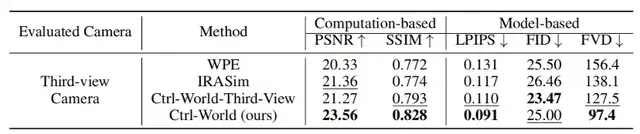
- Metrics: PSNR 23.56 vs WPE 20.33, IRASim 21.36; SSIM 0.828 vs 0.772/0.774.
---
Frame‑Level Action Binding
To ensure action → visual outcome:
- Convert robot joint velocities → Cartesian pose parameters
- Bind each visual frame to its pose via cross‑attention
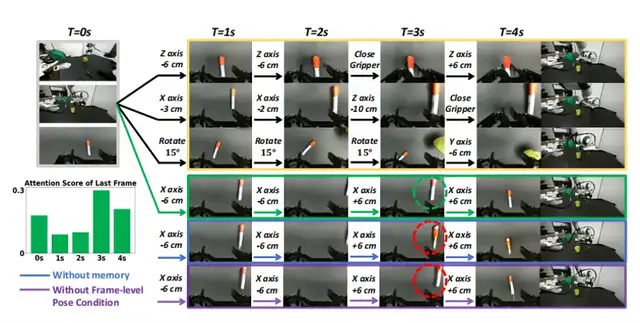
Result: Centimeter‑level action fidelity in rollouts.
---
Pose‑Conditioned Memory Retrieval
Goal: Eliminate temporal drift.
- Sparse sampling: k=7 frames at fixed intervals
- Pose‑anchored retrieval: Use pose similarity to calibrate predictions

Ensures >20s coherent trajectory:
- FVD 97.4 vs WPE 156.4, IRASim 138.1
---
Experimental Results
Platform: DROID (Panda arm + 1 wrist cam + 2 third‑party cams)
10s Trajectory Generation Test:
- PSNR: 23.56 (+15–16%)
- SSIM: 0.828 (+structural consistency)
- LPIPS: 0.091 (near real scene)
- FVD: 97.4 (temporal coherence +29–38%)
Simulation → Reality Correlation:
- Instruction follow rate: r = 0.87
- Task success rate: r = 0.81
-> Evaluation cycle cut from weeks to hours
---
Policy Optimization via Virtual Rollouts
Steps:
- Virtual Exploration: Rephrase instructions & reset states → 400 rollouts for unfamiliar tasks
- Filter High‑Quality Data: Select 25–50 successful trajectories
- Supervised Fine‑Tuning: Update π₀.₅ with selected data
---
Improvement Summary
Unfamiliar Scenarios Gains:
- Spatial tasks: 28.75% → 87.5%
- Shape tasks: 43.74% → 91.25%
- Towel folding: 57.5% → 80%
- New objects: 25% → 75%
Overall: 38.7% → 83.4% (+44.7%)
Cost: 1/20 of traditional methods, no physical resource use.
---
Remaining Limitations
- Physics adaptation gap: Liquids, high‑speed collisions — still imperfect gravity/friction.
- Initial frame sensitivity: Poor first observation → compounding errors.
Future Plans:
- Combine video generation with RL for self‑exploration in virtual space
- Expand scenes: greasy kitchens, outdoor lighting, extreme conditions
---
Broader Implications
CTRL‑WORLD shifts from:
- Traditional: “Real → Data → Train”
- To: “Virtual Rehearsal → Eval → Optimize → Deploy”
Potential applications:
- Industrial: Shorten production line tuning from 1 week to 1 day
- Home Service Robots: Tailor tasks to irregular objects/clutter
As video diffusion accuracy rises, CTRL‑WORLD could become a universal robot training platform, accelerating humanoid deployment.
---
Links:
---
> Related: Platforms like AiToEarn官网 extend similar “imagine and iterate” loops into creative AI — integrating generation, multi‑platform publishing, analytics, and ranking. Just as CTRL‑WORLD optimizes virtual robot rehearsal, AiToEarn enables creators to accelerate content iterations and monetization across Douyin, Bilibili, Facebook, Instagram, YouTube, and X/Twitter.


