Another Path for Visual Generation: Principles and Practices of the Infinity Autoregressive Architecture

Visual Autoregressive Methods: Unlocking the Potential of Unified Understanding & Generation
Visual autoregressive methods, with their superior scaling properties and ability to unify understanding and generation tasks, hold immense potential for the future of AI.


---
From Language to Vision: A Shift in Approach
Large language models like ChatGPT and DeepSeek have achieved groundbreaking success, inspiring a new wave of AI innovation. In visual generation, however, diffusion models still dominate.
By following the same technical route as language models, visual autoregressive (VAR) methods promise:
- Better scaling characteristics
- A unified framework for understanding + generation tasks
- Increased interest from both research and industry
This article, adapted from an AICon 2025 Beijing talk by a ByteDance AIGC algorithm engineer, explores these methods through the Infinity framework, covering:
- Foundational principles of autoregressive vision generation
- Application scenarios: image generation & video generation
- Latest experimental results and reflections
---
Autoregressive Models & the Scaling Law
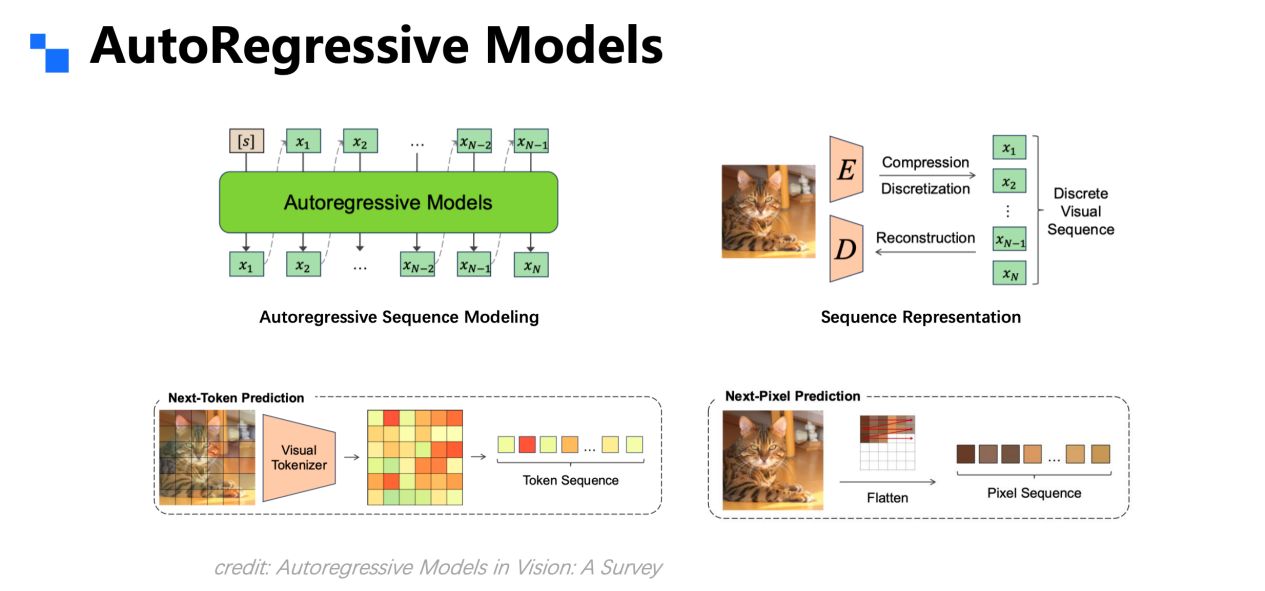
What Is Autoregression?
An autoregressive model predicts the next token using its previous predictions iteratively — a natural fit for discrete language sequences.
Visual signals, however, require transformation into discrete tokens via:
- Encoder – compresses image data
- Decoder – reconstructs compressed data
- Conversion of continuous pixels into discrete sequences
Early visual autoregression followed two main approaches:
- Pixel-as-token
- Encoder–decoder with discretization before next-token prediction
Understanding the Scaling Law
Scaling laws show that increasing model size, dataset size, or compute resources (while holding the others constant) leads to predictable performance gains.

For vision:
- iGPT treated pixels as tokens → resolution limits due to token count explosion
- VQVAE introduced discrete codebooks, compressing resolutions by 8–16×
- VQGAN improved reconstruction via a discriminator
- Parti scaled up to 20B parameters — a milestone
Challenges ahead:
- High-resolution quality lag vs. diffusion models (DiT)
- Scaling Law for visual discrete tokens not fully validated
- Slow inference via raster scan ordering
- Lack of holistic perception in raster ordering

---
Visual Autoregression vs. Diffusion
Autoregression and diffusion both transform noise into images — but differently:
- VAR: Multi-scale, coarse-to-fine detail addition
- Diffusion: Single scale, noise removal step-by-step
Advantages of VAR:
- High training parallelism
- Human-like interpretability via coarse-to-fine approach
Trade-offs:
- Error accumulation across scales in VAR
- Higher cost per step in diffusion but better error correction
---
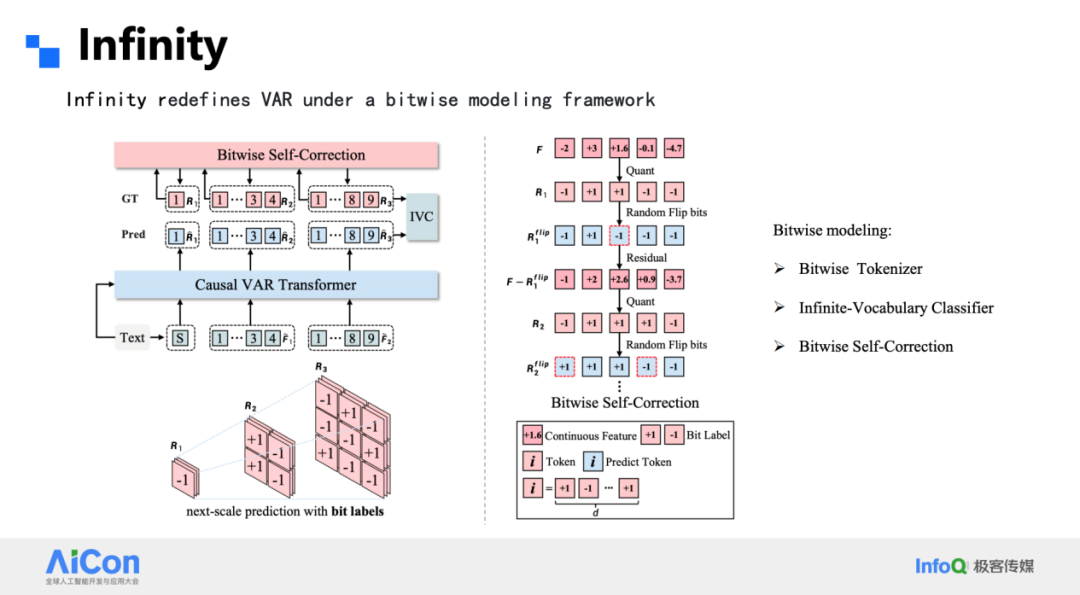
Infinity: Advancing VAR for Text-to-Image
Infinity addresses three major VAR limitations:
- Reconstruction quality for discrete VAE
- Error accumulation without correction
- Support for high resolutions & arbitrary aspect ratios
---
Tokenizer Innovation
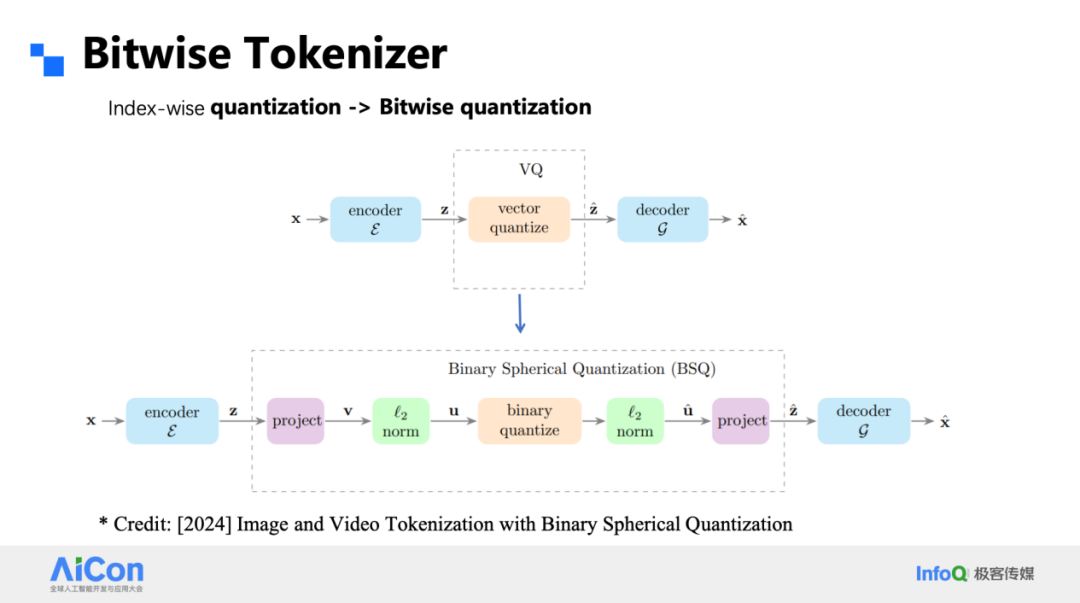
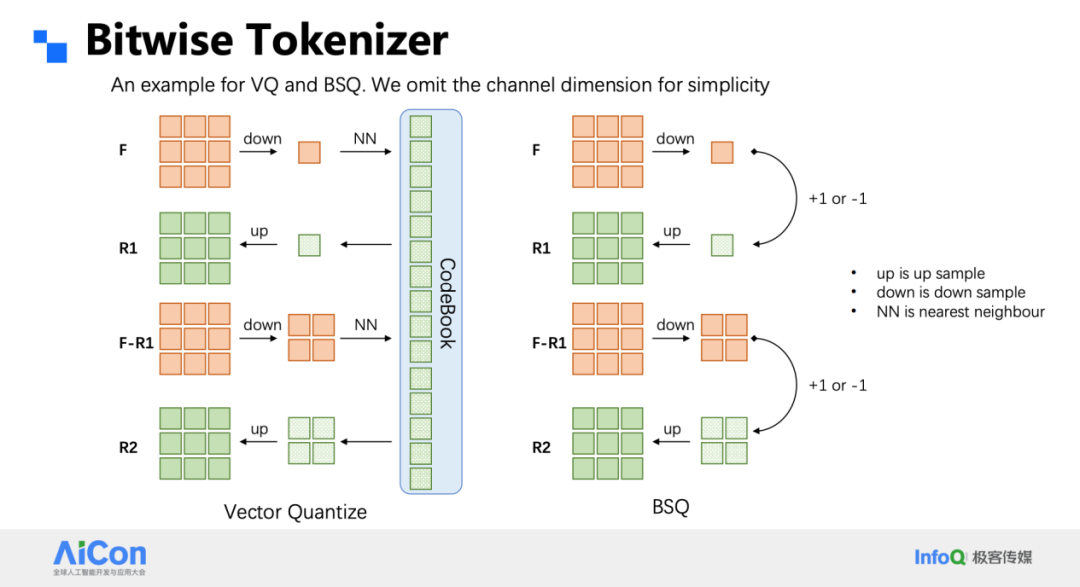
Bitwise Tokenizer
- Sign-based quantization → 1-bit representation per channel (±1)
- Vocabulary size = 2^d (for d channels) → no codebook utilization problem
- Multi-level residual pyramid enables 1024×1024 coverage in 16 steps
Bitwise Classifier
- Predictions per bit instead of full-token classification
- Reduces parameters from 100B to manageable scale
- Improved robustness — bit flips affect only single bits
Bitwise Self-Correction
Network learns to correct bit-level errors by quantizing intermediate outputs during training and inference.
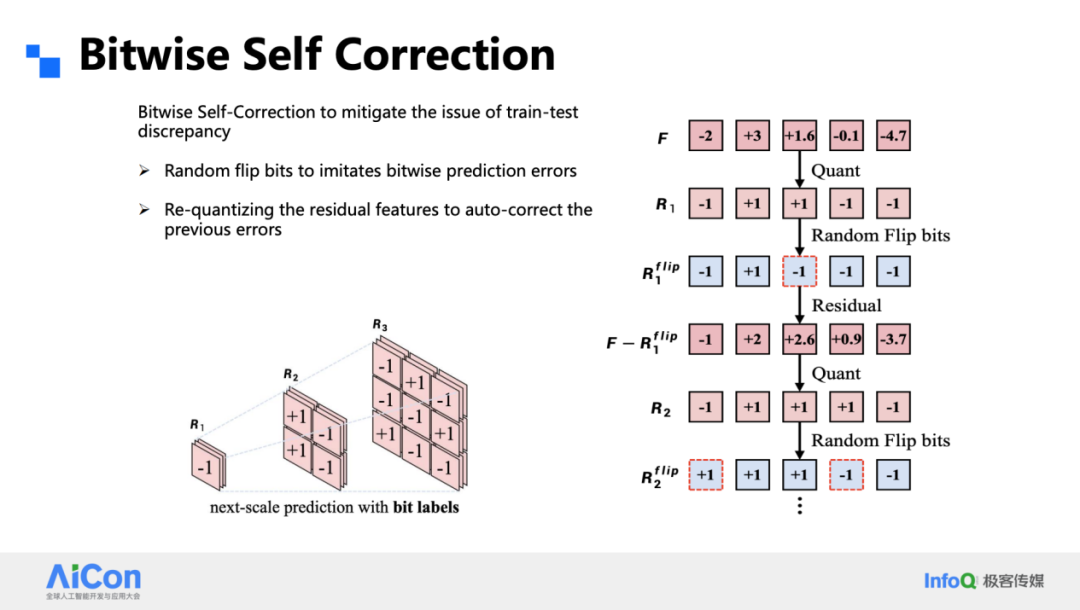
Result:
- FID comparable to/better than DiT at 1024×1024
- Arbitrary aspect ratio support
---
Bridging the Training–Inference Gap
Error Simulation in Training:
- Expand 1×1 tokens along channels
- Randomly flip 20% bits
- Quantize disturbed features for next stage
Outcome:
- Prevent error amplification
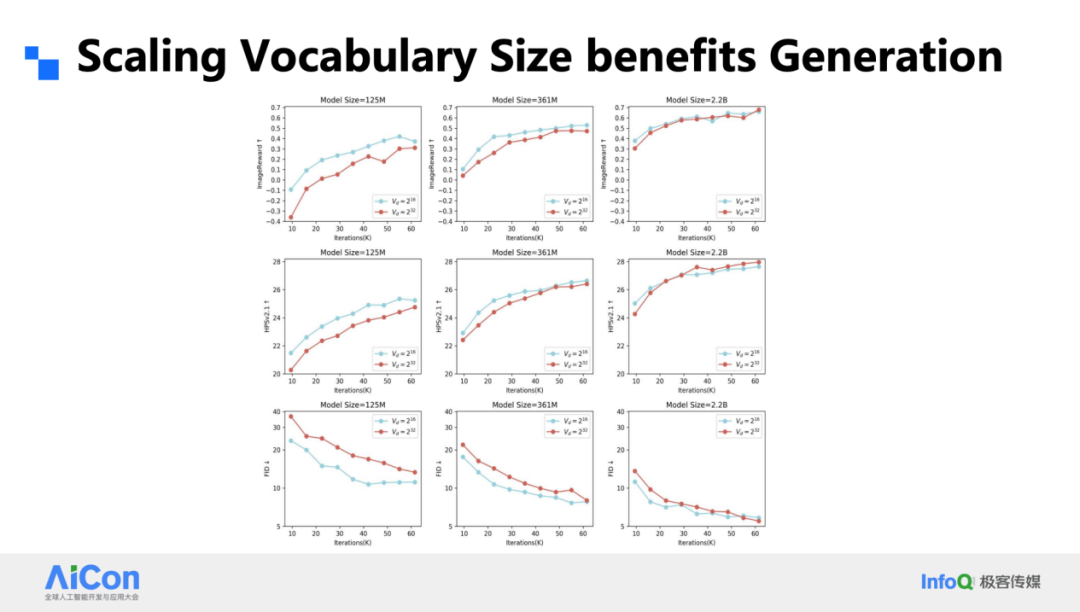
- FID drop from 9 to 3
- Large models + large vocabularies → better performance
Post-training:
Simple DPO run improves detail & quality.

---
Speed & Efficiency
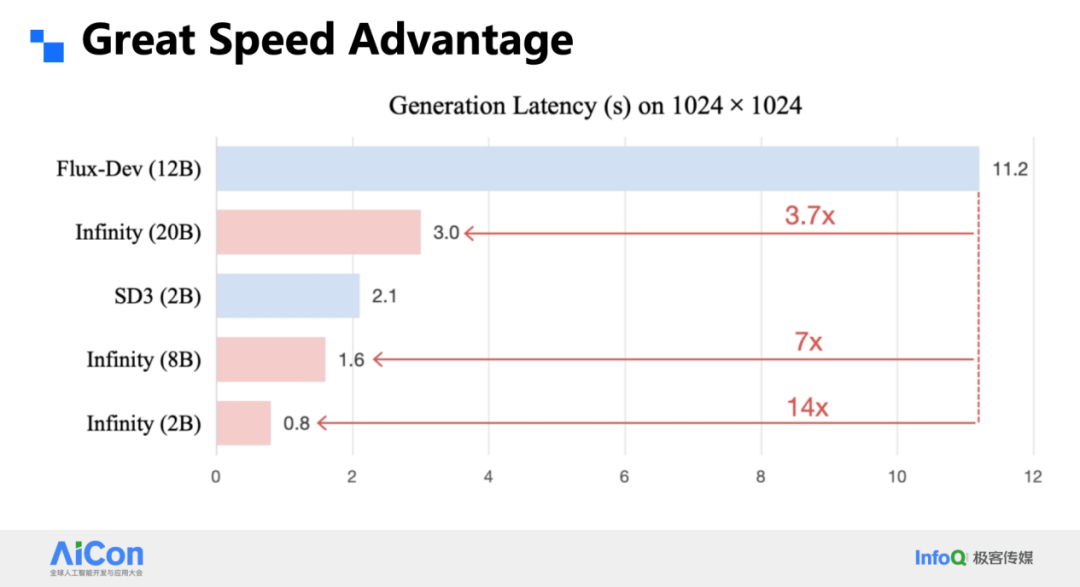
- 0.8 s for 1024² images with 2B parameters
- 20B model: 3 s → 3.7× faster than DiT
- Clear advantage in video tasks
---
Analysis & Reflection
From VAR to Infinity:
- Discrete autoregression now rivals diffusion models in high-resolution text-to-image
- New tokenizer scales to million-size vocabularies
- Evident scaling benefits with larger models/training
- Higher speed with quality parity
---
Connecting Innovation to Creativity
Platforms like AiToEarn官网 bridge research and creative monetization:
- AI content generation
- Cross-platform publishing
- Analytics & model ranking
- Support for Douyin, Kwai, YouTube, X (Twitter), and more
These tools speed adoption of architectures like Infinity VAR in real-world creative workflows.
---
AICon 2025 — Year-End Station, Beijing
Dates: December 19–20
Topics: Agents, Context Engineering, AI Product Innovation, and more
Format: Case studies, expert insights, hands-on experiences

---
Tip: Integrating platforms like AiToEarn directly into your AI generation workflow can significantly expand reach and monetization potential, turning VAR-driven ideas into widely shared, impactful content.


