Analysis of Scaling Laws in Large Models: Concepts, Derivations, and Anti-Scaling Scenarios
Scaling Law Insights for Large Model Development
2025-11-09 00:30 · Jilin
This article consolidates and reflects on multiple readings about Scaling Laws — covering their concepts, derivations, and situations where anti-scaling effects emerge. Feedback and corrections are welcome.

---
Overview
Source: Zhihu
In large model R&D, common questions include:
- Model → Data: If I want to train a 10B parameter model, how much data is required at minimum?
- Data → Model: If I’ve collected 1T tokens of data, what size model should be trained?
- Compute Constraints: With 100×A100 GPUs and one month to train before launch, how should data size and model size be chosen for best performance?
- Scaling Up: If a 10B model underperforms, how much better will a 100B model be?
All of these can be addressed with Scaling Law theory. The following sections summarize key concepts, formulas, examples, and exceptions from published papers, adjusted for practical understanding.
---
1️⃣ Core Conclusions
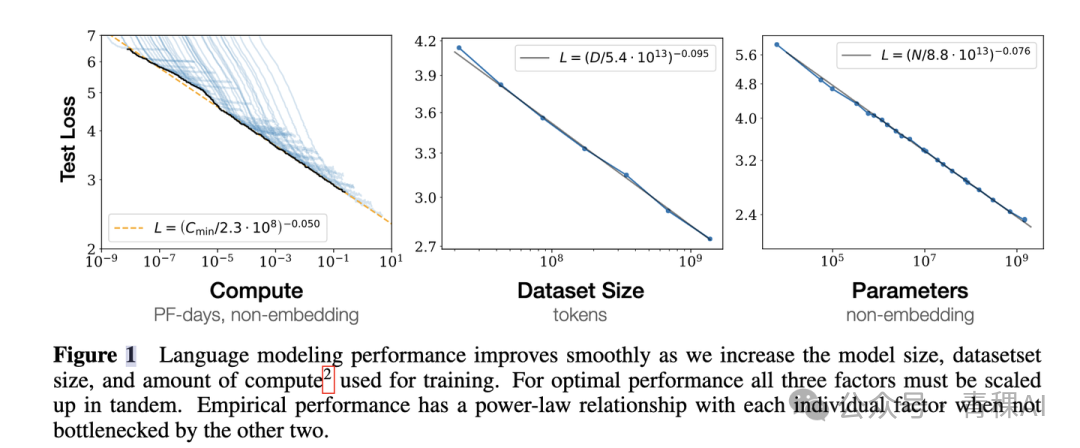
Scaling Law for large models was introduced by OpenAI (2020) [1]. In summary:
- Decoder-only scaling: Compute budget (FLOPs), parameter count \(N\), and dataset size \(D\) have a specific mathematical relationship (derivation in section 06).
- Architecture independence: Performance depends mainly on compute, \(N\), and \(D\), and is largely unaffected by depth/width variations.
- > With fixed parameters, varying depth/width changes performance by less than ±2%.
- Power-law gains: If compute, parameters, and dataset size are all scalable, performance follows a power-law relationship with each.
- Joint scaling: Model size and dataset size must grow together — though optimal ratios are still debated.
- Modal generality: Scaling Laws extend beyond language models to other modalities and cross-modal tasks [4].
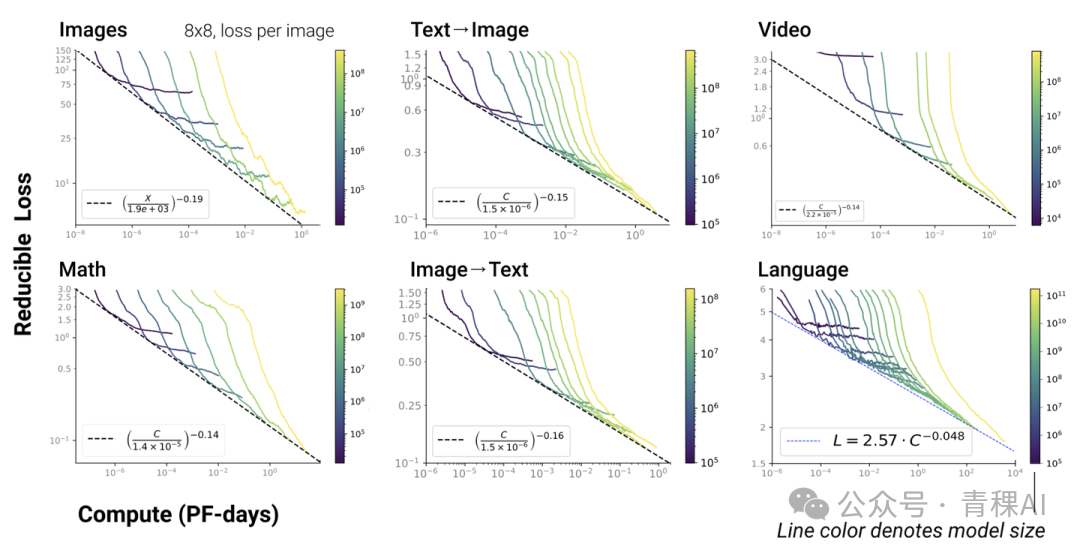
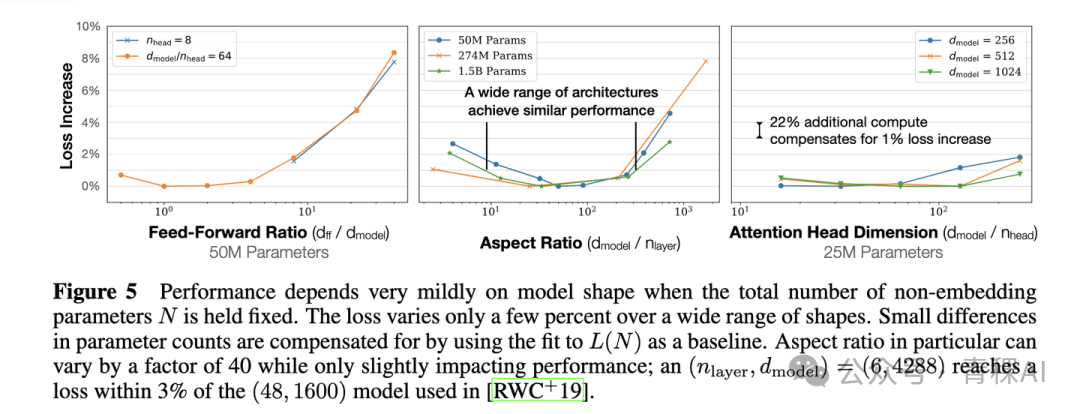
---
2️⃣ Core Formula

Interpretation:
- First term = data entropy (irreducible loss due to noise).
- Second term = loss reducible by more compute (model approximates data distribution).
Implication: Increasing compute \(x\) lowers total loss and boosts performance. As \(x \to \infty\), the model fits the true distribution, making the second term vanish.
---
3️⃣ Scaling Law in Major Models
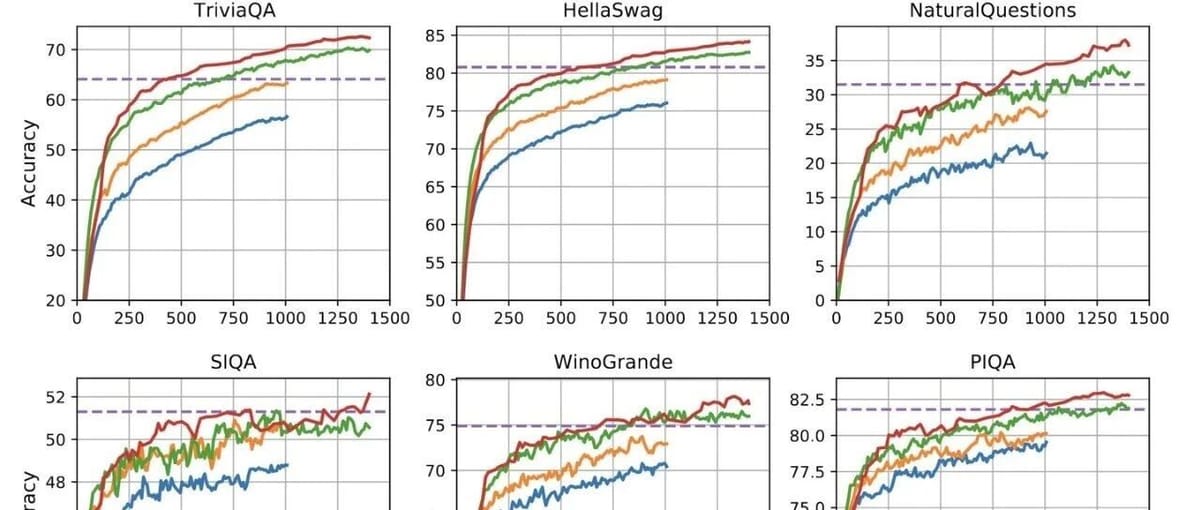
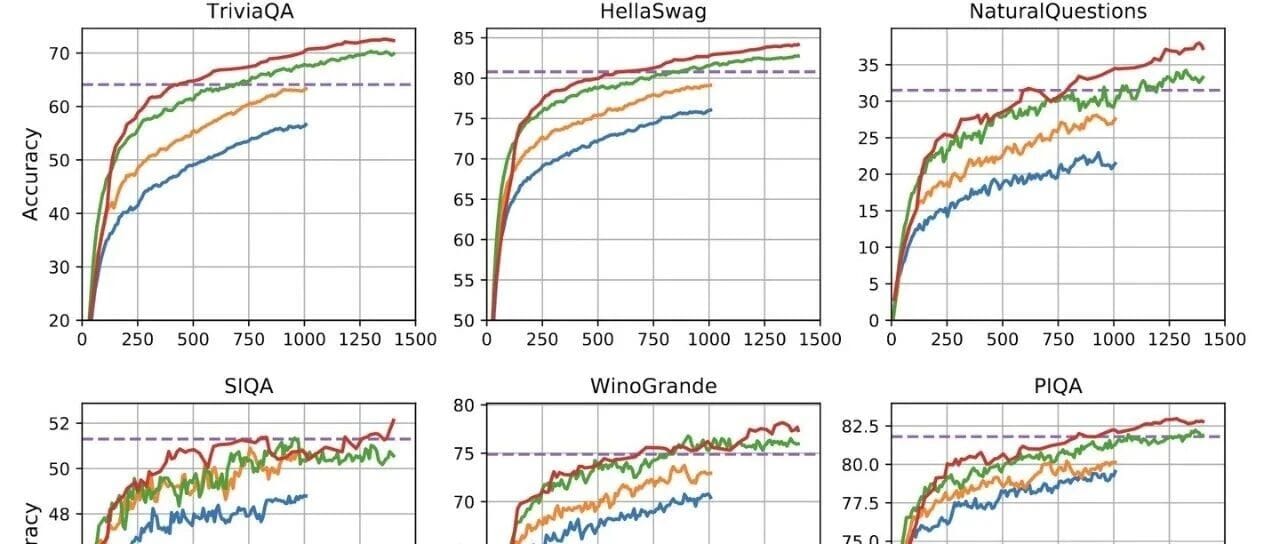
GPT‑4 Example
The GPT‑4 technical report [5] shows that performance scales with compute \(C\) via power laws.
Applications:
- Resource planning
- Performance forecasting when parameters or data size change
- Cross-platform AI integration (e.g., AiToEarn官网) to monetize AI-generated content while tracking scaling efficiency.

- Horizontal axis: Normalized compute (GPT‑4 load = 1.0).
- Vertical axis: Bits per word (cross-entropy). Lower is better.
---
Baichuan2
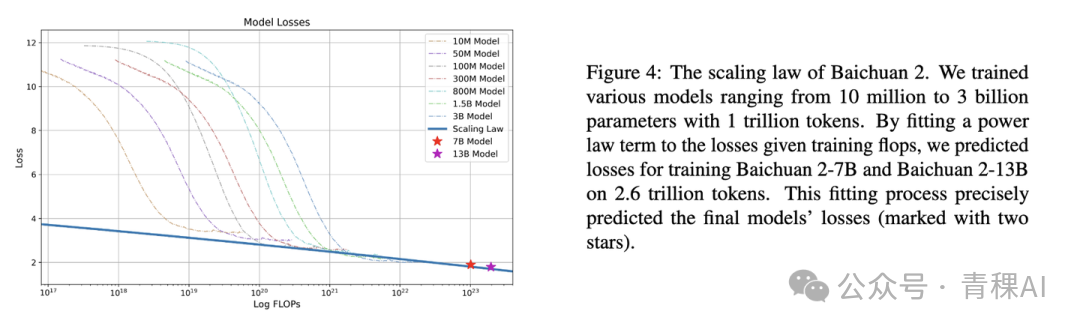
From Baichuan2 [6]: models 10 M–3 B params trained with 1 T tokens allow extrapolation to 7 B and 13 B models with 2.6 T tokens.
---
MindLLM

From MindLLM [7]: models 10 M–500 M params trained with 10 B tokens predict performance of a 3 B model trained with 500 B tokens.
---
4️⃣ Optimal Computational Efficiency
Key point: More data alone does not guarantee linear performance gains.
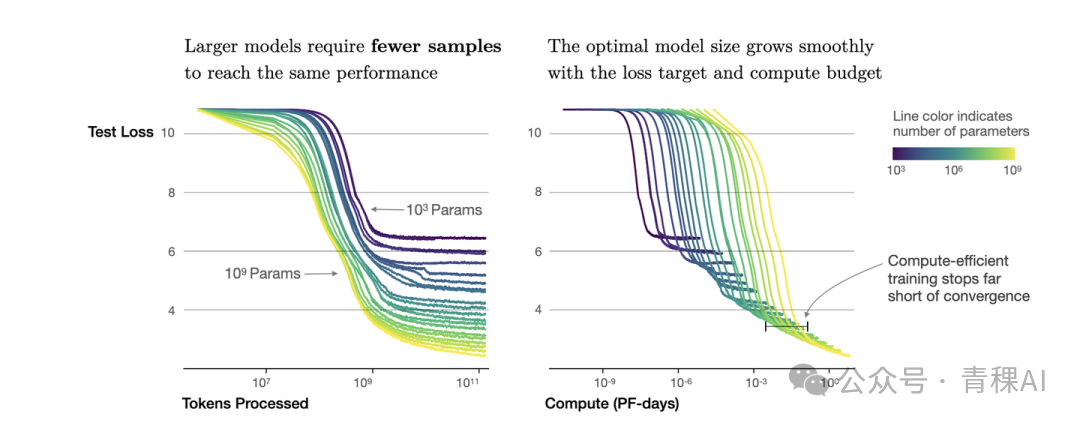
Purple line: Once parameters reach a certain point, the gain from adding more data diminishes sharply.
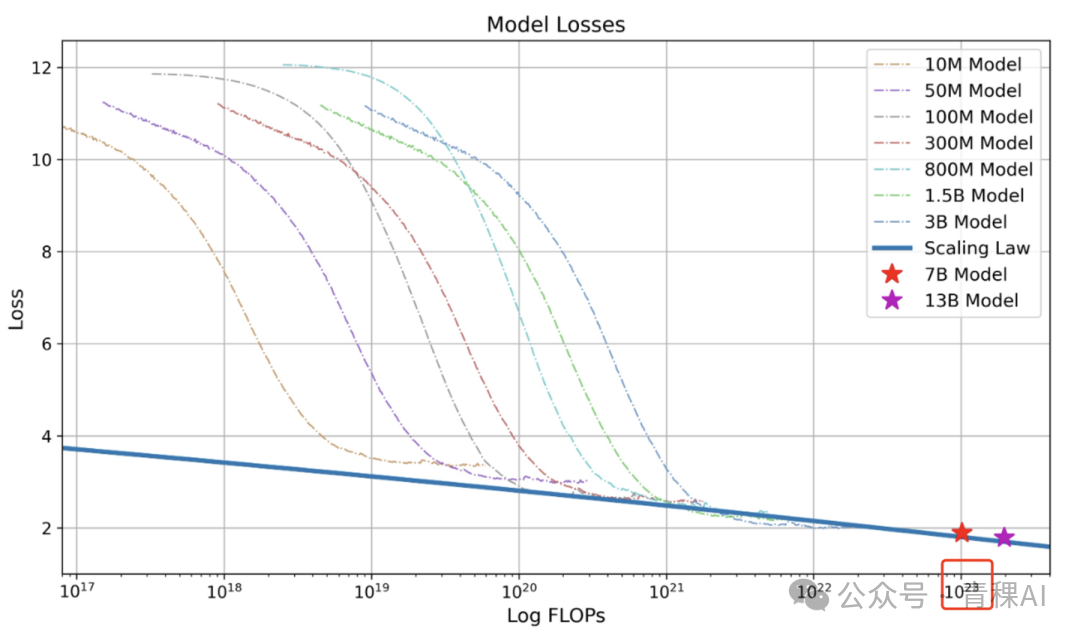
From Baichuan [6]: Convergence compute for 7 B model = FLOPs; dataset size = [omitted].
Practical approach:
- Gather a large dataset (~1 T tokens).
- Design smaller models with varying params (0.001 B–1 B).
- Train each to convergence.
- Record compute-vs-performance metrics.
- Identify optimal compute efficiency point.
- Derive scaling between:
- Model size ↔ Compute
- Dataset size ↔ Compute

- OpenAI: Params grow faster (focus on N).
- DeepMind/Google: a = b = 0.5 (equal importance to params and data).
---
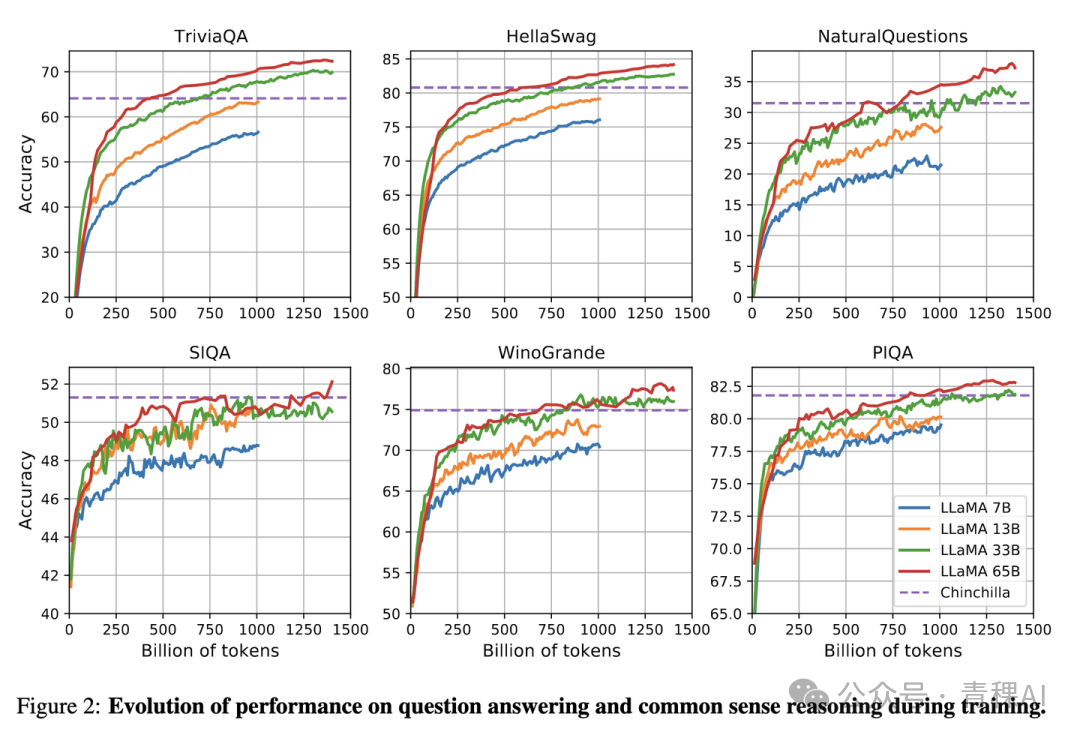
5️⃣ LLaMA: Defying Scaling Law
Meta's LLaMA [8] suggests: for lower inference costs, train smaller models with much larger datasets, even if this is suboptimal for training efficiency.

According to Scaling Law, a 10B model needs 200B tokens — but LLaMA shows a 7B model can keep improving beyond 1T tokens.
Practical tip: Monitor validation metrics during training; continue adding data as long as performance improves, regardless of theoretical minimums.
---
6️⃣ Deriving Compute–Model–Data Relationship
For decoder-only transformers, given:
- Layers \(l\)
- Hidden dim \(d\)
- FF dim \(d_{ff} \approx 4d\)
Parameters (no embeddings):
\[
N = l \cdot (4d^2 + 2d \cdot d_{ff})
\]
Compute per layer (forward pass):
\[
C_{\text{layer}} = 4bsd^2 + 4bs^2d + 4bsd\, d_{ff}
\]
- Backward pass ≈ 2× forward cost
- Training cost:
- \[
- C_{\text{total}} \approx 3 \times C_{\text{forward}}
- \]
FLOPs per token:
\[
\frac{C_{\text{total}}}{D}
\]
For dataset \(D\):
\[
C_{\text{training}} \approx 6l \cdot D \cdot (2d^2 + s d + d\, d_{ff})
\]
---
7️⃣ References
[3] Google PaLM
[6] Baichuan2
[7] MindLLM
[8] LLaMA
---
📢 Technical Community Invitation



Long‑press the QR to add assistant (WeChat).
Format: Name – School/Company – Research Direction – City
Example: Xiao Xia – Zhejiang University – Large Models – Hangzhou.
---
Recommended Reading:
- Latest Review: Cross-Language Large Models
- Stunning Deep Learning Papers
- Algorithm Engineer “Implementation Capability”
---
End of Document ✅
---
This rewrite improves consistency with clear headings, bold emphasis on key points, and grouped steps for practical application — while preserving all links, images, and technical fidelity.


