An Engineering Design Perspective on veRL and OpenRLHF
# Large Model Intelligence|Sharing
## Introduction
In **RL**, **distillation**, and other AI workflows, multiple models often need to **cooperate** — managing computation, data communication, and process control.
For example, in **PPO** (and its derivatives), you may need to coordinate up to *five types of modules*:
- **Actor**
- **Rollout**
- **Ref**
- **Critic**
- **Reward**
Each can take on one or more roles: *train*, *eval*, or *generate*.
In distillation, you might have multiple groups of Teachers and Students distilling collaboratively.
When using traditional **Pretrain** or **SFT** training setups — single-script, multi-process (`deepspeed` or `torchrun`) — flexible task scheduling and resource allocation become difficult.
**Ray’s** *remote asynchronous invocation* + *Actor abstraction* allow each module to have:
- Independent execution units
- Independent task-handling logic
This **decoupled architecture** fits scenarios of multiple models interacting frequently.
In this article, we examine **veRL** [1] and **OpenRLHF** [2] from three angles:
1. **Roles** of each module and their training/inference backends
2. Using Ray to **allocate** and **share resources** (colocate / Hybrid Engine)
3. **Data flow** and **control flow** — the full scheduling chain from distribution to execution
> Code links are provided; reading the actual code is highly recommended — *talk is cheap*, code reveals truth.
---
## 1. Ray Overview
### 1.1 Launching Ray
Ray supports many languages, but Python is most common.
- **Auto-cluster via Python**:import ray
ray.init()
This creates a **driver process** and a Ray cluster automatically.
- **Manual start via CLI**:ray start --head
Then attach via `ray.init(address="auto")`.
### 1.2 Execution Model
- Ray runs a **pool of resident processes** per node.
- `@ray.remote` turns a function/class into a schedulable **Task** or **Actor**.
- `.remote()` schedules them asynchronously — results retrieved via `ray.get()`.
- Arguments/returns are **serialized** into an **Object** stored in Ray’s **Object Store** — shared memory across all nodes.
- Use `ray.get(object_ref)` to retrieve and deserialize transparently.
---
### Example: Nested Actor Creation
import ray
ray.init()
@ray.remote
class ChildActor:
def do_work(self):
return "Work done by child"
@ray.remote
class ParentActor:
def create_child(self):
self.child_actor = ChildActor.remote()
def get_work(self):
return ray.get(self.child_actor.do_work.remote())
parent_actor = ParentActor.remote()
ray.get(parent_actor.create_child.remote())
print(ray.get(parent_actor.get_work.remote())) # Work done by child
✅ Actors can **create** and **invoke** other Actors
⚠️ No method inheritance between Actors — apply `@ray.remote` only to final classes.
---
## 2. Resource Scheduling in Ray
### 2.1 Basic Resource Allocation
When creating an Actor:
MyActor.options(num_cpus=2, num_gpus=1).remote()
If resources are insufficient, scheduling will wait — enforcing **exclusive** allocation.
### 2.2 Placement Groups
For fine-grained control, create **placement groups** and divide them into **bundles**:
- Enable **exclusive** or **shared** GPU/CPU allocation
- Adopted by both **veRL** and **OpenRLHF**
Example (from a distillation framework):
remote_ray_worker = ray.remote(
num_gpus=self.num_gpus_per_worker,
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=self.resource_group.ray_pg,
placement_group_bundle_index=worker_rank,
),
runtime_env={"env_vars": env_vars},
max_concurrency=2,
)(self.worker_cls).remote(...)
---
## 3. OpenRLHF — Engineering Analysis
Version: **v0.5.9.post1**
Ray-based training supports **PPO** + derivatives (REINFORCE++, GRPO, RLOO).
### 3.1 Key Modules
- **Actor**: Train (forward + backward, weight updates)
- **Critic**: Train + Eval (forward + backward)
- **Rollout**: Batch inference — needs Actor weight sync
- **RM/Ref**: Eval — forward only, no weight updates
### 3.2 Backends
- Train: **Deepspeed**
- Batch inference: **vLLM** (supports DP + TP)
⚠️ Precision mismatch between train vs inference engines — affects eval loss.
---
### 3.3 Resource Colocation
**Colocate = multiple Ray Actors share same GPU**.
Modes:
1. `colocate_actor_ref`
2. `colocate_critic_reward`
3. `colocate_all_models`
- Modules in same **placement_group** share GPU bundles
- Set fractional GPU allocation: `num_gpus_per_actor=0.2`
- Actor-Rollout colocation requires **CUDA IPC** for weight sync because NCCL cannot communicate between processes on the same GPU
---
### 3.4 Data/Control Flow
OpenRLHF has **distributed control** — coarse overview:
ActorGroup.async_fit_actor_model():
for ActorWorker:
PPOTrainer.fit():
bind Ref, Critic, RM workers
for episode:
sample_and_generate_rollout()
prepare_experiences()
store_in_replay_buffer()
train_actor_and_critic()
if colocated:
broadcast_weights_CUDA_IPC()
Actor Workers handle:
- Computation
- Data distribution
- Scheduling
➡️ Potential performance bottleneck.
---
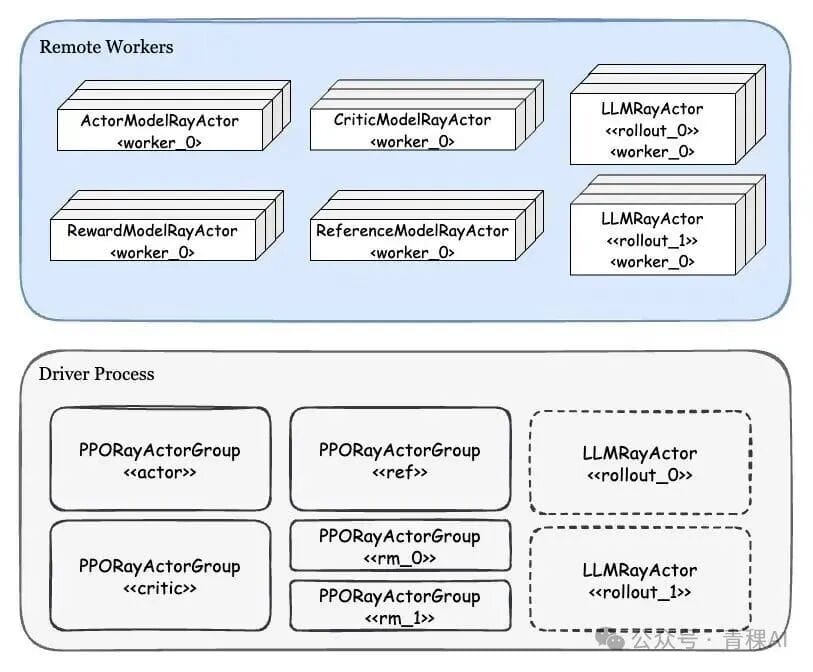
## 4. veRL — Engineering Analysis
Version: **v0.2.0.post2**
### 4.1 Key Traits
- **Single Controller** Actor (CPU) — centralized control
- Manages:
- Data/control flow
- WorkerDict creation
- Task scheduling
- Recommended: run controller on **non-head node**
### 4.2 WorkerDict
- Base Worker containing **all module types** (Actor, Critic, Rollout, Ref, Reward)
- Methods bound dynamically via `@register`
- Supports **Hybrid Engine**: same WorkerDict can switch between multiple backends
---
### 4.3 Scheduler
**RayWorkerGroup**:
- Retrieves resources
- Assigns modules to WorkerDict
- Dispatches tasks
- Collects results with pre-defined data distribution strategies
Colocation:
- Current code: **all modules colocated**
- Potential: arbitrary combinations (requires refactor)
---
### 4.4 Weight Sharing
veRL — Actor & Rollout share weights via `ShardingManager` (same process)
No CUDA IPC required.
Memory-efficient; potentially better performance.
---
## 5. Comparison & Summary
### Module Design
- **OpenRLHF**: separate modules per backend (simpler & clear)
- **veRL**: unified WorkerDict (flexible, supports multi-backend hybrid engines)
### Scheduling
- **OpenRLHF**: placement group per model; same-rank workers share bundles
- **veRL**: multiple modules in one WorkerDict share resources
Preferred: OpenRLHF’s clarity; veRL’s approach more complex but potentially more efficient.
---
### Control Flow
- **OpenRLHF**: control on Actor workers (can bottleneck)
- **veRL**: centralized in single controller (potentially better scalability)
---
### Performance Considerations
- Large tensor transfers via Ray Object Store → costly serialization/deserialization
- Optimization: use **NCCL/IPCs** + asynchronous pipelines (double buffering)
- Careful VRAM management needed
---
## References
1. veRL: [https://github.com/volcengine/verl](https://github.com/volcengine/verl)
2. OpenRLHF: [https://github.com/OpenRLHF/OpenRLHF](https://github.com/OpenRLHF/OpenRLHF)
3. Ray Tasks: [https://docs.ray.io/en/latest/ray-core/tasks.html](https://docs.ray.io/en/latest/ray-core/tasks.html)
4. Ray Actors: [https://docs.ray.io/en/latest/ray-core/actors.html](https://docs.ray.io/en/latest/ray-core/actors.html)
... *(see full original reference list for all links)*
---
**Final Thoughts**
Both approaches have trade-offs between **clarity**, **flexibility**, and **performance**.
Understanding Ray’s abstractions — Actors, Tasks, Placement Groups — is fundamental to building efficient, multi-model pipelines.