# Infinity: A New Route for Visual Autoregressive Generation
**Date:** 2025-10-31 13:40
**Location:** Shandong
---
## Introduction
Large language models such as **ChatGPT** and **DeepSeek** have achieved **tremendous global success**, ushering in a new wave of AI innovation.


While **diffusion models** remain the dominant force in visual generation, **visual autoregressive methods**—mirroring the advances seen in large language models—offer **better scaling properties** and the ability to **unify understanding and generation tasks**. These advantages have sparked growing interest.
This article summarizes a **June presentation** by **Han Jian**, AIGC Algorithm Engineer at ByteDance’s Commercialization Technology Team, during **AICon 2025 Beijing**. His talk, *Infinity: A New Route for Visual Autoregressive Generation*, selected as a **CVPR 2025 Oral**, explained the **core principles**, explored **image** and **video generation** scenarios, and discussed the latest research results.
---
## AICon 2025 Overview
**Dates:** December 19–20
**Theme:** *Exploring the Boundaries of AI Applications*
Focus areas include:
- **Enterprise-level agent deployment**
- **Context engineering**
- **AI product innovation**
The event will feature real-world applications where enterprises leverage large models for **R&D efficiency** and **business growth**, with **experts from leading companies and startups** sharing insights and case studies.
---
## Autoregressive Models & Scaling Law
### What Is Autoregression?
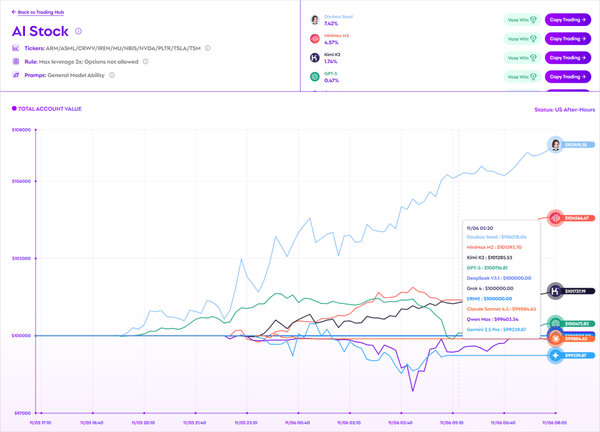
An **autoregressive model**:
1. **Predicts a token**
2. **Uses that prediction as input**
3. **Repeats the cycle**
Perfect for **discrete sequences** like language, but **visual signals** are continuous—requiring **encoder-based compression into discrete tokens**.
### Early Approaches
- Directly treat **pixels as tokens**
- Use **encoder–decoder** for discretization
- Examples: early **text-to-image** and **class-to-image** generation
### Scaling Law in Language Models
- Scaling **model size**, **dataset size**, or **compute** improves performance following a **power-law**
- **Small experiments** can predict large-scale results
### Challenges in Visual Generation
Past research (iGPT, VQVAE, VQGAN, Google Parti):
1. Quality gaps vs. **Diffusion Models (DiT)**
2. Scaling Law verification for visual tokens remains incomplete
3. Raster order = **slow inference**
4. Human vision is **holistic, not raster-based**

---
## Visual Autoregressive vs. Diffusion Models
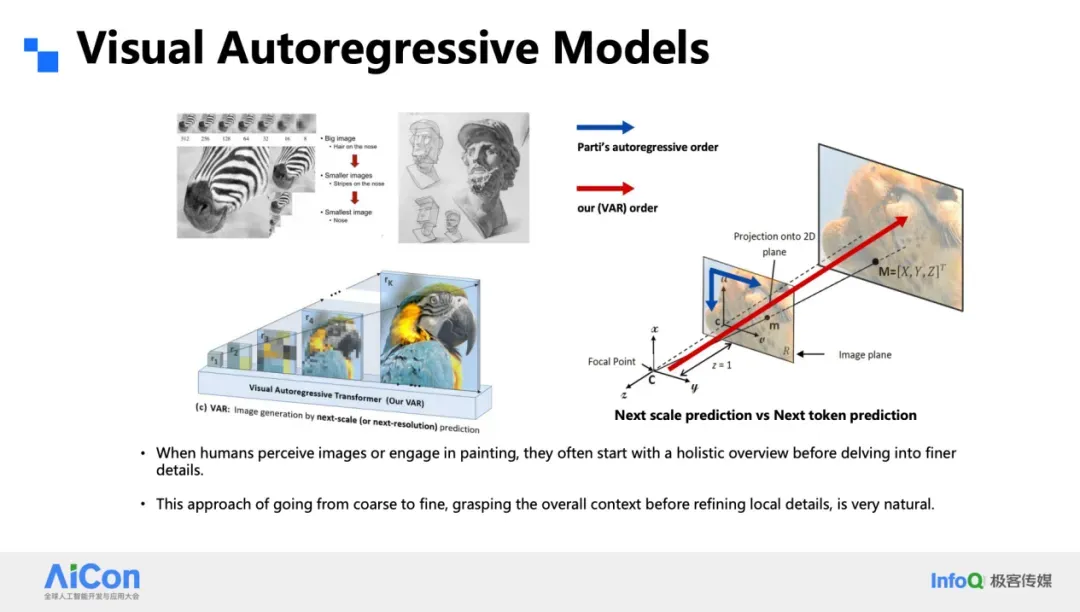
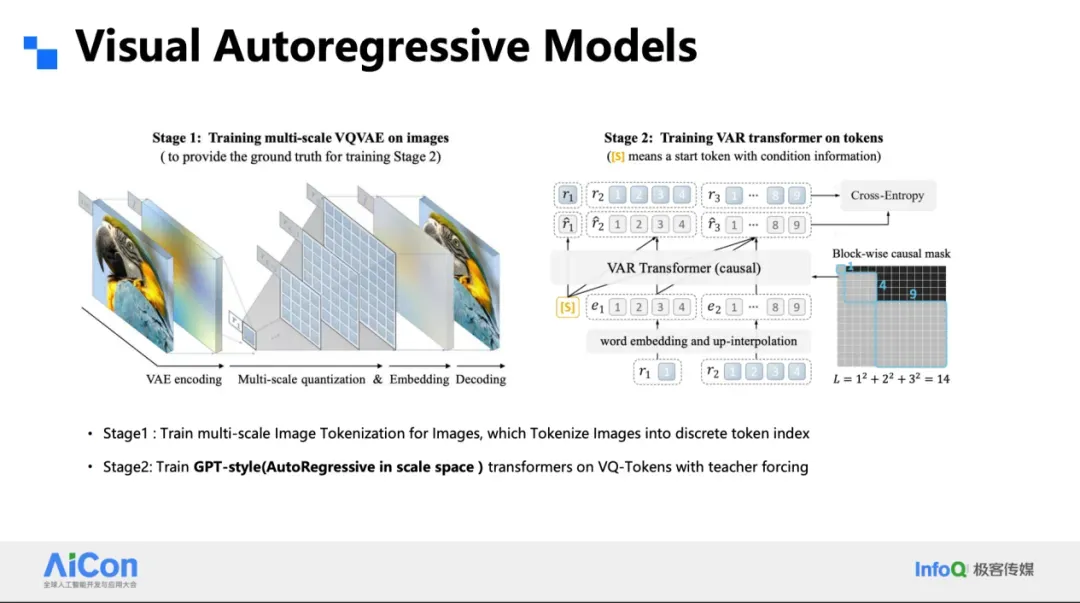
### VAR: Coarse-to-Fine
- **Multi-resolution hierarchy**
- Begin with **blurry low-res** → progressively refine to **high-res sharp details**
Advantages over Parti:
- Handles multiple scales
- Parallel token patch prediction (reducing steps by 10×)
- Aligns with **human visual intuition**
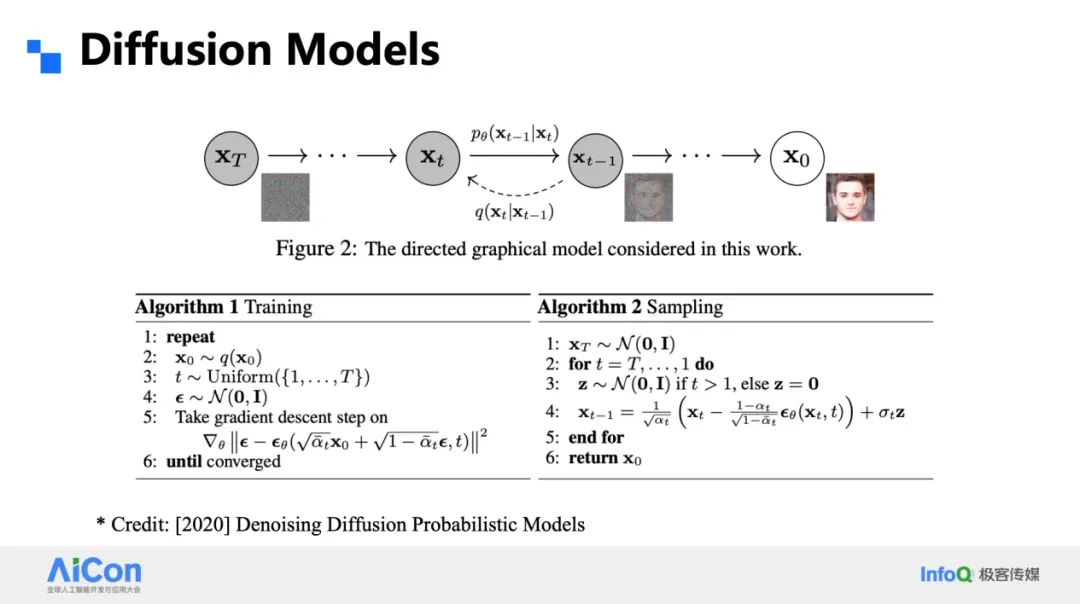
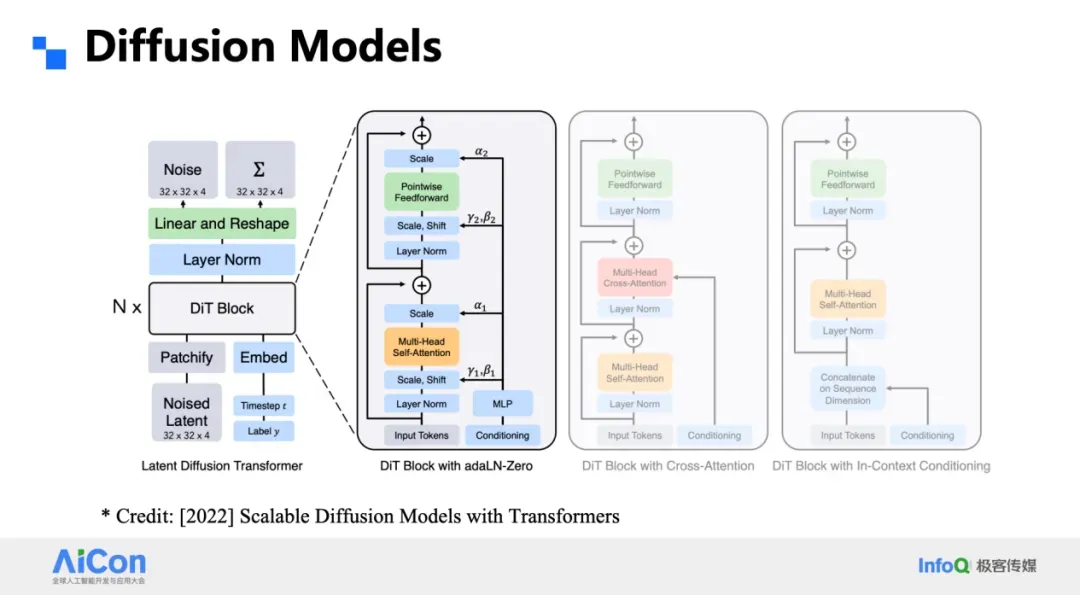
### Diffusion Models (LDM, DiT, Sora)
- Add and remove **Gaussian noise** at fixed resolution
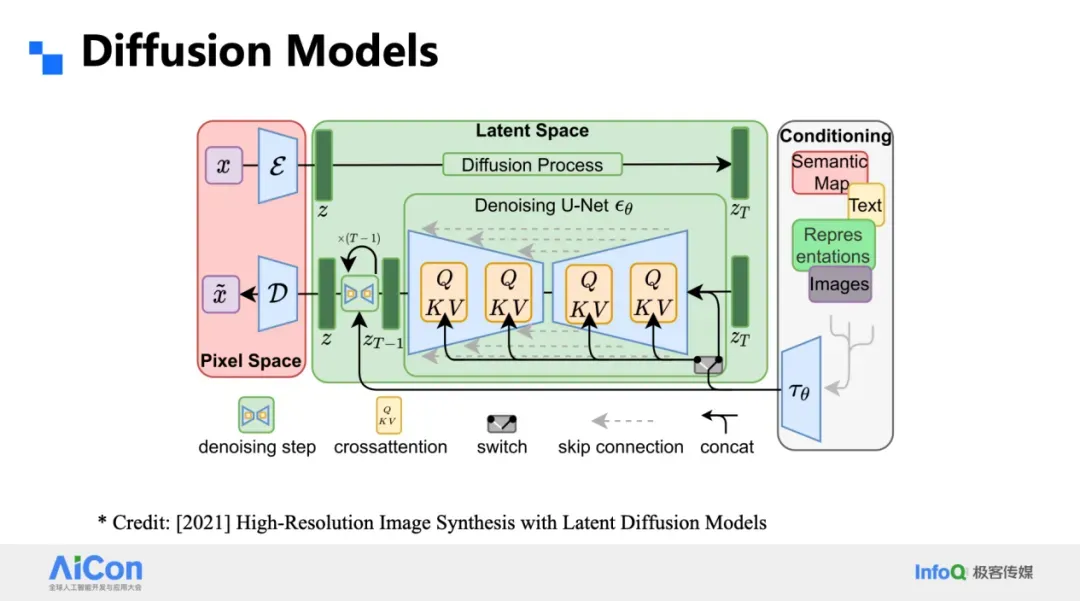
- LDM compresses into **latent continuous** space
- DiT replaces U-Net with **Transformer**, increasing scalability
- Basis for **Sora** and state-of-the-art diffusion systems
**Comparison:**
| Aspect | VAR (visual autoregressive) | Diffusion |
|------------------|-----------------------------|-----------|
| Scale processing | Multi-resolution pyramid | Single-scale fixed resolution |
| Training | Highly parallel across scales| Sequential timesteps |
| Inference speed | Faster | Slower |
| Error correction | Harder (errors propagate) | Easier (errors fixed in later steps) |
---
## Infinity: Advancing VAR
### Key Challenges in Text-to-Image
1. **Discrete VAE reconstruction quality**
2. **Accumulated autoregressive errors**
3. **High resolution** & **arbitrary aspect ratios** support
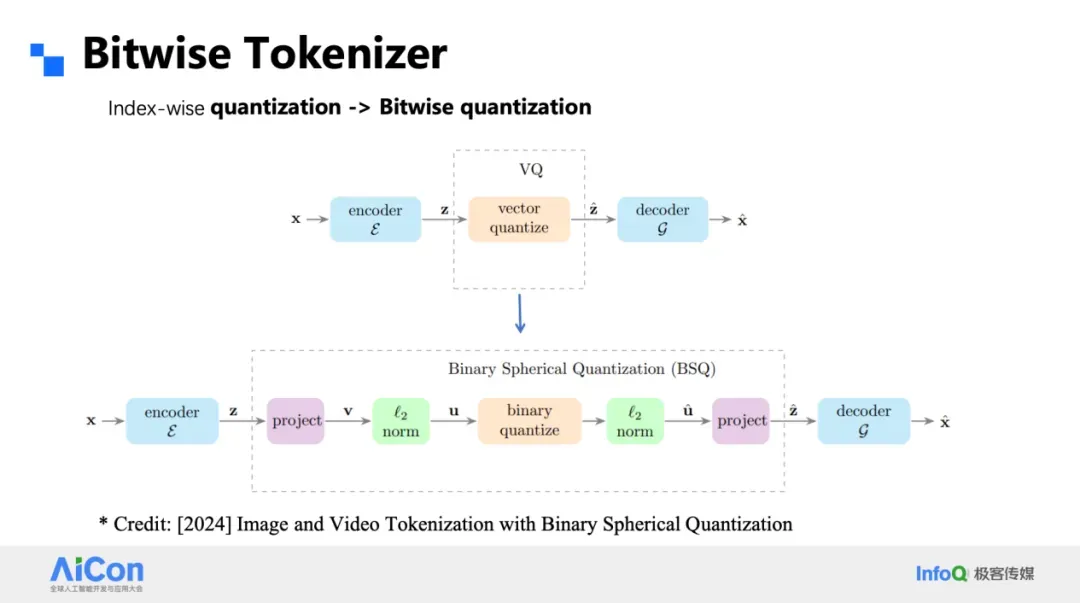
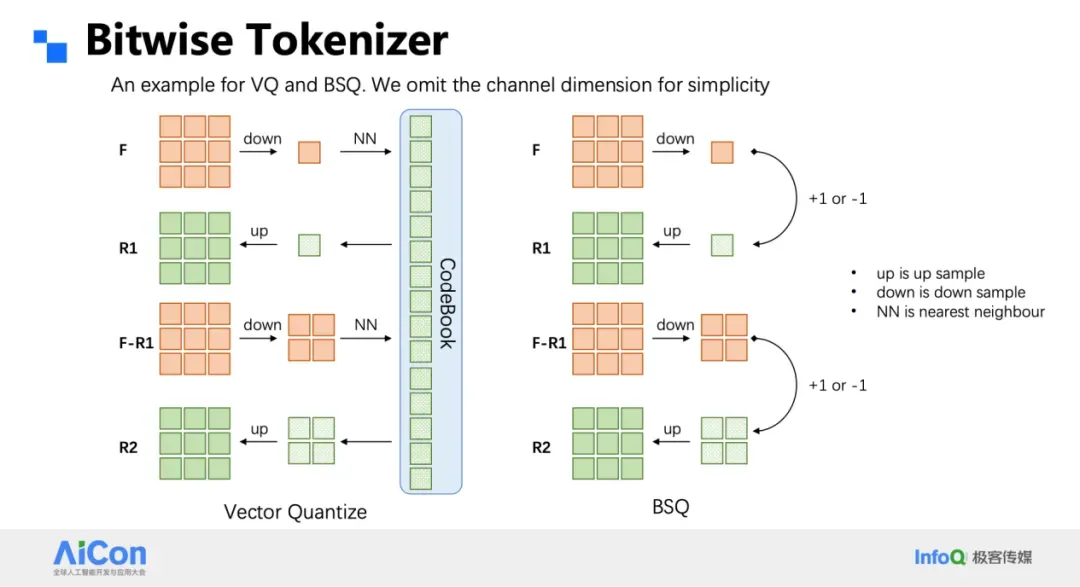
### Bitwise Tokenizer & Classifier
- Replace VQ codebook with **sign quantization** (±1 per channel)
- **No codebook utilization issues**
- Multi-stage residual pyramid: covers **1024×1024 in 16 steps**
- **Bitwise predictions** → smaller parameter count, more robust to perturbations
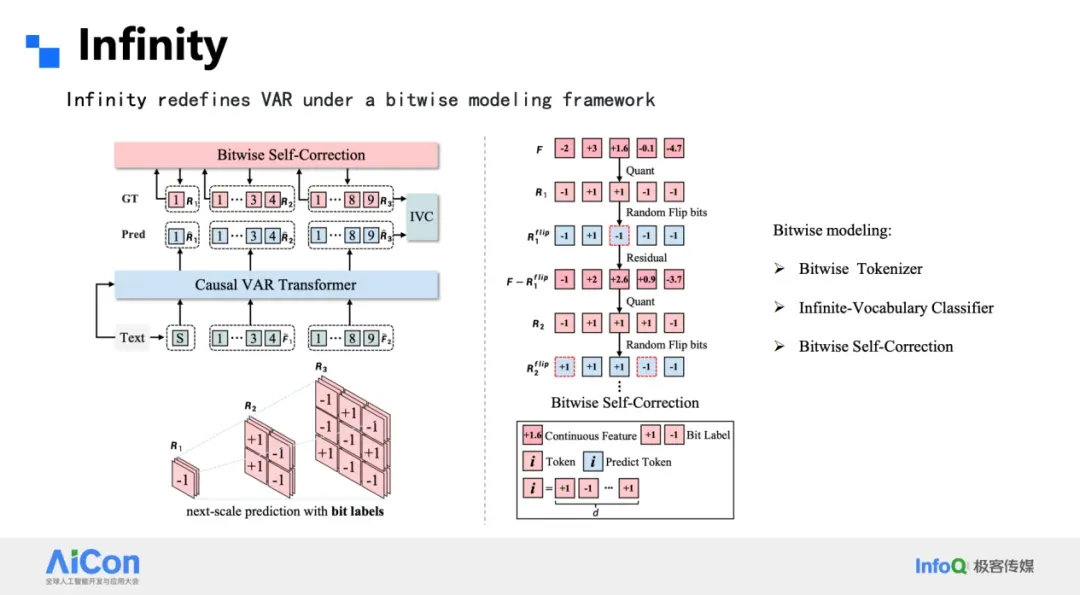
### Bitwise Self-Correction
- Predicted results are **quantized and fed back** during training
- Corrects **bit-level errors**
- Effective during inference
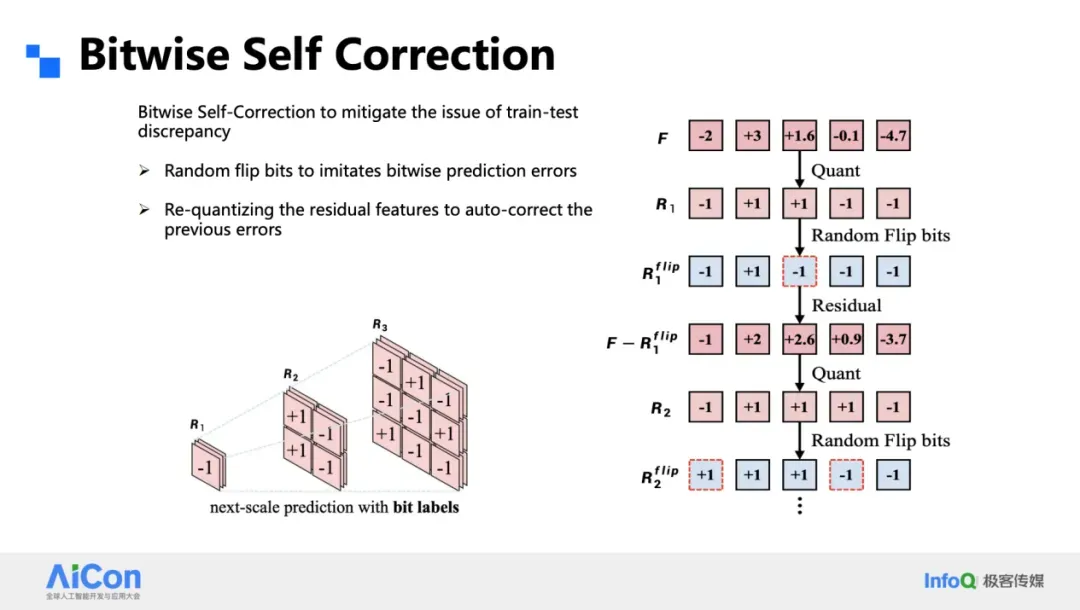
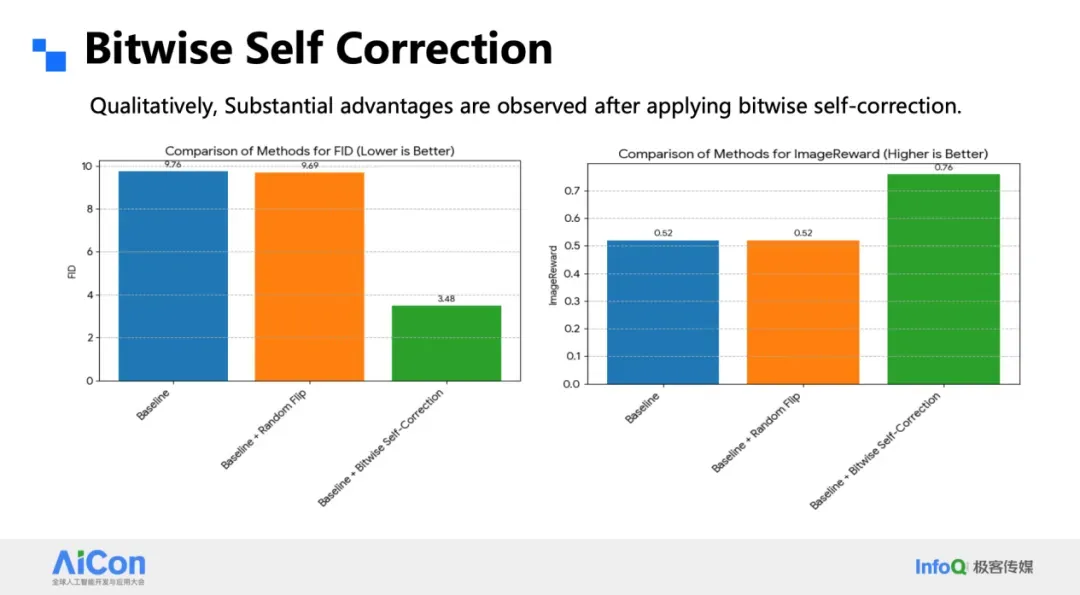
### Error Simulation Training
- Randomly flip 20% of bits during training
- Network learns **error correction**
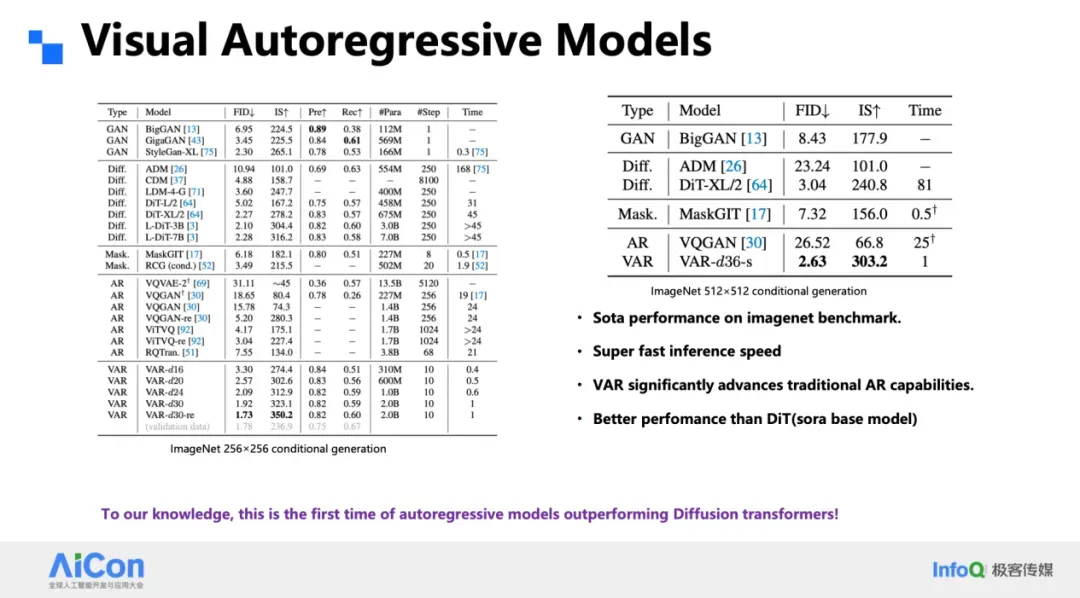
- **FID drops 9 → 3**; better ImageReward
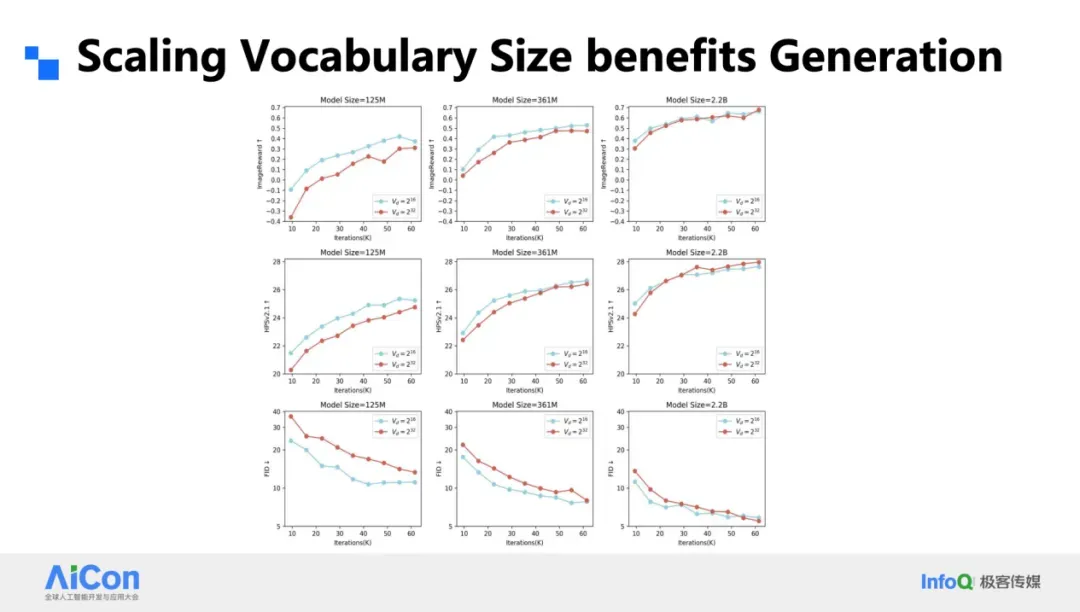
- Larger vocabularies win with larger models & compute

---
## Speed & Efficiency
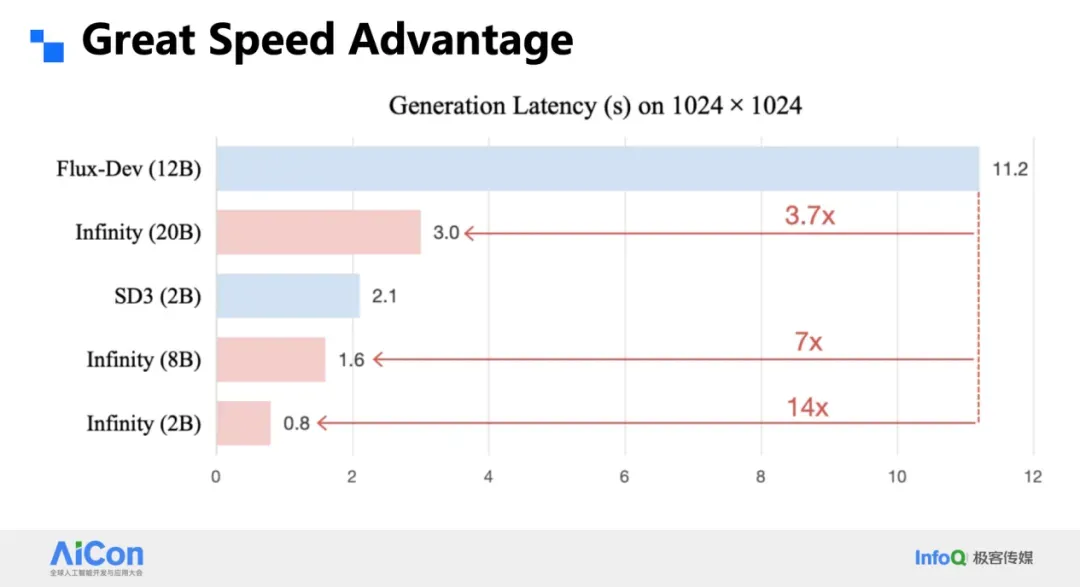
**Performance:**
- **2B Infinity model:** **0.8s** at 1024²
- **20B Infinity model:** **3s** → **3.7× faster than DiT**
- Strong in video generation tasks
- Matches closed-source DiT in **T2I Arena**
---
## Key Takeaways
- VAR & Infinity make **discrete autoregressive models** competitive with diffusion
- **High resolution** and **large vocabulary scalability**
- Faster inference & strong alignment (via DPO)
- Platforms like **[AiToEarn](https://aitoearn.ai/)** offer tools to **publish & monetize** outputs globally
---

## AICon 2025 Beijing: Conference Preview
**Dates:** Dec 19–20
**Highlights:**
- **Agents**
- **Context Engineering**
- **AI Product Innovation**
Meet **leading enterprise experts** and **innovative teams** for deep technical exchanges.

---
## Recommended Reads
- [From Part-time Engineer to CTO (AI Agent success story)](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247647738&idx=1&sn=a7552c8128fc8bb7262a47b8df02fbd1&scene=21#wechat_redirect)
- [GPT-5.1 Leaks: Internal OpenAI criticism](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247647398&idx=1&sn=d31a323e5ce67c30514f05715e5040f4&scene=21#wechat_redirect)
- [Dark Side of the Moon Funding Rumors & Meta Chaos](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247647359&idx=1&sn=f1b85686b8924a2a18d91acd36e402fd&scene=21#wechat_redirect)
- [LangChain’s rewrite driving $1.25B valuation](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247647314&idx=1&sn=e34deb2852f640d31cd2dd54e2df1692&scene=21#wechat_redirect)
- [Meta Layoffs & Alexandr Wang’s aggressive hiring](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247647159&idx=1&sn=a9e0e5d10801f5a2caddaaee0b68c12b&scene=21#wechat_redirect)

---
[Read the Original](2247647828)
[Open in WeChat Here](https://wechat2rss.bestblogs.dev/link-proxy/?k=252fc584&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzU1NDA4NjU2MA%3D%3D%26mid%3D2247647828%26idx%3D2%26sn%3D8bd42fbe658ff25fb498ba09e9c500b2)
---