Amazon SageMaker AI: Model Evaluation with Nova Evaluation Container
# Amazon Nova Model Evaluation in SageMaker AI — Comprehensive Guide
This blog post introduces the new [Amazon Nova model evaluation](https://docs.aws.amazon.com/sagemaker/latest/dg/nova-model-evaluation.html) features in [Amazon SageMaker AI](https://aws.amazon.com/sagemaker/ai/).
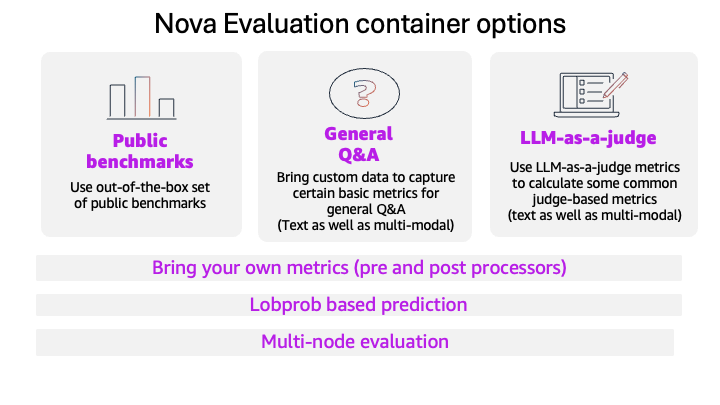
The release adds support for:
- **Custom metrics**
- **LLM-based preference testing**
- **Token-level log probability capture**
- **Metadata analysis**
- **Multi-node scaling** for large-scale evaluations
---
## 🚀 New Features Overview
### **Custom Metrics (BYOM)**
Bring-your-own-metrics functions let you define and control evaluation criteria tailored to your use case.
### **Nova LLM-as-a-Judge**
Handles subjective evaluations via pairwise A/B comparisons, calculates win/tie/loss ratios and Bradley–Terry scores, and provides explanations for each decision.
### **Token-Level Log Probabilities**
Shows model confidence at the token level — useful for calibration, routing decisions, and uncertainty management.
### **Metadata Passthrough**
Preserves per-row fields for analysis by segment, domain, difficulty, or priority — without extra preprocessing.
### **Multi-Node Execution**
Distributes workloads with stable aggregation, scaling evaluation datasets from thousands to millions of examples.
---
## 📈 Why It Matters
These capabilities make it simpler to design **robust, customizable** evaluation pipelines for generative AI projects.
Evaluation results can be integrated with [Amazon Athena](https://aws.amazon.com/athena/) and [AWS Glue](https://aws.amazon.com/glue/) or fed into existing observability stacks.
For publishing AI-generated content and monetizing it across multiple channels, open-source platforms like [AiToEarn官网](https://aitoearn.ai/) complement SageMaker workflows by enabling content distribution to Douyin, WeChat, Bilibili, Facebook, Instagram, LinkedIn, and more — with integrated analytics and [AI模型排名](https://rank.aitoearn.ai).
---
## 📋 Step-by-Step Demo — IT Support Ticket Classification
We’ll demonstrate:
1. **Set up evaluations**
2. **Run judge experiments**
3. **Capture & analyze log probabilities**
4. **Use metadata passthrough**
5. **Configure multi-node scalability**
---
## 🔍 Model Evaluation Essentials in SageMaker AI
To compare multiple models fairly:
- Use **identical test conditions** (same prompts, metrics, evaluation logic).
- Apply **baseline vs. challenger** tests under equal setups.
This standardization ensures score differences reflect **actual model performance**, not variations in evaluation methods.
---
## 🛠 Bring Your Own Metrics (BYOM)
Allows you to:
- Run **preprocessor functions** before inference to normalize or enrich input.
- Apply **postprocessor functions** after inference to assess outputs.
- Choose aggregation methods (`min`, `max`, `average`, `sum`) to weigh test cases differently.
By embedding metric logic in [AWS Lambda](https://aws.amazon.com/lambda/), evaluation aligns with **domain-specific goals**.
---
## 🎯 LLM-as-a-Judge Evaluation
### **How It Works**
- **Pairwise comparison** of model outputs for each prompt.
- Uses **forward and reverse passes** to counter positional bias.
- Provides **Bradley–Terry probabilities** with confidence intervals.
- Generates **natural-language rationales**.
Useful for:
- **Nuanced reasoning tasks** (e.g., support ticket classification).
- **Creative/multimodal content evaluation**.
---
## 📊 Token-Level Log Probabilities
**Benefits:**
- Calibration studies
- Confidence-based routing
- Hallucination detection
**Enable in config:**inference:
max_new_tokens: 2048
temperature: 0
top_logprobs: 10
Combining with **metadata passthrough** enables **stratified confidence analysis**.
---
## 🏷 Metadata Passthrough
Schema:{ "input": "...", "output": "...", "metadata": "custom_tag" }
Tracks model performance per:
- Category
- Difficulty
- Domain
- Priority
---
## ⚙ Multi-Node Evaluation
To scale:run:
model_name_or_path: amazon.nova-lite-v1:0:300k
replicas: 4 # 4-node scaling
Nova automatically distributes workloads and aggregates results.
---
## 🖥 Case Study: IT Support Ticket Classification
Categories:
- Hardware
- Software
- Network
- Access Issues
Evaluation checks:
- **Accuracy**
- **Explanation quality**
- **Custom metrics**
- **Log probability analysis**
- **Multi-node execution**
---
## 📂 Dataset Structure
Includes:
- Priority & difficulty metadata
- Domain category
- Ground truth outputs from **Amazon SageMaker Ground Truth**
---
## 🔑 Prerequisites
- AWS account
- IAM permissions for Lambda, SageMaker, S3
- Dev environment with SageMaker Python SDK & Nova Custom Eval SDK
---
## 🧾 Prompt & Response Example
**System Prompt:**You are an IT support specialist. Classify the ticket based on the description.
**Expected JSON Output:**{
"category": "",
"reasoning": "",
"confidence": ""
}
---
## 💡 Metadata-Enriched Dataset Example
{
"system": "You are a support ticket classification expert...",
"query": "...",
"response": "{\"class\": \"Hardware_Critical\", ...}",
"metadata": "{\"category\":\"support_ticket_classification\", \"difficulty\":\"easy\", \"domain\":\"IT_support\", \"priority\":\"critical\"}"
}
Benefits:
- Enables stratified performance analysis.
- Eliminates post-processing joins.
---
## 🧮 Custom Metrics via Lambda (BYOM)
1. **Upload Lambda Layer**:aws lambda publish-layer-version \
--layer-name nova-custom-eval-layer \
--zip-file fileb://nova-custom-eval-layer.zip \
--compatible-runtimes python3.12 python3.11 python3.10 python3.9
2. **Use Pre/Postprocessor Decorators**:from nova_custom_evaluation_sdk.processors.decorators import preprocess, postprocess
from nova_custom_evaluation_sdk.lambda_handler import build_lambda_handler
3. **Define Handlers** for:
- Input normalization
- Output parsing
- Custom metric computation
---
## 📈 Log Probability Calibration
Config:inference:
max_new_tokens: 2048
top_logprobs: 10
Use token-level log probabilities for confidence scoring & routing.
---
## 🔍 Low-Confidence Failure Analysis
Analyze:
- **Low Confidence Predictions** (confidence < threshold)
- **Overconfident Errors** (high confidence but poor quality)
Outputs actionable retraining targets.
---
## 🚀 Scaling Evaluations
Increase `replicas` in recipe → automatic horizontal scaling.
---
## ✅ Conclusion
You learned:
- Defining **custom metrics**
- Using **LLM-as-a-Judge**
- Enabling **log probabilities**
- Metadata passthrough for segment analysis
- **Multi-node scaling**
Start with the [Nova evaluation demo notebook](https://github.com/aws-samples/amazon-nova-samples/tree/main/customization/SageMakerTrainingJobs/patterns/02_NovaEvaluation).
---
For automated publishing & monetization of evaluated AI outputs, [AiToEarn官网](https://aitoearn.ai/) integrates generation, cross-platform publishing, analytics, and model ranking — reaching Douyin, Bilibili, Facebook, YouTube, LinkedIn, and more.
 **Tony Santiago** — AWS Partner Solutions Architect
 **Akhil Ramaswamy** — AWS Specialist Solutions Architect
 **Anupam Dewan** — AWS Senior Solutions Architect

