Agent Lightning
Any Agent Can Use Reinforcement Learning: Microsoft Launches Agent Lightning Framework with No Code Changes

# **微软推出 Agent Lightning:为任意 AI Agent 提供可扩展的强化学习训练框架**
> **新智元导读**
> AI Agent 已逐渐从科幻步入现实:不仅可编写代码、调用工具、进行多轮对话,还能端到端完成软件开发,广泛应用于金融、游戏与软件工程。
> 然而,当前训练与优化环节仍面临挑战,传统强化学习在复杂动态交互场景中表现欠佳。
> 微软提出 **Agent Lightning** —— 一个灵活、可扩展的框架,可对任意 AI Agent 进行基于强化学习的 LLM 训练,并已在 arXiv 发表研究论文。
> [论文链接](https://arxiv.org/abs/2508.03680)
---
## 📌 **核心贡献**
1. **训练与 Agent 执行逻辑完全解耦**
- 首个实现 **Agent 与强化学习** 完全解耦的框架
- 可无缝应用于任何 AI Agent,几乎无需代码修改
- 开发者可突破静态预训练模型的限制,释放自适应学习型 Agent 潜力
2. **基于 MDP 的统一数据接口**
- 对 Agent 执行逻辑进行马尔可夫决策过程建模(MDP)
- 抽象执行复杂性,将运行数据直接转化为训练轨迹
- 引入分层强化学习框架 + 信用分配模块,将轨迹回报映射至每次 LLM 调用响应
- 支持与现有单轮 RL 算法(如 PPO、DPO、GRPO)无缝集成
3. **Training–Agent 解耦架构**
- **Lightning Server** 与 **Lightning Client** 配合提供标准化训练服务
- Client 透明管理 Agent 执行并采集轨迹,无需改动原代码
- 复用可观察性基础设施,确保 extensibility(扩展性)、scalability(可扩展性)、框架兼容性

---
## 🚧 **现有 RL Agent 训练的主要痛点**
- **高耦合性**:需大规模修改甚至重构 Agent 代码,成本高
- **可扩展性差**:面向特定任务的 RL 算法难以通用
- **数据利用率低**:复杂交互数据无法直接用于 RL
- **多轮对话导致上下文序列过长**:增加 LLM 计算与内存开销
---
## ⚡ **Agent Lightning 的核心创新**
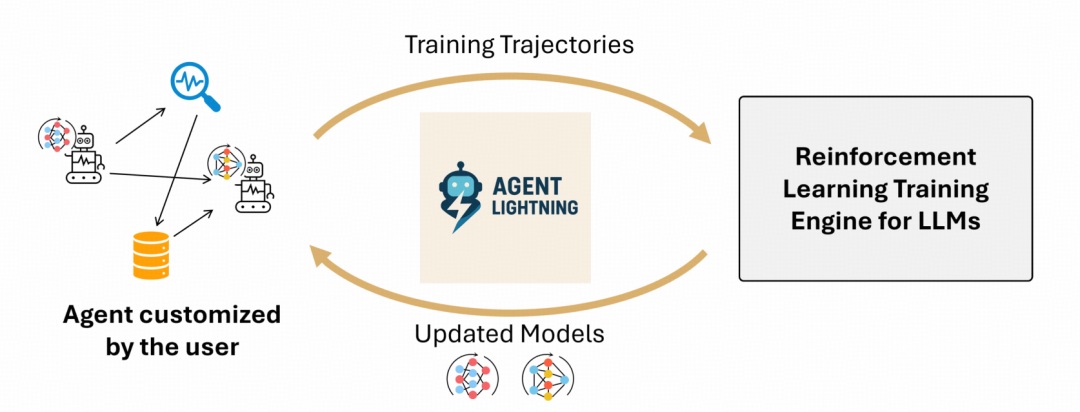
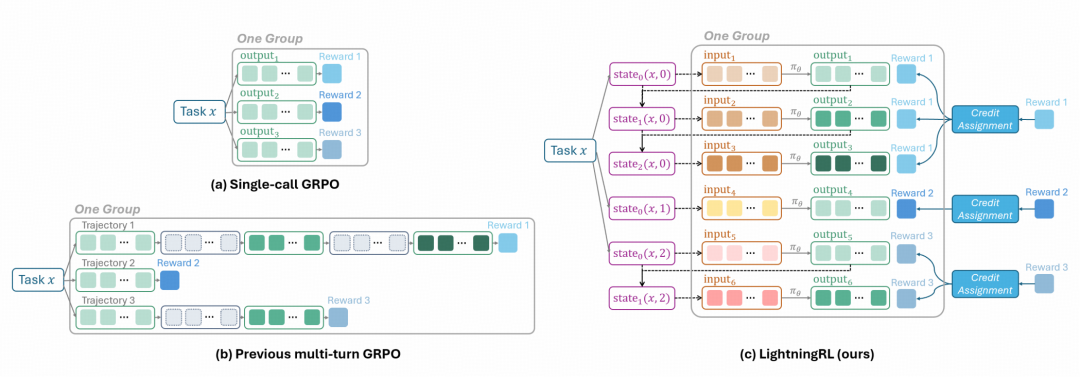
### **LightningRL 算法**
- 分层强化学习结构,专为 Agent 优化策略 LLM
- **信用分配模块**:将完整任务的最终奖励逐步分配到每个执行步骤
- **低层策略更新**:将每一次 LLM 调用转化为独立的单轮 RL 问题,直接应用成熟算法
- 避免长序列上下文累积及复杂掩码操作
- 可灵活使用社区最新 RL 方法,提升训练效率
---
## 🖥 **系统架构设计**
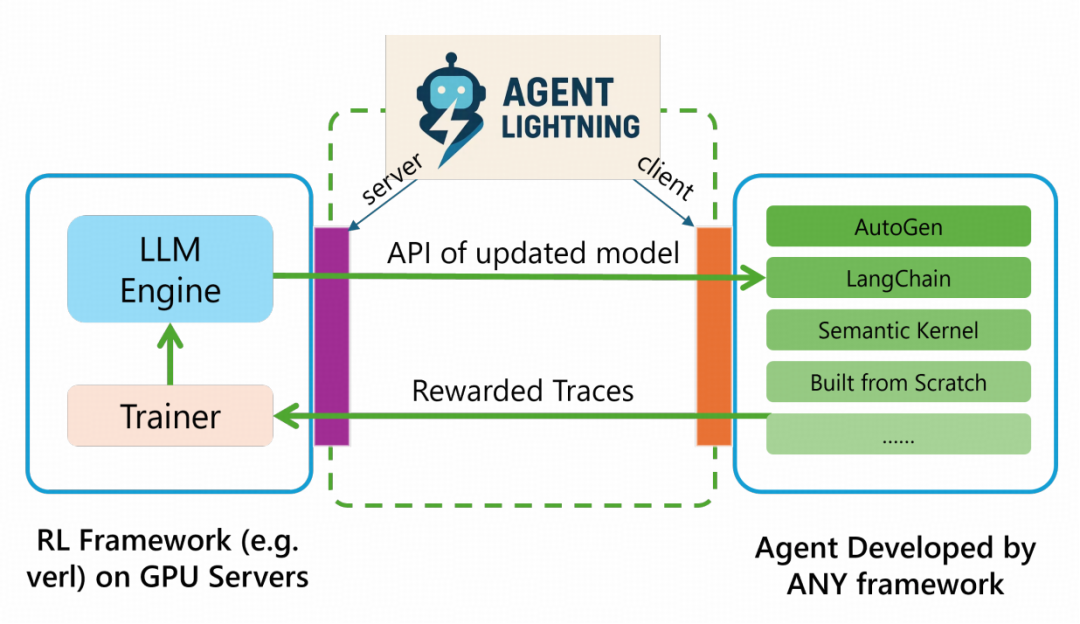
- **Lightning Server**
- “大脑”角色:负责 RL 训练流程
- 提供 OpenAI 风格 API
- 运行训练算法、分配 GPU、管理模型版本
- **Lightning Client**
- 与服务器通信(数据收发)
- 运行 Agent 并采集轨迹
- 集成 **OpenTelemetry**,将监控数据与 RL 训练关联
> 前后端分离架构,开发者专注于 Agent 逻辑与创意,降低 RL 系统搭建门槛。
---
## 📊 **实验结果**
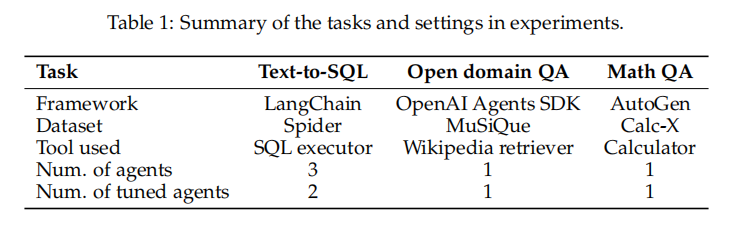
任务包括:
1. **Text-to-SQL**(LangChain 多智能体系统)
2. **检索增强生成(RAG)**(OpenAI Agent SDK)
3. **数学问答与工具调用**(AutoGen)
所有任务 Agent Lightning 均提升了训练表现。
---
## **任务案例详解**
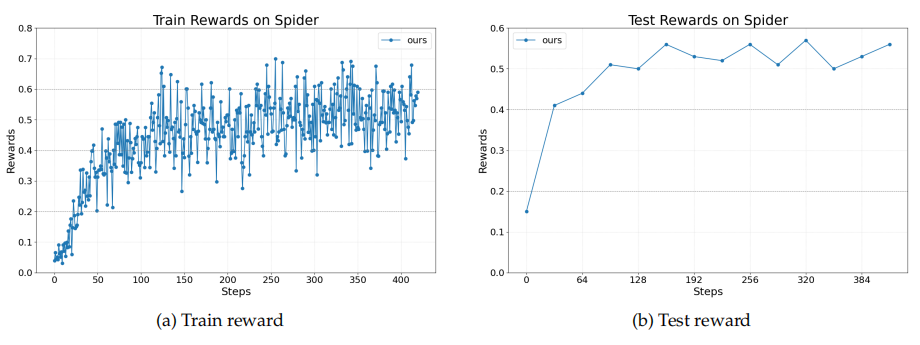
### 1. **Text-to-SQL 多智能体**
- **SQL 写作 Agent** → 生成并执行 SQL
- **检查 Agent** → 判断查询是否正确及数据完整性
- **重写 Agent** → 根据检查结果优化 SQL 或生成答案
- 训练仅优化 SQL 写作与重写 Agent
- 奖励曲线显示性能稳定提升
---
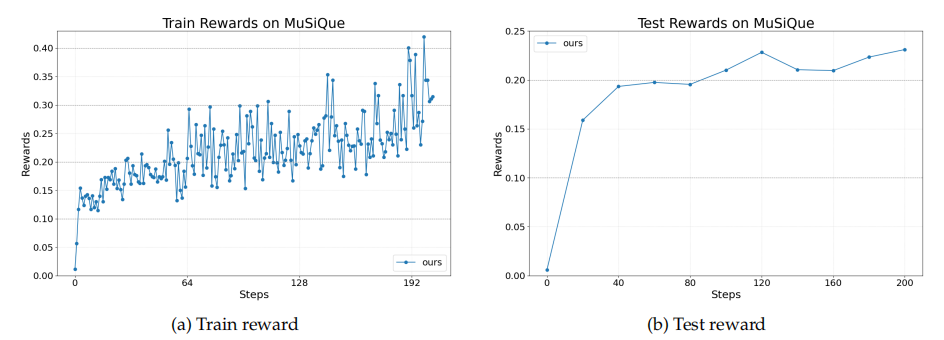
### 2. **检索增强生成(RAG)**
- 生成自然语言查询 → 检索文档 → 决定优化查询或生成答案
- 框架简单但效果明显,表现稳步提升
---
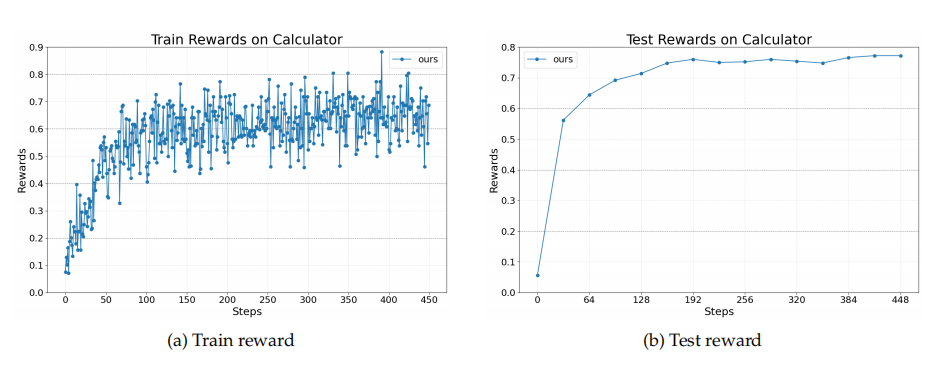
### 3. **数学问答 + 工具调用**
- 测试算术与符号问题解决能力
- 工具调用为计算器
- 奖励与答案准确率常规提升
---
## 🔮 **未来方向**
- 支持其他优化方法(如自动 Prompt 调整)
- **Component of Interest (CoI)** 概念:聚焦并优化特定组件调用
- 发展更高效的 RL 算法:长程信用分配、探索策略、离线算法等
- 进一步架构解耦:分离训练器、推理引擎、Agent 工作流
- 优化 LLM 服务资源调度,提高响应与扩展性
---
## 🌐 **相关平台链接**
- [AiToEarn 官网](https://aitoearn.ai/)
- [AiToEarn 开源地址](https://github.com/yikart/AiToEarn)
- [AI 模型排名](https://rank.aitoearn.ai)
这些平台支持 AI 内容创作、跨平台发布、模型分析与排名,可与 **Agent Lightning** 等技术结合,拓展 Agent 在技术与创作领域的价值。
---
## 📚 **参考资料**
- [微软 Agent Lightning 项目](https://www.microsoft.com/en-us/research/project/agent-lightning/)
- [任意 Agent 可用强化学习!微软发布 Agent Lightning,无需改代码](https://mp.weixin.qq.com/s?__biz=Mzg4MDE3OTA5NA==&mid=2247598569&idx=1&sn=adb19428ee034705b0681ff3f50c412a&scene=21#wechat_redirect)



[阅读全文](2652633206)
[在微信打开](https://wechat2rss.bestblogs.dev/link-proxy/?k=248481d4&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzI3MTA0MTk1MA%3D%3D%26mid%3D2652633206%26idx%3D3%26sn%3Da44c99b8f6769f5d850f9c3f1df68202)