# Driving RL4LLM into a Practical, Scalable Future
**Date:** 2025-11-10 12:38 Beijing

> **Let’s work together to drive LLM reinforcement learning toward a broader, practical, and scalable future!**
---
## Overview
The Alibaba **ROLL** team — in collaboration with Shanghai Jiao Tong University and The Hong Kong University of Science and Technology — has introduced the **“3A” collaborative optimization framework**:
1. **Async Architecture** (Asynchronous Training)
2. **Asymmetric PPO** (AsyPPO)
3. **Attention Rhythm** (Attention-based Reasoning Rhythm)
These three tightly integrated components aim to push **RL4LLM** toward higher **efficiency**, **precision**, and **interpretability**.
**Key principle:** Decoupling with rules of *fine-grained parallelism* and *sampling–training separation* results in fully asynchronous execution — boosting GPU utilization without sacrificing performance.
**Open Source Repo:** [https://github.com/alibaba/ROLL](https://github.com/alibaba/ROLL)
---
## The “3A” Framework in Detail
### 1A: Async Architecture — High-Efficiency RLVR & Agentic Training
#### Problem with Synchronous RL
Traditional synchronous RL pipelines (`generate → evaluate → learn`) suffer from:
- **Long-tail latency**: slowest sample stalls the batch
- **Environment blocking**: GPUs idle while waiting for external environments
- **Scalability bottlenecks**: sync points grow exponentially with GPU count

[Paper link](https://arxiv.org/abs/2510.11345)
---
#### The ROLL Flash Solution
ROLL Flash restructures RL pipelines into a **producer–consumer model** with **native async design**:
**Core Principles**:
- **Fine-grained Parallelism**
- **Rollout–Train Decoupling**
**Benefits**:
- Overlapping compute with I/O waits
- Full pipeline parallelism (generation, environment interaction, reward calculation, training)
- Maximized GPU utilization
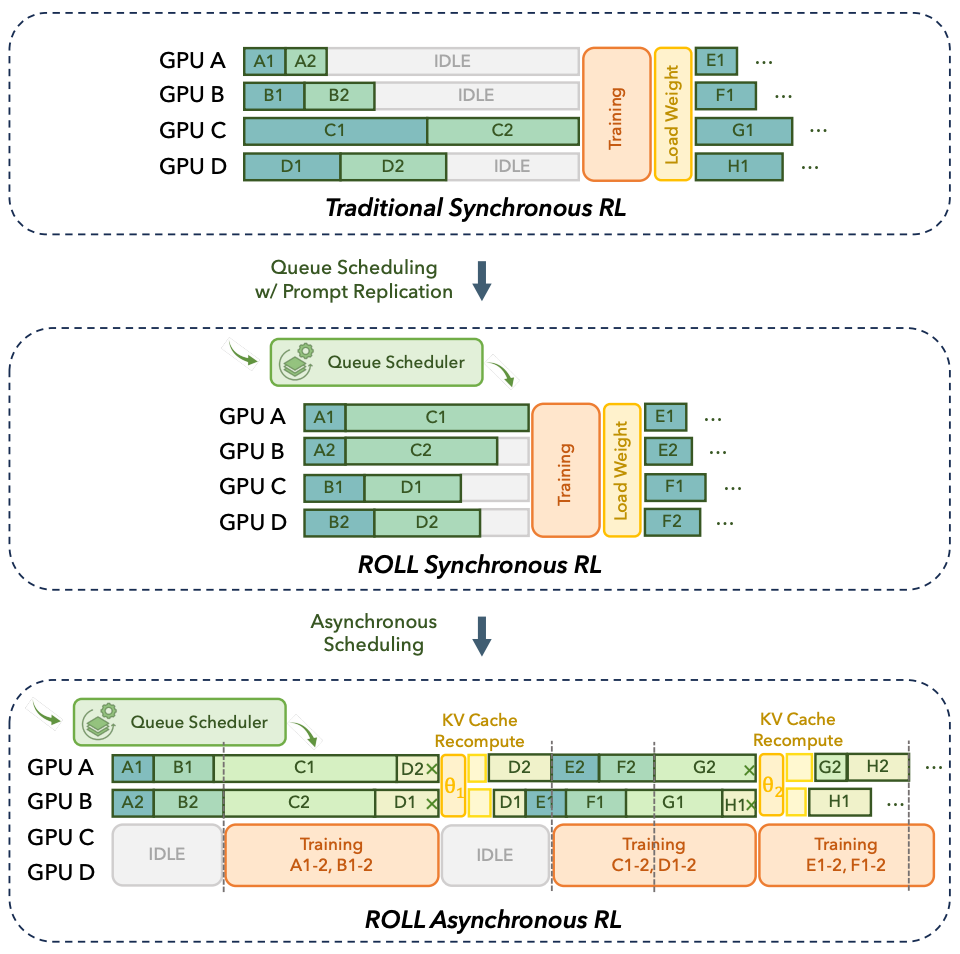
*Figure: Sync vs Async architectures in ROLL*
---
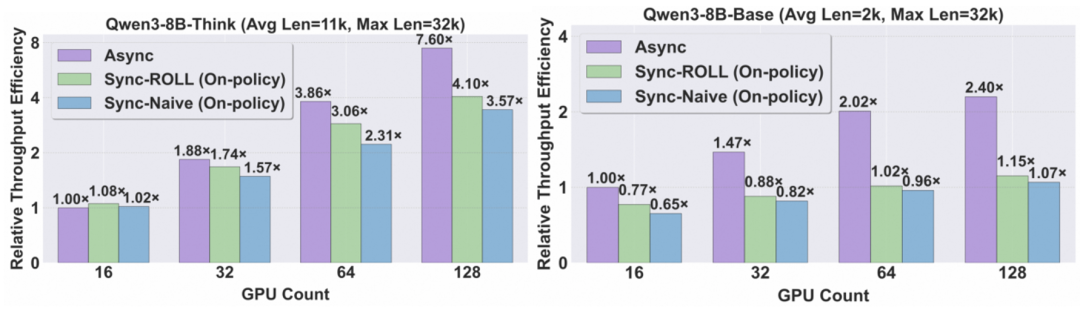
#### Experimental Highlights
- **2.72× speedup** (Agentic tasks), **2.24× speedup** (RLVR tasks)
- **Near-linear scalability** (e.g., 8× GPUs → 7.6× throughput gain)
- **Comparable performance** to synchronous training via off-policy algorithms
- **Flexible scheduling** via *Asynchronous Ratio* parameter
---
#### Four Core Technologies
1. **Queue Scheduling**: Eliminates long-tail effect
- Up to 2.5× acceleration under large batch configs
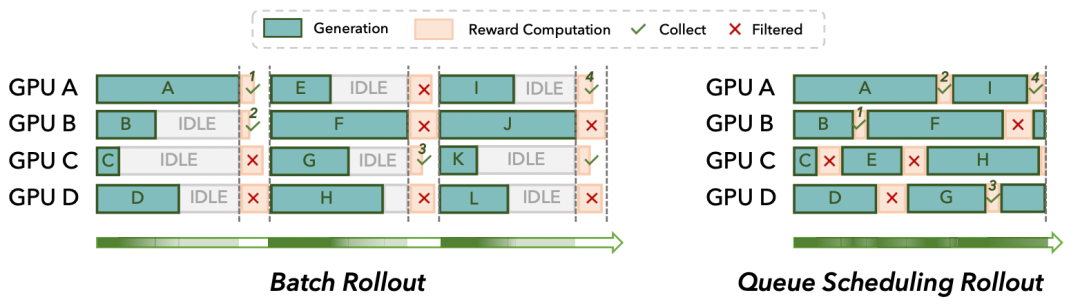
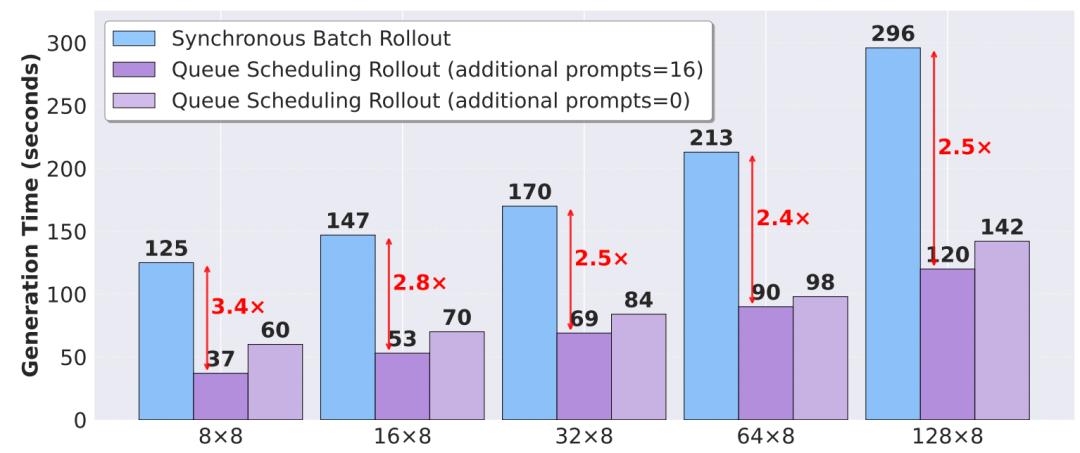
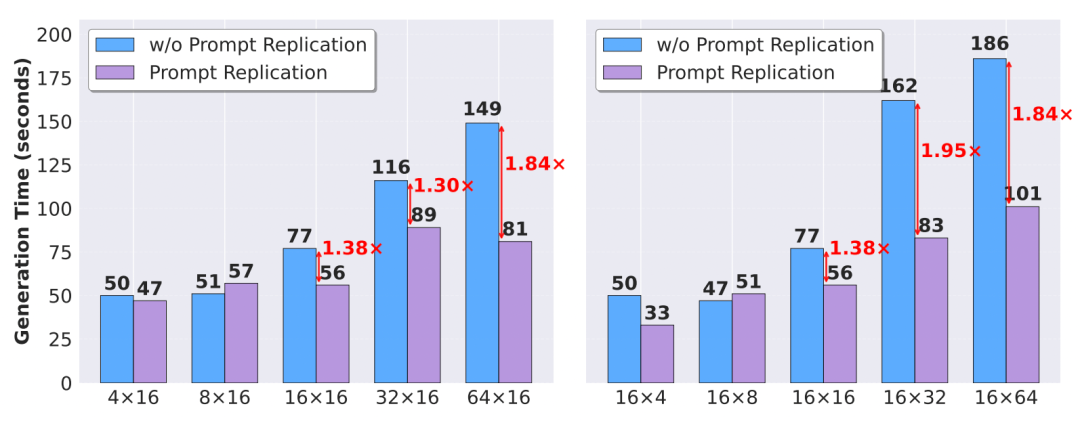
2. **Candidate Generation Parallelization**:
- “One-to-many” transformed into “many-to-one” for multi-candidate prompts
- Up to 1.95× improvement
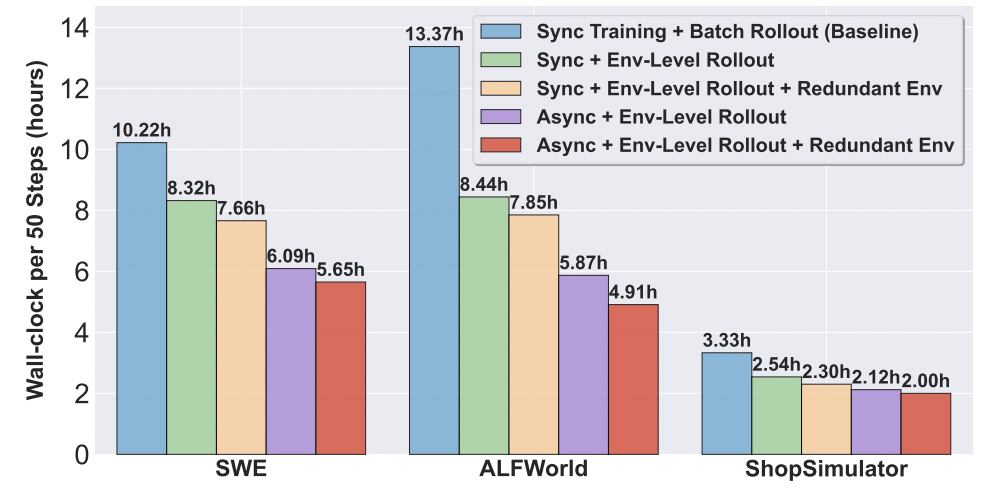
3. **Environment-Level Async Rollout**:
- Overlaps computation and environment delays
- 1.58× speedup in ALFWorld tests
4. **Redundant Environment Rollout**:
- Handles slow/fail-stop environments
- Adds **7%–16%** throughput gains
---
#### Stability Features
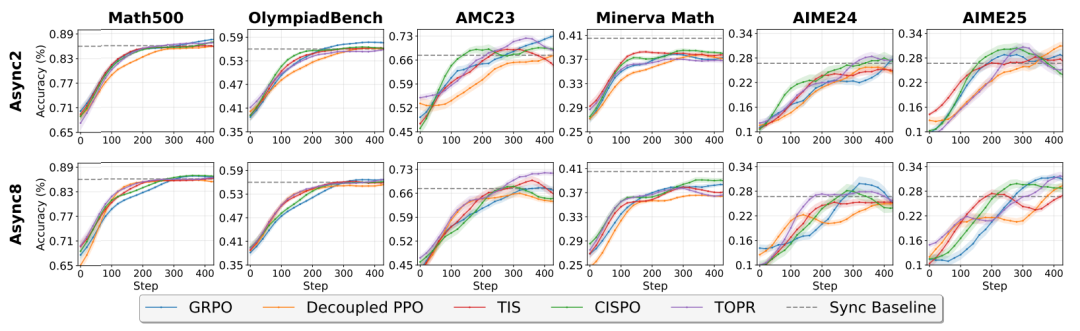
- **Asynchronous Ratio**: Balance sample freshness vs resource utilization
- **Off-policy Algorithm Integration**: Decoupled PPO, TOPR, TIS, CISPO, GRPO
---
### 2A: Asymmetric PPO — Mini-Critics for Efficiency
[Paper link](https://arxiv.org/abs/2510.01656)

**Key Insights:**
1. **Critics stabilize PPO training**
2. **Small critics can be as effective** as large ones
3. **Critic disagreements** provide optimization signals
---
#### AsyPPO Innovations
- **Mini-Critic Aggregation**: Multiple lightweight critics trained on partitioned data
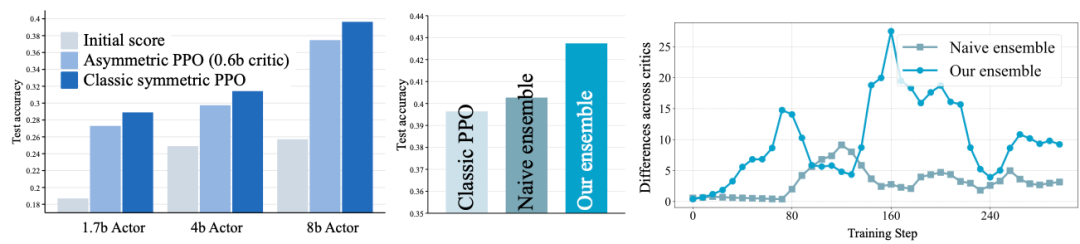
- **Uncertainty-Aware Loss Reconstruction**:
- Agreement → shield noisy samples
- Disagreement → remove from entropy regularization

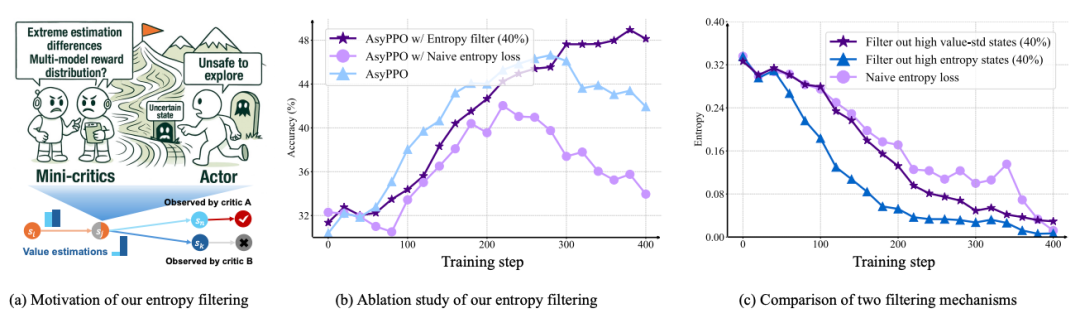
---
#### Advantages
- **Stable training** without collapse
- **Lower compute costs** (ditch giant critics)
- **~20s faster per training step**
#### Impact
- Enables **smaller teams** to use PPO-based RLHF
- Revives critic-based methods in LLM fine-tuning
---
### 3A: Attention Rhythm — Structure-Aware Credit Assignment
[Paper link](https://arxiv.org/abs/2510.13554)

**Objective**: Transform RL reward allocation from **sequence-level uniformity** to **dynamic, token-level structure-aware credit**.
---
#### Attention as Blueprint
- **Local view**: token’s dependence on context
- **Global view**: token’s influence on future tokens
**Metrics**:
1. **Windowed Average Attention Distance (WAAD)**: Local chunk boundaries

2. **Future Attention Influence (FAI)**: Global anchors

---
#### Coupling Pattern: Pre-Planning → Anchoring
- WAAD peaks → context retrieval (pre-planning)
- FAI peaks → semantic anchors
- Together form “reasoning beats” repeated in inference
---
#### RL Strategies
1. **Local Chunk Credit**: amplify pre-planning tokens
2. **Global Anchor Credit**: amplify high-FAI tokens
3. **Coupled Rhythm Credit**: amplify both for synergy
---
#### Implementation
- Auxiliary Transformer (`actor_attn`) captures attention maps
- Attention sampled from middle network layers
- Adds only one forward pass overhead per update
---
#### Experimental Results
**Countdown Puzzle:** Coupled credit: **63.1%** vs baseline **52.6%**
**CrossThink-QA:** Best: **50.1%** vs baseline
**Math Reasoning (AIME, AMC, MATH500, OlympiadBench)**: consistent gains
Ablations confirm **top-k token targeting** works best (40% top tokens)
---
## Bonus: ROCK — Reinforcement Open Construction Kit
**Features**:
- Stable sandbox management isolation
- 24/7 health monitoring
- Automatic fault recovery
- Visual dashboards
**Repo:** [https://github.com/alibaba/ROCK](https://github.com/alibaba/ROCK)
---
## Future Outlook
ROLL team aims to:
- Advance **system + algorithm co-innovation** in RL for LLMs
- **Open-source** tooling for efficiency, scalability, and transparency
- Empower both **researchers and creators** to deploy high-performance LLM workflows
**Get Involved**:
- [ROLL GitHub](https://github.com/alibaba/ROLL)
- [ROCK GitHub](https://github.com/alibaba/ROCK)
---
© **THE END**
[Read Original](2651000759)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=afc71be0&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzA3MzI4MjgzMw%3D%3D%26mid%3D2651000759%26idx%3D1%26sn%3D04de996399a1e4104ff5fd1dce1d3a0c)



