AEPO: Entropy-Balanced Strategy Optimization for More Stable Exploration and Deeper Reasoning
AEPO: Balancing Exploration and Stability in Agentic RL
In the rapidly evolving field of agentic reinforcement learning (RL), balancing exploration and training stability has become a central challenge in multi-turn agent training.
Mainstream entropy-driven RL approaches encourage models to explore uncertain reasoning paths, but excessive reliance on entropy can lead to unstable training or even policy entropy collapse.
---
Introduction to AEPO
The Gaoling School of Artificial Intelligence at Renmin University of China and the Klear LLM Team at Kwai have introduced Agentic Entropy-Balanced Policy Optimization (AEPO)—a novel RL optimization algorithm tailored for multi-turn agents, aiming for entropy balance.
Key contributions:
- Identifies two major issues:
- High-entropy rollout sampling collapse
- High-entropy gradient clipping
- Proposes two mechanisms:
- Dynamic entropy-balanced rollout sampling
- Entropy-balanced policy optimization
These innovations:
- Use entropy pre-monitoring & continuous branching penalties for adaptive exploration budget allocation.
- During policy updates, adopt gradient stopping & entropy-aware advantage estimation to preserve exploration gradients for high-entropy tokens.
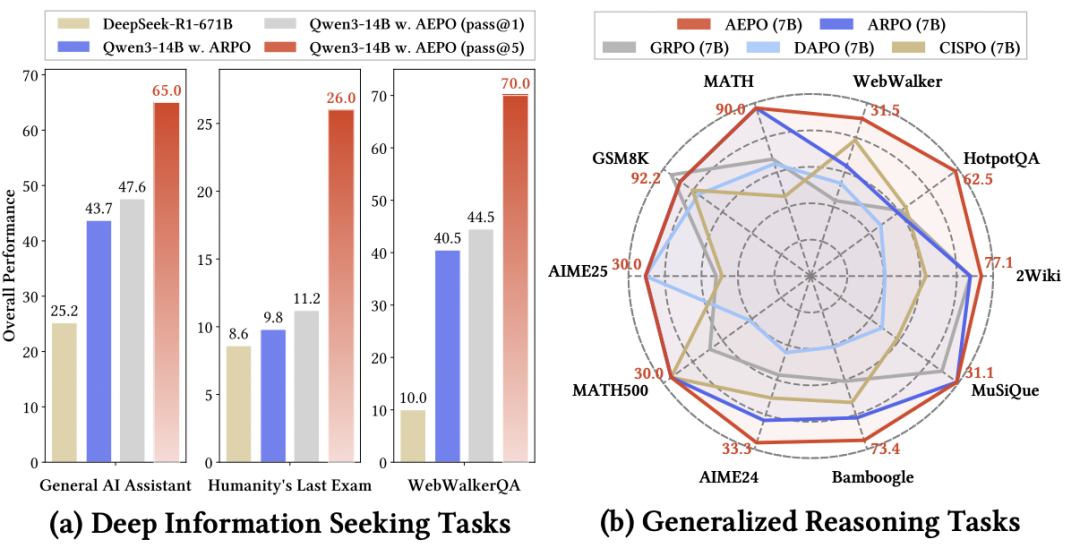
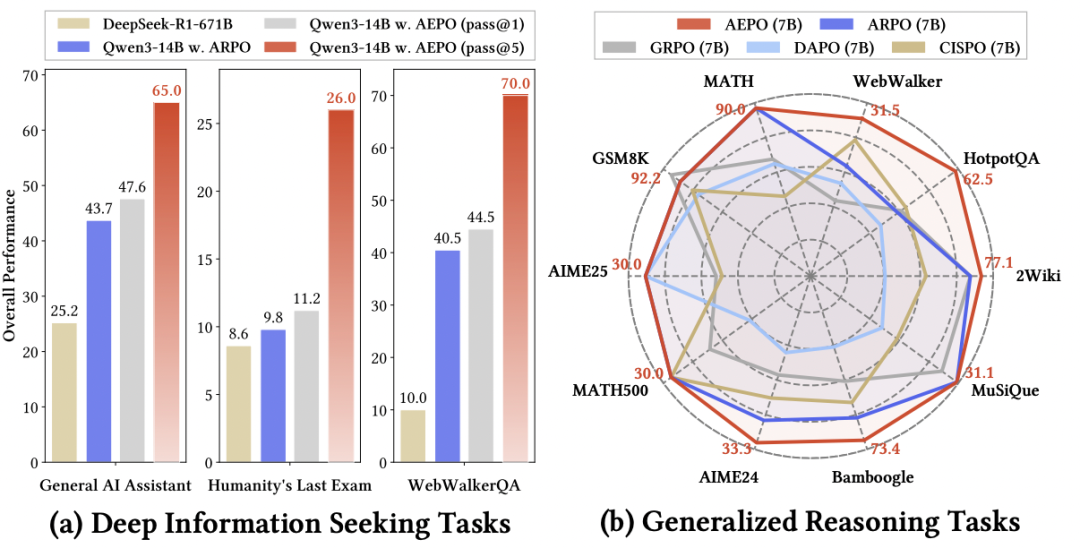
AEPO performance overview — left: deep search comparison; right: general reasoning comparison.
---
Highlights from Experimental Results
AEPO outperforms seven mainstream RL algorithms across 14 cross-domain benchmarks.
- Deep search task Pass@5 scores:
- GAIA: 65.0%
- Humanity’s Last Exam: 26.0%
- WebWalkerQA: 70.0%
- Gains in:
- Sampling diversity
- Inference efficiency
- Training stability

---
Paper: Agentic Entropy-Balanced Policy Optimization
AEPO has attracted major community interest — 700+ stars on GitHub and ranked #2 on Hugging Face’s daily paper list.

---
Motivation: Why Entropy Balance Matters
The Problem
Entropy-driven exploration improves diversity but causes instability:
- Over-branching in high-entropy tool-usage phases — limits exploration.
- Gradient clipping of high-entropy tokens — erases exploratory behaviour patterns.
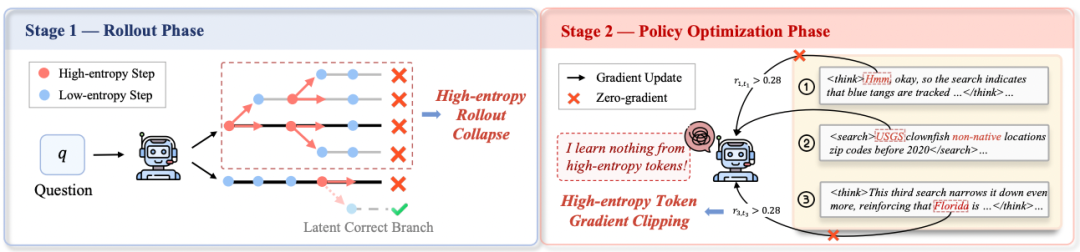
High-entropy rollout collapse and gradient clipping cases.
---
Core AEPO Contributions
- Systematic Analysis: Shows entropy-driven RL is prone to rollout collapse & gradient clipping in high-entropy phases.
- Algorithm Design:
- Dynamic Rollout Sampling based on information gain theory
- Entropy-Aware Policy Optimization that preserves exploration gradients
---
Observed Entropy Phenomena in Tool Invocation
Key issues found during token entropy and training process analysis:
- High-Entropy Continuity:
- Consecutive high-entropy tool calls found in 56.5% of steps; sometimes up to 6 in a row.
- Skews branch budget allocation.
- Uniform Gradient Clipping:
- Clipping without regard for exploration importance.
- Often affects prompts that trigger reasoning & tool usage.
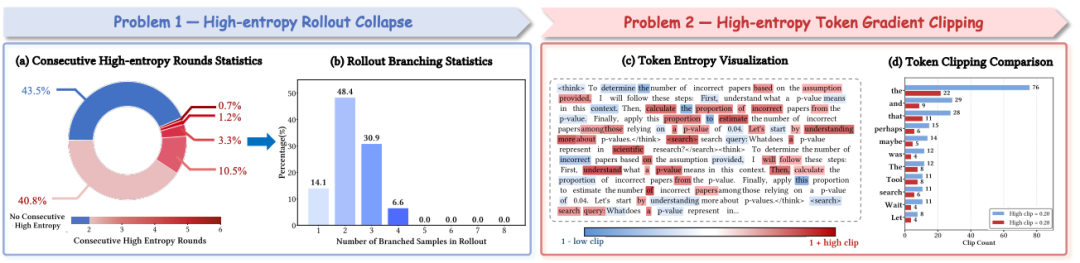
Quantitative statistics of entropy-related training issues.
---
AEPO Algorithm Overview
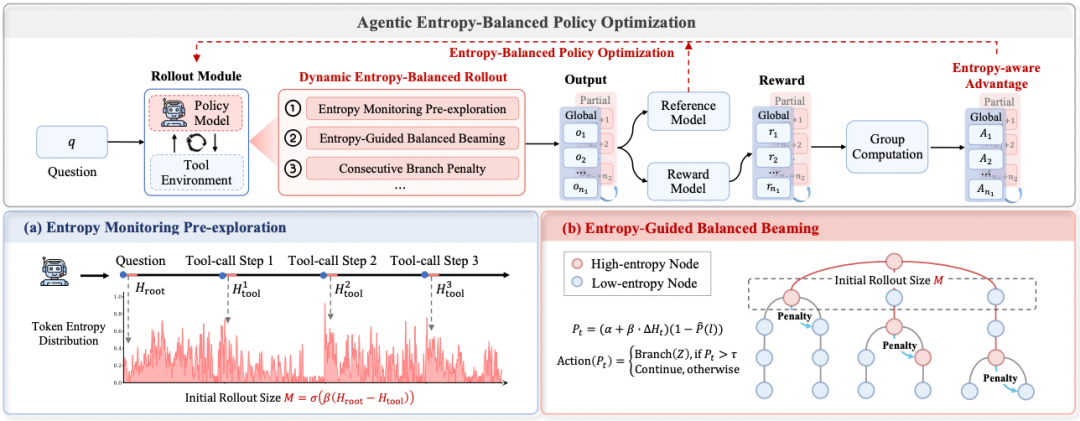
Two Major Components:
- Dynamic Entropy-Balanced Rollout Sampling
- Entropy-Aware Policy Optimization
---
1. Dynamic Entropy-Balanced Rollout Sampling
Entropy Pre-Monitoring
Allocate sampling budget based on initial problem entropy and tool feedback entropy:
Steps:
- Pre-generate trajectory to measure:
- Initial problem entropy !image
- Average tool invocation entropy !image
- If problem entropy > tool entropy:
- Increase global samples (m) for broader exploration.
- If tool entropy > problem entropy:
- Increase local branch sampling for targeted exploration.
- Use budget formula: !image
Continuous High-Entropy Branch Penalty
- Monitor entropy after every tool call !image
- Track continuous high-entropy branching count !image
- Adjust branching probability: !image
Result: AEPO samples all 8 budget trajectories, improving diversity from 54 to 62 clusters vs ARPO.
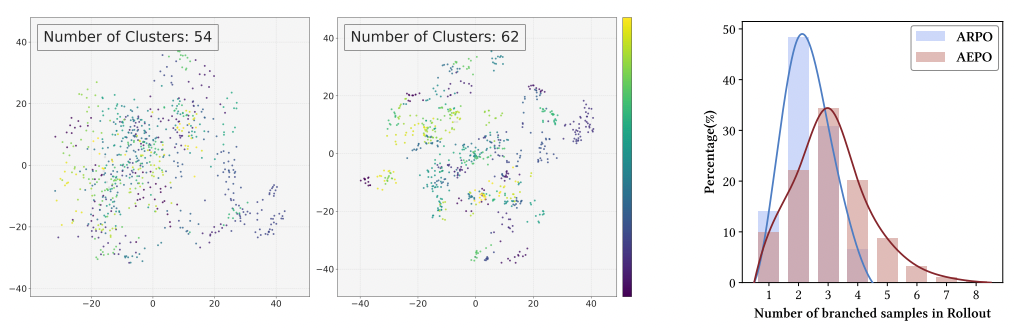
---
2. Entropy-Aware Policy Optimization
Gradient Preservation for High-Entropy Tokens
- Stop-gradient operation to protect gradients during clipping.
- Forward propagation remains intact; backprop keeps exploration gradients.
Formulas:
Entropy-Aware Advantage Estimation
---
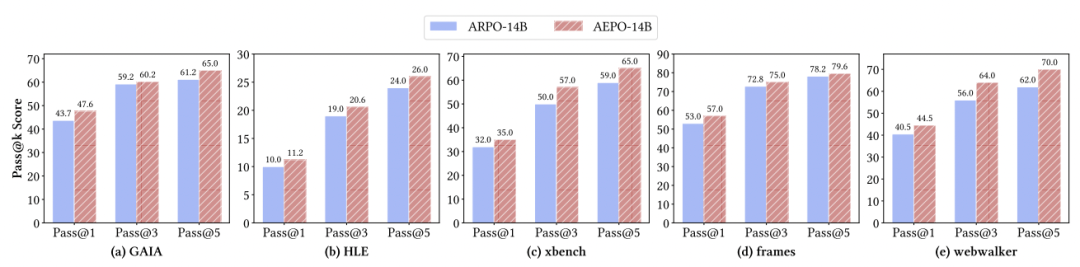
Benchmark Results
Test Categories:
- Computational reasoning: AIME24, MATH500, GSM8K...
- Knowledge-intensive reasoning: WebWalker, HotpotQA...
- Deep search tasks: GAIA, HLE, SimpleQA...
Key metrics:
- AEPO beats ARPO by +3.9% (Pass@1) and +5.8% (Pass@5)
- Stronger than gradient clipping RL by 7–10% on GAIA
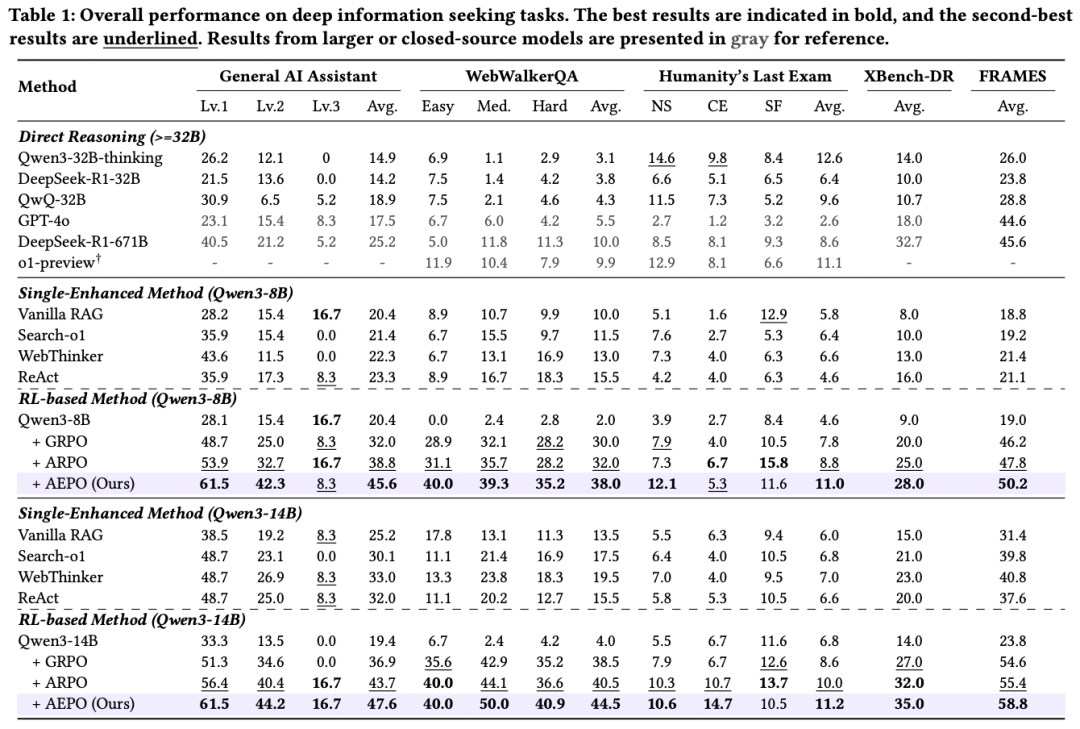
---
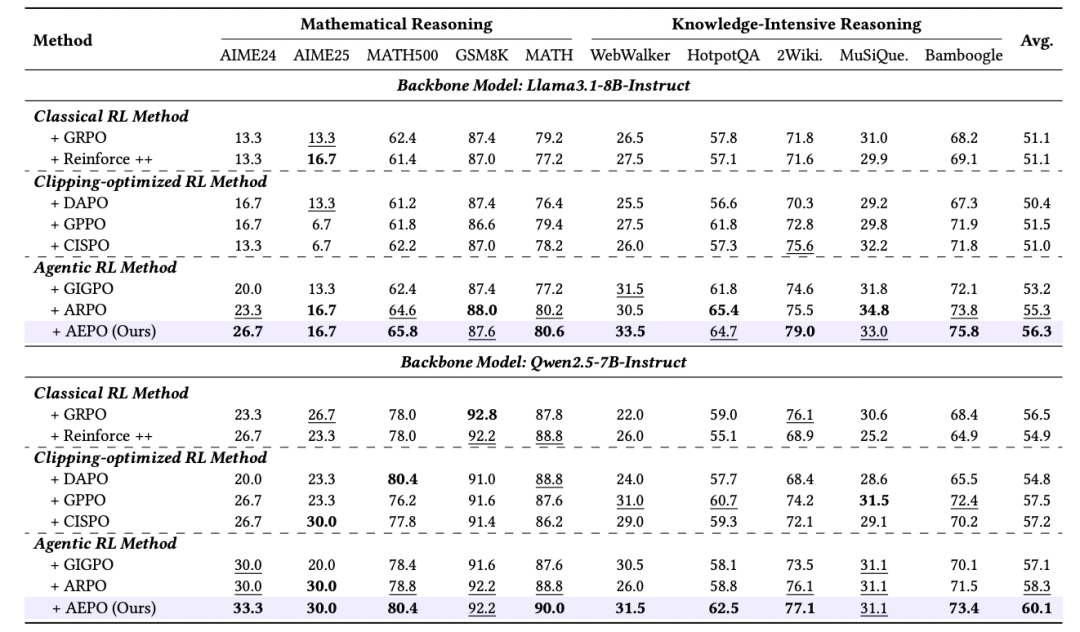
Generalization & Stability
- Gradient clipping methods falter across models and risk entropy collapse.
- AEPO shows consistent generalization and higher average accuracy (~5% over GRPO).
---
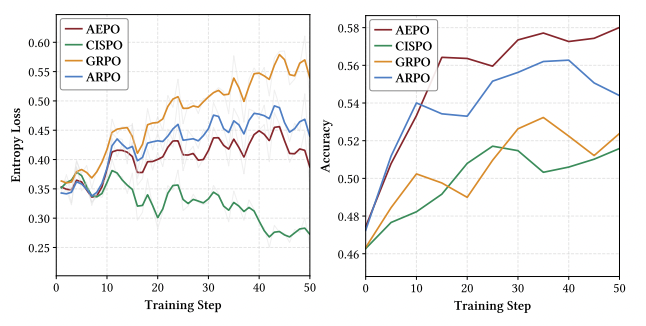
Training Analysis
AEPO maintains stable high entropy and steady accuracy gains throughout training, avoiding late-stage fluctuation issues of ARPO.
---
Future Directions
- Multimodal Agents: Extend AEPO to images, video.
- Expanded Tool Ecosystem: Integrate APIs, MCP services.
- Multi-Agent RL: Collaborative exploration and convergence.
---
About the Lead Author: Dong Guanting
- PhD student, Gaoling School of AI, Renmin University
- Research: RL for intelligent/deep search agents, large model alignment
- Publications: ICLR, ACL, AAAI
- Internships: Kuaishou KuaiYi LLM, Alibaba Tongyi Qianwen
Portfolio: dongguanting.github.io

---
Related Platform: AiToEarn
AiToEarn官网 is an open-source global AI content monetization platform — enabling creators to:
- Generate with AI
- Publish to platforms like Douyin, Kwai, Bilibili, YouTube...
- Access analytics & AI model rankings
It offers a bridge between AI research (like AEPO) and real-world content monetization.
---
References:



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}