According to Bengio’s New AGI Definition, GPT-5 Has Achieved Less Than 10%

Setting a “Passing Line” for AGI — GPT‑4 & GPT‑5 Scored as Poor Students?
Artificial General Intelligence (AGI) is the main focus of most leading AI research labs, but its exact definition has long been debated. In pursuing the “holy grail” of AGI, what are we really aiming to achieve?
Recently, Turing Award winner Yoshua Bengio, former Google CEO Eric Schmidt, NYU professor Gary Marcus, and other leading voices have proposed a clear, testable definition for AGI — addressing a concept that has been both heavily discussed and notoriously vague.

- Paper Title: A Definition of AGI
- Full Text: https://www.agidefinition.ai/paper.pdf
This work introduces a measurable framework to eliminate ambiguity, defining AGI as an AI system matching or surpassing the cognitive breadth and proficiency of a well-educated adult.
---
Human Intelligence as the Benchmark
The paper grounds AGI testing in the only proven example of general intelligence — humans.
Human cognition is a complex combination of many evolved capabilities that enable adaptability and deep understanding.
To test whether AI matches this diversity and proficiency, the researchers build upon the Cattell-Horn-Carroll (CHC) theory of cognitive abilities — a well-established, empirically validated model based on more than a century of factor analysis of cognitive tests.
Framework Highlights:
- General intelligence is broken down into broad abilities and narrower sub-abilities (e.g., induction, spatial scanning).
- AI is assessed using human cognitive test structures.
- Performance is scored as a General Intelligence Index (AGI score) from 0%–100%.
- 100% score → fully human-level general intelligence.
---
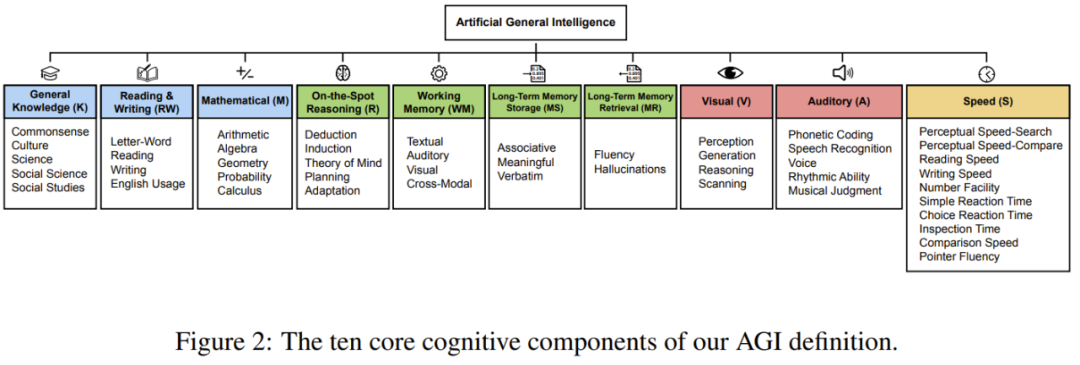
Ten Core Cognitive Abilities in the AGI Framework
The model identifies 10 equally weighted core cognitive components (each 10%), covering primary domains of human cognition:
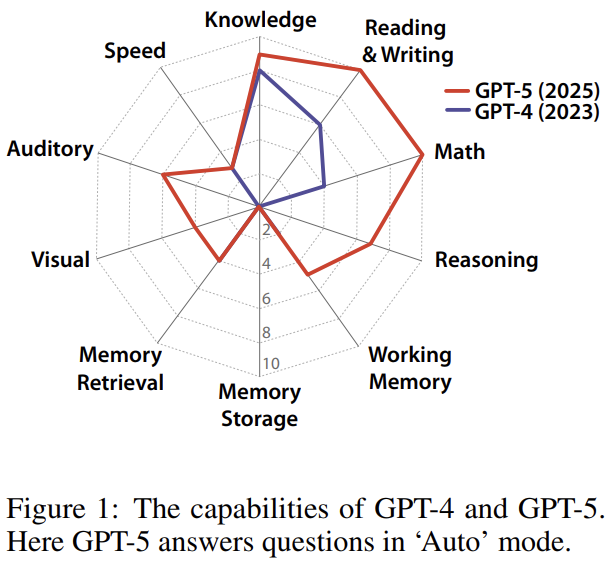
Below are the definitions along with GPT‑4 and GPT‑5’s performance visuals:
- General Knowledge (K) — Breadth of factual knowledge: common sense, culture, sciences, history.
- Reading & Writing (RW) — Understanding and producing written language: decoding, comprehension, and expression.


- Mathematical Ability (M) — Arithmetic through calculus, including probability and geometry.
- Fluid Reasoning (R) — Solving novel problems using deduction & induction beyond existing knowledge.


- Working Memory (WM) — Holding and manipulating current information in text, audio, and visuals.
- Long-Term Memory Storage (MS) — Sustained learning and retention: associative, semantic, literal memory.

- Long-Term Memory Retrieval (MR) — Efficiently accessing stored knowledge and avoiding “hallucinations”.
- Visual Processing (V) — Perceiving, analyzing, reasoning about, generating, and scanning visual info.


- Auditory Processing (A) — Recognizing and processing sounds: speech, rhythm, music.
- Speed (S) — Quick execution of simple cognitive tasks, perceptual speed, and processing fluency.


---
Findings on GPT‑4 and GPT‑5
Result: Across all abilities, GPT‑4 and GPT‑5 scores are below 10% in most areas, zero in some indicators — far from achieving AGI.

---
Key Insights & Bottlenecks
1. Jagged Capability Profile
Modern LLMs show extreme proficiency in data-rich domains (K, RW, M) but deep deficits in:
- Long-Term Memory Storage (MS)
- Certain multimodal reasoning skills (e.g., V).
2. “Capability Contortion” & Illusion of Generality
Models use strengths to mask weaknesses — e.g., large context windows (WM) to stand in for missing MS — leading to:
- Inefficiencies
- High computational costs
- Fragile performance
RAG (Retrieval-Augmented Generation) helps with MR issues but still:
- Avoids using the model’s own parameterized knowledge reliably
- Does not provide continuous, experiential memory.
3. Intelligence as an Engine
Overall “horsepower” is limited by the weakest component — even if others are highly optimized.
---
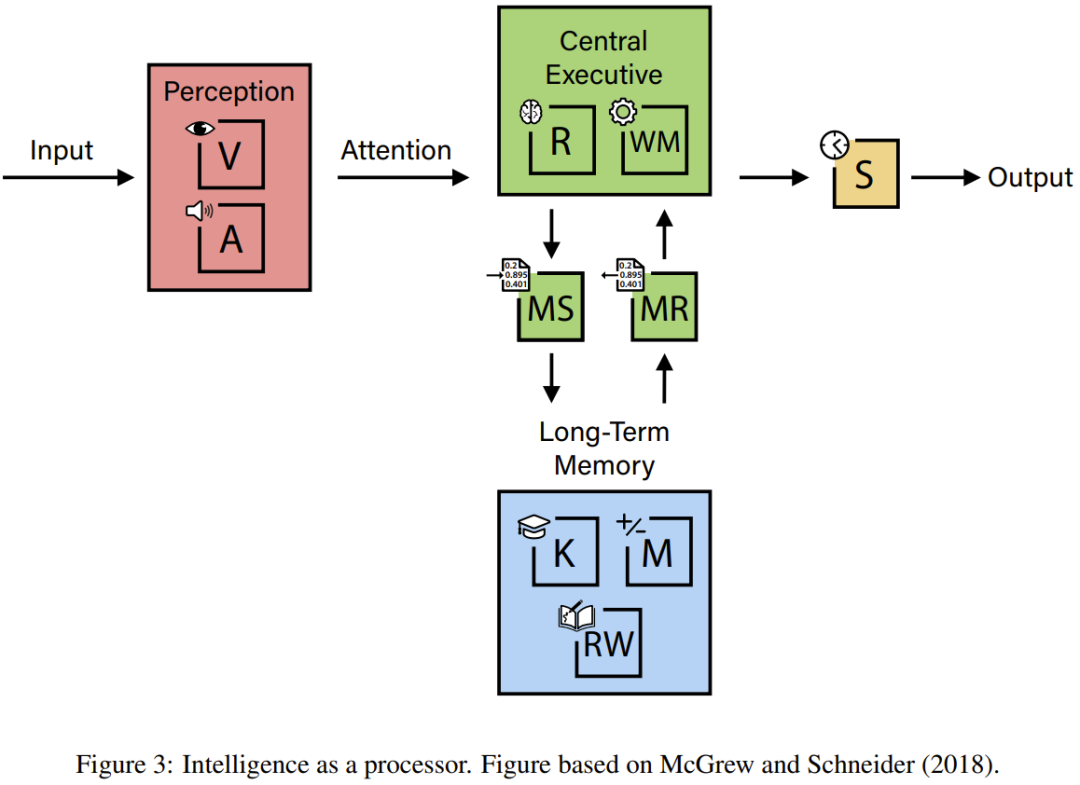
Interdependence of Abilities
Even though abilities are measured separately, real-world tasks almost always require combinations:
- Math problem solving: Mathematics (M) + Real-Time Reasoning (R)
- Theory of Mind: R + General Knowledge (K)
- Image Recognition: Visual Processing (V) + K
- Movie comprehension: Auditory Processing (A) + Visual (V) + Working Memory (WM)
---
Related Concept Definitions
- Pandemic AI: Can design/manufacture deadly contagious pathogens.
- Cyberwarfare AI: Plans/executes complex cyberattacks on critical infrastructure.
- Self-Sustaining AI: Operates & maintains itself long-term without assistance.
- AGI: Matches/surpasses breadth & proficiency of a well-educated human.
- Recursive AI: Can independently create advanced AI systems.
- Superintelligence: Exceeds human cognition in almost all domains.
- Replacement AI: Performs most tasks more efficiently, making human labor obsolete.
---
Major Obstacles to AGI
Examples of challenges:
- Abstract reasoning: ARC‑AGI challenge (R)
- World-model learning: Physical understanding tasks (V)
- Spatial navigation memory: (WM) challenge from World‑Labs
- Hallucinations: (MR)
- Continuous learning: (MS)
Conclusion: Reaching 100% AGI scores in the near term is highly unlikely.
---
Scope & Purpose of the Definition
The framework is:
- Not a fixed dataset or automated evaluator
- A task-based definition set that remains future-proof and flexible
- Focused on human-level core cognition, not physical skills or niche economic output.
---
Conclusion
This paper, involving leading AI experts, offers a clear, testable, and quantifiable AGI framework, grounded in the CHC theory of cognition.
Key outcomes:
- Ten core domains measured equally
- GPT‑4: 27% AGI Score
- GPT‑5: 58% AGI Score
- Large gaps remain — especially in memory and multimodal reasoning.
---
Practical Applications Today
While AGI is still far off, creators can leverage platforms like AiToEarn — enabling:
- AI content generation
- Cross-platform publishing
- Analytics
- Model ranking
Supported Channels: Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X.
Resources:
---
Bottom line:
The current path to AGI must address core cognitive bottlenecks rather than relying solely on scale or training data. Until then, frameworks like this provide a roadmap for tracking human-level AI progress while tools such as AiToEarn help put today’s AI to productive, monetizable use.