AI Large Model-Based Fault Diagnosis and Root Cause Analysis Implementation
# I. Project Background Overview
## Digital Transformation Context
Enterprise digital transformation has entered **deep waters** — business systems are increasingly complex.
**Microservices**, **containerization**, and **cloud-native** architectures are now mainstream.
While they bring agility and resilience, they also introduce **unprecedented internal dependencies**.
A single user request may traverse **dozens or hundreds of services**, producing massive amounts of metrics, logs, and trace data.
---
## Why AIOps Is Now Critical
Under these conditions, AIOps has evolved from a *"nice-to-have exploratory tool"* to a **"must-have" necessity**.
This project applies **cutting-edge AIOps** to deliver **intelligent fault diagnosis** in core operations workflows.
---
## Core Project Goal
Build a **multi-agent collaborative AI system** that mimics human expert teamwork to automatically perform **Root Cause Analysis (RCA)** for IT system faults.
- Integrate with enterprise collaboration platforms (e.g., **WeCom / DingTalk**).
- Deliver the **analysis process & conclusions** in interactive, easy-to-understand formats.
- Reduce both **Mean Time to Detect (MTTD)** and **Mean Time to Repair (MTTR)**.
---
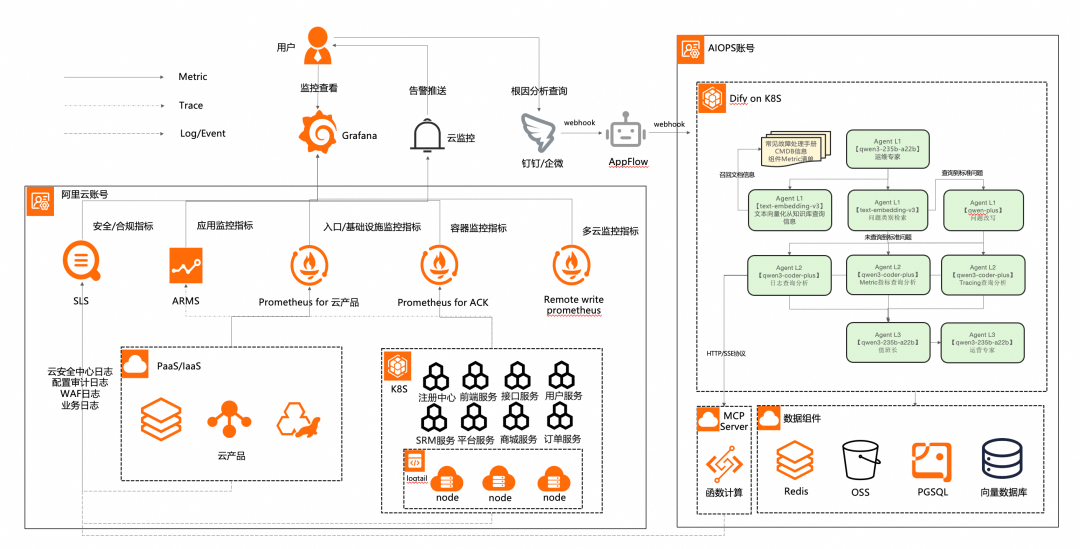
## System Overview
### 1. Data Ingestion
Real-time or near-real-time input from:
- **Metrics**:
CPU, Memory, Disk I/O, QPS, Latency, Error Rate — via Prometheus, Zabbix, Cloud Monitoring.
- **Logs**:
Application, System, Middleware logs — via ELK, SLS platforms.
- **Traces**:
Distributed tracing data — via ARMS to map request paths.
### 2. Multi-Agent Collaborative Analysis
**Specialized agents** with distinct roles:
| Agent | Responsibility |
|-------|----------------|
| Task Planning Agent | Defines RCA steps, coordinates tasks |
| Metrics Analysis Agent | Detects anomalies in metrics |
| Log Analysis Agent | Extracts error patterns from logs |
| Topology Awareness Agent | Understands system architecture and dependencies |
| Analysis Decision Agent | Synthesizes and judges evidence |
| Final Output Agent | Structures and delivers RCA results |
---
### 3. Interaction & Feedback
- Push results to Ops staff via **DingTalk bots** in card/Markdown/button formats.
- Allow **natural language interaction** with agents:
* e.g., “Show detailed evidence” / “Analyze root cause for App XXX at HH:MM”.
---
# II. Core Problems to Solve
### 1. Alert Storms and Information Overload
- **Problem**: Thousands of correlated alerts flood operators — hard to separate cause/effect.
- **Solution**: Alerts are **clustered, de-noised, correlated** — reducing to a small set of *fault events*.
### 2. Low Fault Localization Efficiency
- **Problem**: Troubleshooting relies on senior engineer **experience**, moving across multiple monitoring platforms.
- **Solution**: Agent integrates expert patterns and does **cross–data-source analysis** in minutes.
### 3. Data Silos
- **Problem**: Metrics/logs/traces are isolated in different systems.
- **Solution**: Agent **auto-correlates** via timestamps, TraceIDs, service names.
### 4. Rigid Incident Response
- **Problem**: Communication inefficiency due to fragmented info in ad-hoc channels.
- **Solution**: Agent acts as **incident response hub**, pushing structured reports.
### 5. Knowledge Retention & Reuse
- **Problem**: Fault-handling experience lost in private chats; repeated mistakes occur.
- **Solution**: Auto-archives RCA workflows into a **searchable incident case base**.
---
# III. Technical Architecture
Built on the **Dify** platform, the system implements **layered agent workflows**:
1. **Task Planning Layer** — generates RCA steps and dispatches tasks.
2. **Perception Layer** — integrates logs, metrics, traces, change events.
3. **Analysis & Decision Layer** — correlates multidimensional data, identifies root causes, proposes actions.
---
## Design Principle 1: Split Responsibilities, Transparent Workflows
- Multiple **specialized agents** instead of one monolithic AI model.
- Structured **JSON data exchange** between agents.
- Transparent inputs/outputs for **traceability**.
## Design Principle 2: Dynamic External Data Query
- Use **MCP services** to wrap monitoring tools & CMDB relationships.
- Large models can query latest data in real time.
- Decouples LLM from ops systems → **flexible, scalable**.
## Design Principle 3: Self-Iteration
- **ReAct pattern** orchestrates repeated tool calls and reasoning cycles.
- Drill down anomalies with multi-source correlation steps.
---
# IV. Building an RCA Knowledge Base
**Goal**: Transform a general LLM into a **domain-specific ops expert**.
### Knowledge Categories:
1. **Static System Knowledge**
- Architecture diagrams, service/component descriptions.
- Business processes & data flows.
- Infrastructure & configurations.
2. **Dynamic Runtime Data**
- Metrics (Golden, Resource, App-layer, Business).
- Logs (Errors, Critical Events, Key Patterns).
- Trace data (request path & timings).
- Change & Alert events.
3. **Historical Experience**
- Past RCA reports.
- Common issue Runbooks.
- Expert rules.
4. **Processes & Metadata**
- RCA SOP.
- Report templates.
- System glossary.
5. **Consolidation into Dify KB**
- Upload unstructured docs.
- Query real-time data via MCP.
- Separate KBs per domain.
- Preprocess for sensitive info removal.
6. **Strengthen RCA via Metric Relationships**
- Train agents to correlate metrics & detect true root causes.
- Temporal correlation, baseline comparison, config change association.
---
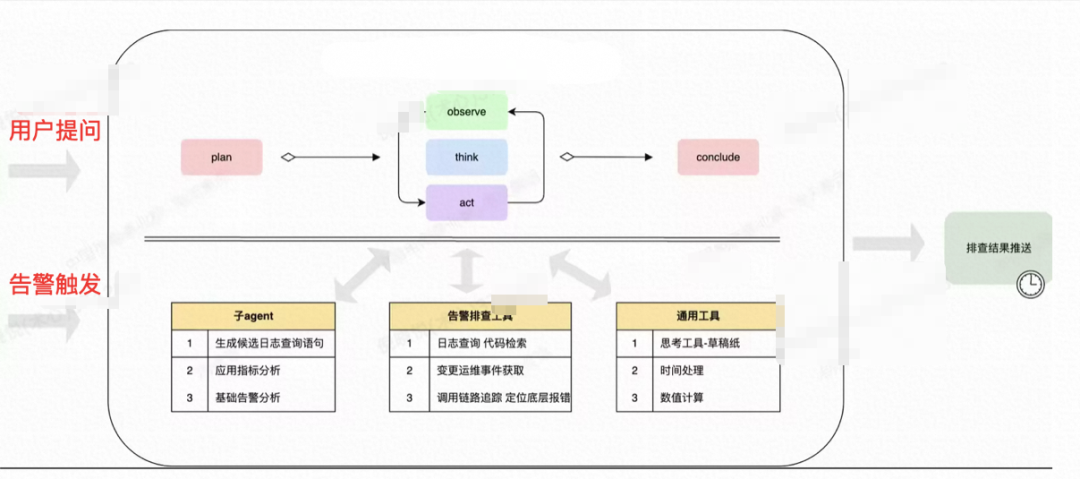
# V. Implementing RCA with ReAct Pattern
**ReAct = Reasoning + Acting**
Alternates *thought* and *tool invocation* until root cause convergence.
Example:
1. Initial hypothesis based on alert info.
2. Call Metric MCP → detect anomalies.
3. Reason cause → call Log MCP for errors.
4. Query CMDB and Trace MCP for dependency and bottleneck analysis.
5. Decision agent consolidates.


---
## ReAct Optimization
Challenges:
- Long workflow runtime
- Context loss risk
- Reduced reasoning with long contexts
- Poor loop termination detection
- Unstable output quality
Solutions:
- Limit unnecessary iterations.
- **Context compression** & precise evidence passing.
- Intelligent loop termination based on *evidence sufficiency*.
- Explicit, structured summarization before final output.
---
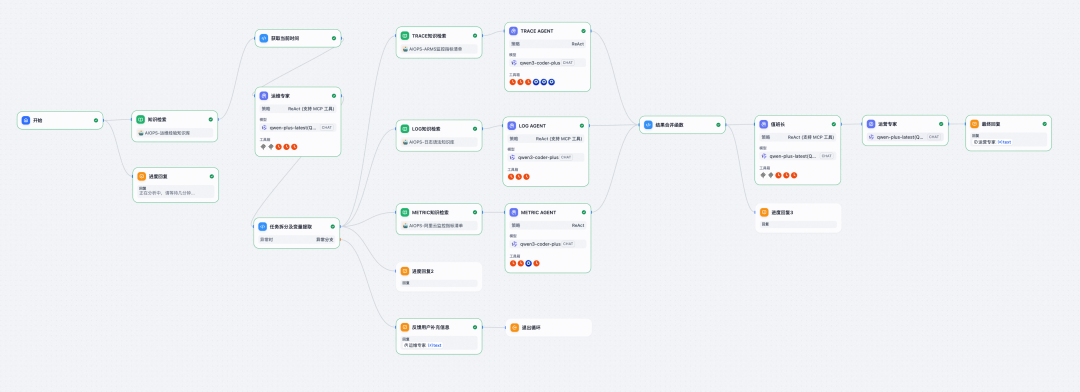
# VI. Dify Workflow Implementation
## Multi-Agent ReAct Flow
**Steps:**
1. User triggers alert → Ops Expert agent creates RCA plan.
2. Metric agent queries anomalies.
3. Log agent extracts error patterns.
4. Trace agent analyzes call chain.
5. Shift Leader agent reviews results.
6. Loop until stop conditions met.
7. Ops Specialist outputs **Incident Analysis Report**.
---
## Tool Interfaces
- **Alibaba Cloud OpenAPI MCP**:
[https://api.aliyun.com/mcp](https://api.aliyun.com/mcp)
- **Observability MCP**:
[https://github.com/aliyun/alibabacloud-observability-mcp-server](https://github.com/aliyun/alibabacloud-observability-mcp-server)
---
## Agent Output Standards
### Operations Expert Agent
- Parses alarm inputs.
- Generates RCA plan → metric / log / trace agents.
- Associates business context via CMDB.
### Trace Agent
- Queries ARMS MCP for application traces.
- Groups spans, identifies root cause spans with full error details.
- Outputs raw, untruncated diagnostic data.
### Log Agent
- Queries Aliyun SLS logs.
- Samples representative records.
- Summarizes key evidence.
### Duty Supervisor Agent
- Integrates evidence from all agents.
- Validates logical chains.
- Stops ineffective loops, prioritizes next steps.
### Operations Specialist Agent
- Summarizes incident into **structured final RCA report**.
---
# VII. Example Incident Analysis
## 1. Issue Summary
2025-09-15 10:30:45 — Severe timeouts accessing business domain.
**Root cause**: Abnormal WAF service node; DNS latency caused widespread disruption.
Affected: E-commerce Middle Platform, Customer Service System.
## 2. Impact Overview
- Duration: 84 minutes
- 0.0006% requests affected in critical business apps.
- Network timeouts on B-end systems (Collections, Telemarketing, CS).
## 3. Root Cause
- Hardware board failure in WAF cluster → DNS resolution delays → traffic impact.
## 4. Monitoring Findings
| Time | Active Conn. | Error Count | Notes |
|---------------------|--------------|-------------|--------------------------|
| 10:30 | 98 | 320 (499) | Load rising |
| 10:35 (**Peak**) | 100 | 580 (499) | Sustained > 5 mins |
| 10:40 | 99 | 450 (499) | Slow recovery |
Sample Log:2025-09-15 10:35:42 10.x.x.15 GET /loan/app/index - 499 Client Closed Request
---
## 5. Optimization Recommendations
1. Improve host health check alert thresholds.
2. Add alert on sharp error count spikes.
3. DNS failover mechanism to avoid single point issues.
4. Automate faulty node removal in WAF cluster.
5. Periodic failover drills for resilience.
---
# VIII. Conclusion
- RCA accuracy improved from **20% → 70%** after architectural and workflow optimizations.
- Planned next phase: deeper **model-level tuning**.
- Complementary usage of **open-source AI publishing tools** (e.g., [AiToEarn](https://aitoearn.ai)) can
ensure RCA reports are communicated across **internal & external platforms** effectively.
---

