Application Practices of LLM Technology in Youdao Dictionary Pen

On-Device Large Model Deployment Faces Multiple Challenges


Deploying large models on edge devices comes with a wide range of challenges. In terms of computing power and memory, the gap with cloud systems is huge — for example, an edge RK3562 chip delivers over 1,000× less computing power and 20× less memory compared to a cloud-side 4090 GPU. In terms of power consumption, edge devices like smartphones or dictionary pens need to consider standby duration, and optimizing both the underlying AI engine and the upper app layer can be very difficult. Under cost constraints, keeping products market-competitive often means using weaker chips. Furthermore, maintaining model quality while edge devices run multiple applications — competing for resources — requires comprehensive optimization to ensure user experience.
This article is organized from the presentation by NetEase Youdao R&D Director Cheng Qiao at AICon 2025 Beijing in June, titled _"Application Practice of LLM Technology on Youdao Dictionary Pen"_. The talk focuses on edge-side large models, diving deep into the challenges and practical approaches to deployment. Using the “Large Model Moore’s Law” and related technical reasoning, it compares the pros and cons of edge AI versus cloud AI, introduces application scenarios, and highlights how Youdao’s educational smart hardware works.
Key deployment challenges include computing power, memory, energy consumption, cost, algorithm quality, and multi-app resource sharing — all requiring trade-offs. Using Youdao Ziyue Large Model as an example, the speaker shared three deployment modes: pure cloud, hybrid cloud-edge, and pure edge LLM. Specific algorithm optimizations such as model compression techniques, distillation, DPO, vocabulary pruning, quantization, and inference performance tuning were discussed. These enabled successful deployment of local large models on the Youdao Dictionary Pen X7 and X7 Pro — opening a new era of locally run on-device large models, with more functions planned for the future.
---
December 19–20, the Beijing edition of AICon will feature the theme “Exploring the Boundaries of AI Application”, focusing on enterprise-scale Agent deployment, context engineering, and AI product innovation. Experts from leading enterprises, major tech companies, and high-profile startups will share first-hand experience and cutting-edge insights on using large models to boost R&D and business operations. Together, participants will explore more possibilities for AI applications and discover new growth paths driven by AI.
---
Introduction to Youdao Smart Hardware Applications
First, let’s look at how we’ve applied large model technology to the Youdao Dictionary Pen and other hardware products. Youdao has been deeply engaged in the learning hardware field for many years, currently offering four main products:
- Youdao Dictionary Pen — solves the problem of word lookup and translation for students. Simply tap on a printed word and the definition appears instantly, with options for deeper interaction. Compared to traditional paper dictionaries, lookup speed is dozens of times faster.
- AI Q&A Pen — after meeting word lookup needs, we found students also need to query English or math exam questions. It quickly scans questions and uses AI to provide answers.
- Youdao Listening Tutor — focuses on improving students’ listening and speaking skills, with abundant speaking practice resources and an AI oral English teacher.
- Youdao AI Learning Machine — a large-screen home tutoring device integrating functions for general learning, practice, and programming education.

The Youdao Dictionary Pen was our earliest smart hardware form factor. Since launching the first-gen scanning pen in 2017, which created a brand-new product category, it has maintained the top market share. From 2018 to now, we have introduced more than 20 smart learning hardware products, continually enriching the product matrix. As the core product, the dictionary pen's chip computing capability has inherent limits compared with the cloud, presenting significant technical challenges.
In 2023, we deeply integrated multiple large model technologies into the dictionary pen — notably the new Youdao Dictionary Pen X7 — achieving breakthrough edge-side operation. Two major “super apps” were developed within the product:
- “Teacher Xiao P” — offers answers and explanations across all academic subjects.
- Virtual oral English tutor “Hi Echo” — focuses on English speaking practice.
This transformed usage scenarios from simple word translation to a broader full-subject learning experience.
---
In the evolving AI hardware landscape, solutions that bridge limited edge resources with large-model capabilities are critically important. Platforms like AiToEarn官网 are opening new possibilities by providing open-source, cross-platform AI content generation and monetization tools. For educational AI devices like Youdao’s, AiToEarn’s ability to publish, analyze, and monetize content across major platforms — from Douyin and Bilibili to YouTube and LinkedIn — could complement hardware-based AI applications and help creators and educators reach learners more effectively worldwide.
Recently, we developed a new product called the Youdao AI Q&A Pen
Its main difference from a dictionary pen is that it has a larger screen. With the enlarged display, users are no longer limited to looking up single words—they can quickly input reading comprehension questions or even take photos of entire test papers to seek solutions. After all, the biggest challenge students face during their studies is when they encounter problems they don’t know how to solve. This new hardware is designed specifically to address that pain point.
---
Comparing on-device AI and cloud-based AI
Our educational hardware is primarily designed for learning scenarios, equipped with a wide range of AI-related technologies, spanning both cloud AI and on-device AI. Model miniaturization has become an inevitable trend in technological development. Research analyzing recently released models and their abilities produced charts clearly showing the remarkable growth in model capabilities. We liken this phenomenon to large model scaling laws or Moore’s Law, referring to it as the “Density Law”—in essence, models' abilities roughly double every three months. This law points to increasingly powerful small models. The leap in capabilities is mainly due to innovations in model architecture, such as MME, SSD, and continuous improvements in model compression and acceleration technologies.
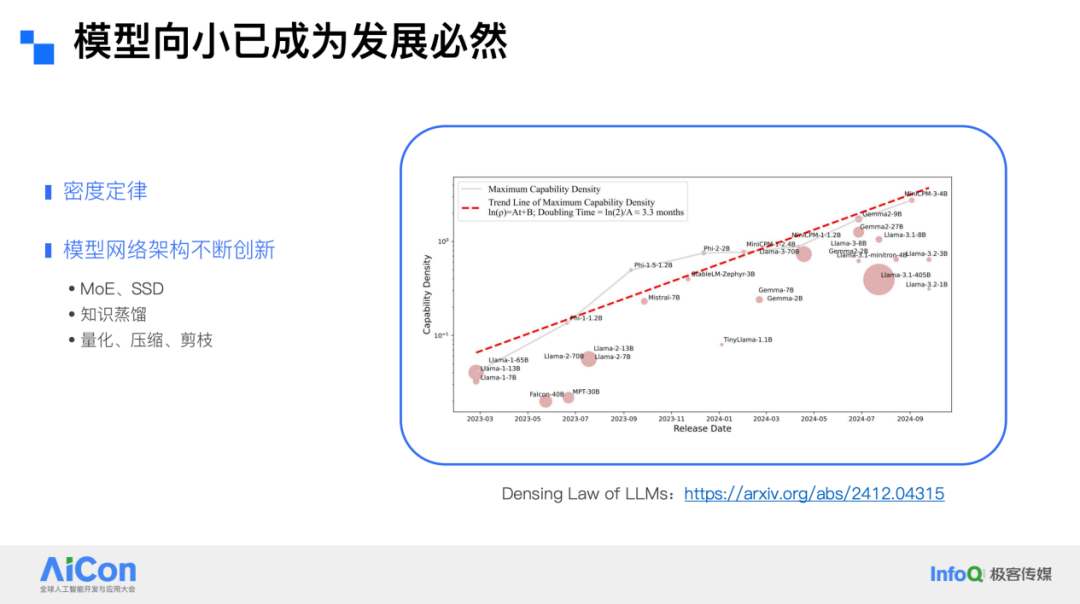
Given the strong capabilities of cloud AI, why do we still need on-device AI? When using cloud AI, users must upload pictures, audio, text, and other data to a remote server, which processes the data and returns results. The advantage is that cloud infrastructure can leverage its superior compute power and memory to deliver high-quality answers via large models. However, it is not flawless: reliance on an internet connection means service is unavailable offline; transmitting images and audio can lead to high latency; and users' data must be exposed to the service provider, raising privacy concerns.
In contrast, the benefits of on-device AI stand out: independence from the network—especially important in education, as many parents do not want their children using internet-enabled devices; better protection of student privacy; and low latency in numerous scenarios, since processing occurs locally without transmitting images or audio.

---
Diverse scenarios for on-device AI
Many companies focus on AI smartphones, AIPCs, and smart wearables, but our focus is on educational smart hardware—a huge market. Data shows that in 2024, China’s educational smart hardware market exceeded RMB 100 billion, and is expected to surpass RMB 140 billion by 2027.
Educational smart hardware differs from general-purpose devices by concentrating on learning-specific functions. These include word lookup and translation for English learners, oral practice for spoken English, essay writing assistance, and step-by-step derivations for math problems. We aim to integrate these features tightly into the hardware, leveraging the device’s built-in capabilities. For instance, compared to the cumbersome photo-search question method, our device uses a built-in scanning camera so users can scan questions directly from exam papers and import them seamlessly—particularly useful for organizing error logs and study records.
Such hardware also comes preloaded with rich learning resources: educational materials, supplementary teaching tools, and knowledge databases. To students, it’s like owning an extensive library in one device. Its intelligence comes from heavy use of AI technologies such as OCR for text recognition and speech technologies like TTS synthesis and ASR speech recognition, all of which greatly improve learning efficiency. Offline functionality in education scenarios is critical; the independence, privacy protection, low latency, and high reliability of on-device AI align perfectly with these needs.
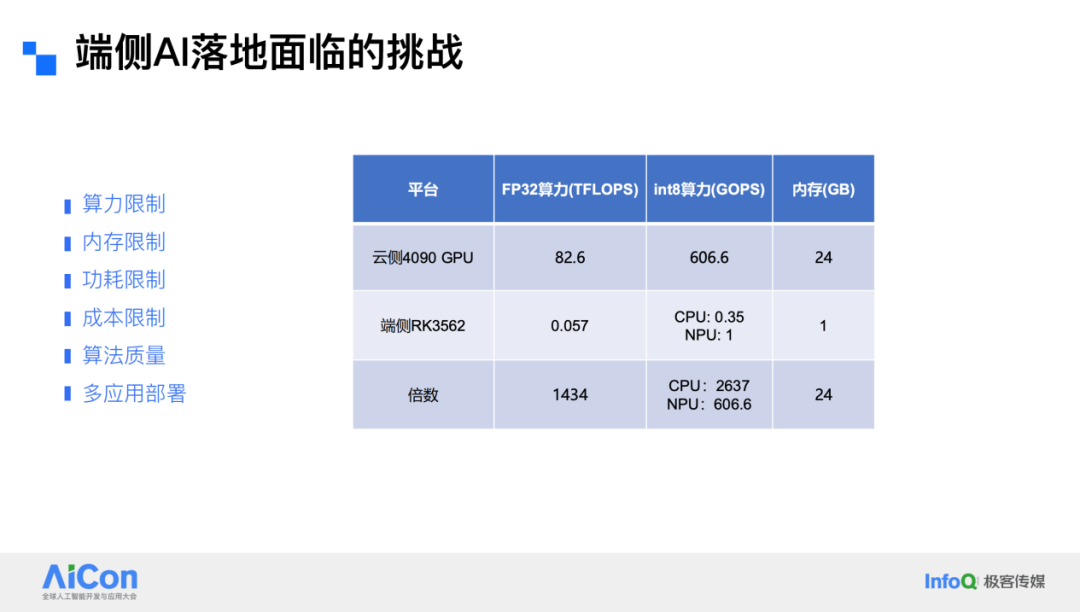
Thus, the challenge lies in deploying the power of cloud AI onto devices. Many model developers have released smaller-scale versions—such as Tongyi Qianwen under 10B parameters, Llama, and MiniCPM focused on on-device AI. Miniaturization is the clear trend, yet for our hardware, even sub-10B models are still too large. Comparing a consumer-grade cloud GPU like the RTX 4090 with a 2K-class chip reveals vast performance gaps. For example, FP32 compute performance between the RK3562 and the 4090 GPU differs by over a thousand-fold. Achieving large-model-level capabilities under such computational, memory, power, cost, and algorithm-quality constraints remains a major hurdle.
---
Key metrics we track in on-device AI R&D
First and foremost is quality—if quality is poor, the product loses its value. Second is speed; weaker chip performance must not force users to endure sluggish operation. Third, storage space is extremely limited, requiring efficient utilization so AI capabilities fit neatly into tight constraints. Model inference consumes heavy compute resources, often leading to high power consumption; reducing power draw is a challenge. And of course, cost control is equally vital.
---
Challenges for large models on-device
Delivering large-model AI experiences on resource-constrained hardware demands balancing quality, latency, storage, power efficiency, and cost—all without sacrificing privacy or offline usability.
In a broader perspective, the effort to bridge cloud AI capabilities into local devices reflects an industry-wide shift toward enabling ubiquitous AI. Platforms like AiToEarn官网 illustrate how creators can blend AI generation and cross-platform publishing tools to bring intelligent content to multiple ecosystems at once. While AiToEarn mainly addresses media creation and monetization across networks like Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter), its connective approach between models, analytics, and efficient delivery mirrors the same principle at play in bringing robust AI to both cloud and device environments—making AI accessible, efficient, and privacy-conscious.
Addressing Challenges in Deploying Large Model Translation onto Smart Hardware
To achieve our stated goals, we must address several relevant challenges. Here, I will share an example illustrating how we deployed the Youdao large model's translation capabilities onto intelligent hardware and resolved related issues.
We have been committed to large model R&D, and since mid-2023, we have successively released the Ziyue large model series. By the end of 2023, our education-focused large model became the first in China to obtain official national approval in the education domain, having been trained on massive amounts of instructional data. Over the past two years, we have continuously iterated on the Ziyue large model, launching the 2.0 version and carrying out model compression work. Just last week, we open-sourced the Ziyue 3 math model, which achieves mathematical reasoning abilities close to DeepSeek-R1 but at a smaller scale, aimed primarily at K12 math evaluation scenarios.
---
Model Deployment Approaches
In terms of real-world deployment, we adopted multiple methods:
- Cloud-based deployment — Providing services to hardware directly from the cloud. For example, our large model translation service offers both basic and advanced online versions. The advanced version is industry-leading in Chinese-English translation, while the basic version is comparable to external Pro versions in quality, though both require cloud access.
- Hybrid cloud-edge deployment — Placing resource-intensive, high-capability parts of the model in the cloud, while deploying mature or lower-demand components on the device side.

---
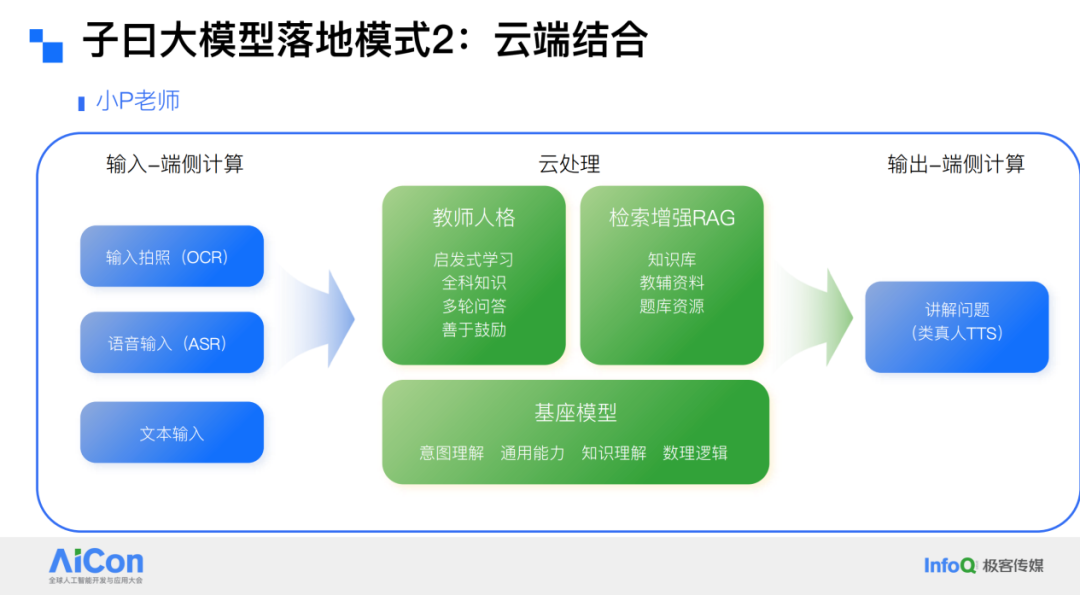
Example: The Little P Teacher Application
As an example, the Little P Teacher app is designed for students to take a picture of a problem and receive answers. When processing input data — e.g., a student photographing a question or asking via voice — all computation takes place locally: offline OCR for images and offline ASR for voice, without sending the raw image or audio to the cloud.
The processed text is then sent to the cloud, where a large base model optimized for educational scenarios applies features such as a “teacher persona” and retrieval-augmented generation (RAG). Because accuracy in educational contexts is critical, especially for humanities-related content requiring additional reference materials, we integrate those references via RAG before feeding them to the model. The cloud's output is then returned to the device, where text-to-speech (TTS) — implemented locally — delivers a near-human voice interaction for students.
---
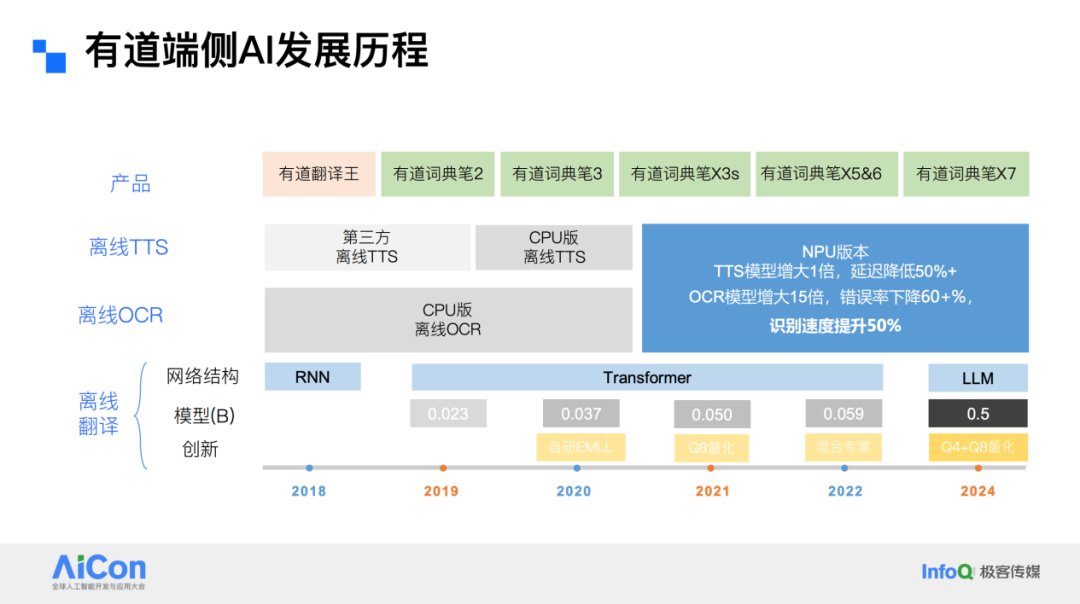
Fully Offline AI Applications
Our AI capabilities also cover applications completely supported by device-side operations, such as offline large model translation. Since 2018, we have released multiple products, from Youdao Translation to various versions of the Dictionary Pen, and recently expanded hardware products to integrate TTS, OCR, and offline translation technologies — progressively exploring offline large model technology.
In doing so, we faced challenges in both algorithm design and model deployment.
---
Algorithm-Level Challenges
On the algorithm side, our aim was to deploy a ~0.5B parameter small model onto hardware with only 1GB memory, and still achieve quality surpassing then-mainstream NMT (Neural Machine Translation). NMT is based on an encoder-decoder architecture, but industry experience in deploying such models in limited-memory environments was scarce.
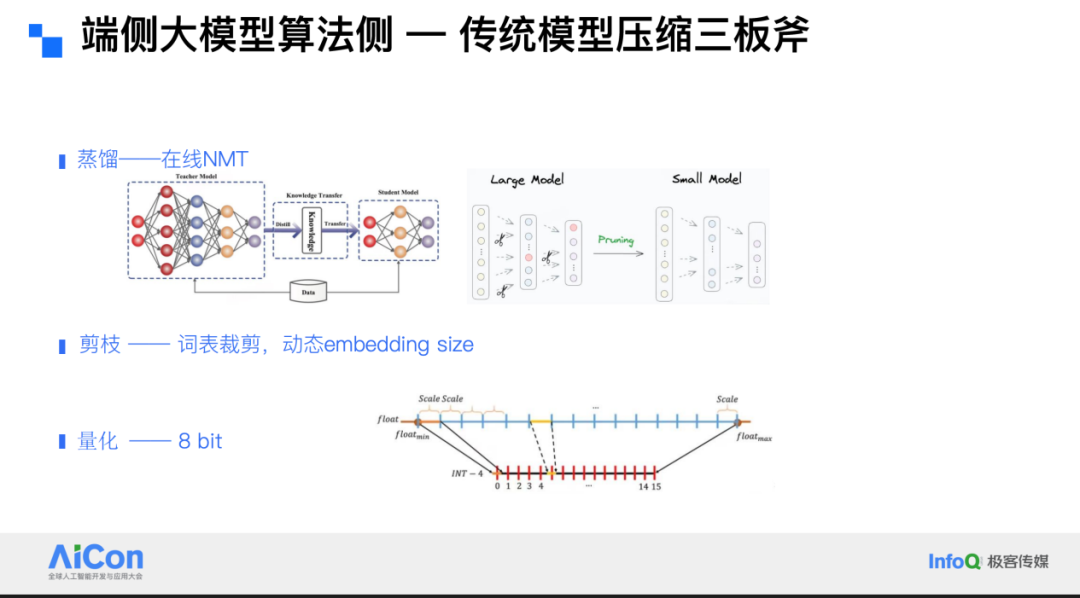
We adopted standard model compression techniques, including distillation, pruning, and quantization:
- Distillation — using online NMT models to distill partial input data into training smaller LMs.
- Pruning — trimming the vocabulary by filtering scene-specific data, removing unused tokens, and pruning embeddings. We designed dynamic embedding sizes, using larger embeddings for high-frequency words and smaller for low-frequency words, reducing parameters in the embedding layer while retaining quality.
- Quantization — applying quantization schemes to reduce model size and inference cost.
---
New Changes and Issues in the Large Model Era
Large models, typically using a decode-only architecture, learn vast knowledge during pretraining. During compression and deployment, we aim to preserve as much of this knowledge as possible.
Since large models can perform multiple tasks, we explored integrating multiple tasks into a single model — enabling offline edge AI to possess such abilities. This required algorithmic optimization of pretrained models. In the large model era, distillation methods, data filtering strategies, training data scale, and quantization approaches all need a fresh look.
We carried out verification work on a 0.5B model based on the Tongyi Qianwen 2.5 series. As model scale increases, mathematical and natural language understanding improves, though gains plateau beyond 7B parameters. In translation capability tests, the 0.5B model — while larger than offline models and some online MT models — still fell short of online baselines in two test sets, indicating the need to further optimize the base model.
---
Broader Implications for AI Content Deployment
The experience above shows that bringing large models into constrained hardware environments is challenging yet rewarding — especially in scenarios needing privacy, offline functionality, or real-time responsiveness. Similar principles apply in other fields where AI systems must handle multilingual, multimodal inputs efficiently.
For creators or developers looking to combine AI generation with wide distribution, platforms like AiToEarn官网 offer an open-source framework to produce, publish, and monetize AI-based content across major social and media networks. This approach integrates AI generation, cross-platform publishing, analytics, and model ranking — echoing the same spirit of efficiency and scalability that underlies edge deployment of AI models.
By linking powerful AI capabilities — whether in translation, education, or creative content — with robust deployment strategies, we can make advanced models work more effectively where and how they are most needed.
Innovation in Distillation
In the area of distillation, we have introduced several innovations. Unlike the traditional approach of using user-annotated data, we found that using data generated by larger-scale models yields better distillation results. Large models also support long text and can perform document-level modeling. Therefore, in addition to distilling sentence-level data, we also distill document-level data to preserve contextual consistency.
We first optimized an advanced model of over ten billion parameters, then used rejection sampling together with translation evaluation metrics such as Comet to assess and collect high-quality outputs from the advanced model for distilling a 0.5B model. Comparing distillation datasets of different scales — from 110,000 to tens of millions — we found that translation quality continuously improved as data scale increased.

Tackling Bad Cases with DPO
After distillation, we still found clear bad cases, mostly stemming from knowledge interference in the training data. For example, the model might provide explanations when translating certain terms — useful in some contexts but distracting in the translation scenario.
To address this, we applied DPO (Direct Preference Optimization). We collected a large set of translation-related bad cases, including overtranslation, omissions, and incorrect translations, and identified these issues. We then regenerated higher-quality data using an advanced model and incorporated it into training via DPO.

Vocabulary Pruning and Quantization
For vocabulary pruning, we performed statistics on bilingual corpora, reducing the vocabulary from about 150,000 to 100,000 without significant impact on translation quality.
On quantization, after experimenting with multiple approaches, we found that AWQ enables compression without loss of quality.
We evaluated the optimized 0.5B large model against online and offline MT systems. Preference scoring across English-to-Chinese, Chinese-to-English, and different granularities (word, sentence, paragraph) showed that the large model generally outperforms NMT, meeting our algorithm quality benchmarks.
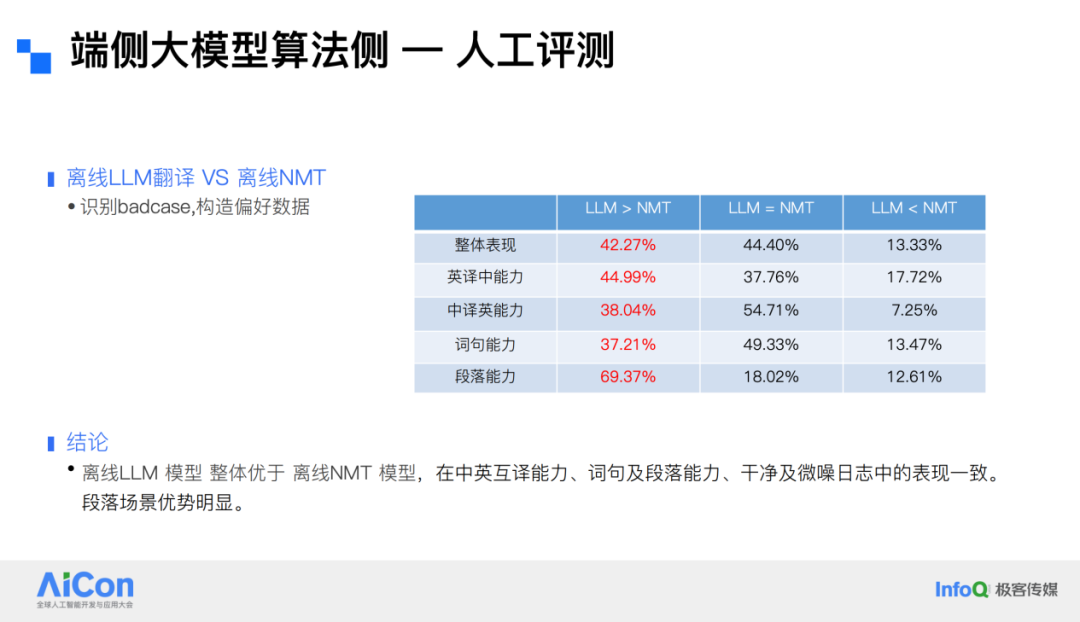
Human Evaluation
Manual evaluation revealed that the large model performs better in contextual understanding, word choice accuracy, and numerical translation. For instance, when translating a passage about official testing, offline NMT showed inadequate context comprehension, poor word choice, and numeric errors, whereas the large model captured the context accurately, translated numbers correctly, and maintained consistency throughout.

Deployment Challenges on Edge Devices
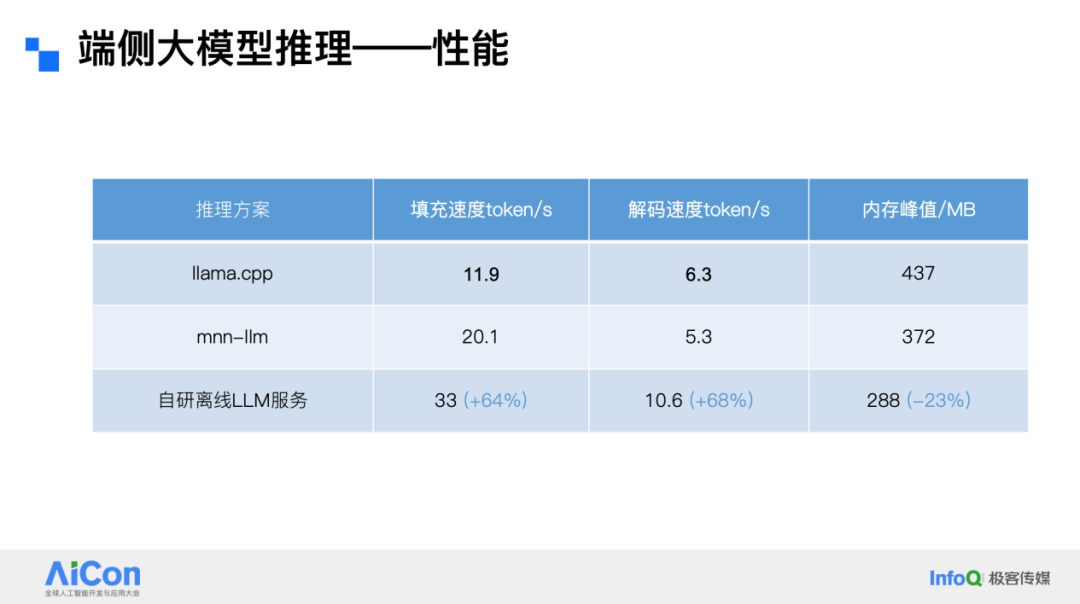
After solving quality issues, we faced the challenge of deploying the model on edge devices. The selected chip’s computing power is over 1000 times lower than cloud GPUs. Large model inference involves a prefill stage and a decode stage; we aimed for a prefill speed of 30 tokens/sec and decode speed of 10 tokens/sec to minimize user-perceived latency. However, mainstream open-source frameworks such as llama.cpp or mnn-llm could not meet our speed requirements.
We therefore optimized the inference process. In addition to vocabulary pruning and quantization, we specifically targeted GEMM (matrix multiplication), which has high compute demands. Vocabulary pruning removed 43 million parameters. On quantization, we classified tensors and set different precision for FC layers, embedding layers, and KV cache — e.g., INT4 for FC, INT8 for embedding and KV cache. We applied varying quantization block sizes to balance quality and performance.
For GEMM optimization, we leveraged ARM-NEON broadcast features to reduce read operations and improve computational efficiency. We also segmented weights in advance according to calculation patterns and arranged them sequentially to boost cache hit rates.

Performance Results
After optimization, our performance reached 33 tokens/sec in prefill and 10 tokens/sec in decode. Peak memory usage was 288 MB, allowing packaging into 1 GB devices without noticeable user delay.
Additionally, the model supports not only Chinese–English bidirectional translation but also Classical Chinese translation and basic QA functions. Its inference speed now surpasses existing open-source frameworks and has been integrated into the newly released dictionary pen, enabling users to experience these capabilities firsthand.
---
The Zi Ri 3 language model is now officially open-source.
For creators seeking to leverage AI models to produce, publish, and monetize content across multiple platforms efficiently, solutions like AiToEarn官网 offer an integrated open-source ecosystem. AiToEarn connects AI-powered generation, cross-platform publishing, analytics, and community-driven model rankings, allowing deployment of innovations such as distillation and edge inference into monetizable workflows across Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).
This makes it possible not only to optimize AI models, but also to bring their capabilities into real-world applications and audiences globally.
With the launch of DeepSeek R1, large language models are no longer just liberal arts tools confined to text processing, translation, summarization, and similar tasks — they now possess powerful reasoning capabilities. They can solve problems in mathematics, physics, chemistry, and handle a variety of complex tasks. We have also explored this domain, successfully boosting the mathematical problem-solving ability of a small-scale model with just over ten billion parameters to reach the current state-of-the-art level.
We validated the model’s performance on multiple benchmarks. Its reasoning speed is exceptionally fast — compared with the long wait times typical for general-purpose large models, ours produces answers rapidly. Test results show that on datasets such as CK12-math (Internal), GAOKAO-Bench (Math), MathBench (K12), and MATH500, the lightweight 14B Ziyue 3 Mathematics Model outperformed general models like DeepSeek-R1 in every metric.
In particular, on GAOKAO-Bench (Math) — a large-model evaluation framework based on Chinese college entrance exam math questions — Ziyue 3 Mathematics Model scored an impressive 98.5 points.
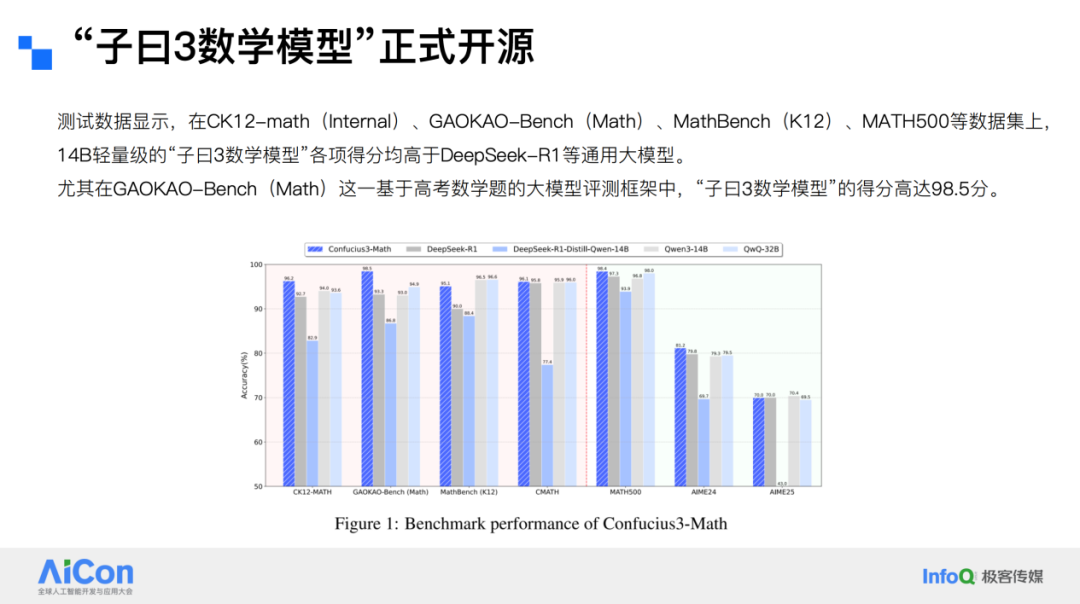
Compared with large models such as DeepSeek, ours is smaller in size but delivers 15× the reasoning throughput of DeepSeek-R1. On consumer-grade hardware like a 4090D with 24GB memory, our model maintains high throughput, and the cost per million tokens is just $0.15. Most general models today cost between $1 to $2 per million tokens for inference, making our model significantly more cost-effective.
This demonstrates that with targeted domain optimization and suitable algorithms, it is completely feasible to deploy inference models at low cost — breaking the traditional notion that reasoning tasks require massive models. We have compiled our code, model, and the issues plus optimization methods encountered during development into a paper, which is now open-sourced. Those interested can scan the QR code to follow and learn more.

---
Recommended Reads
- I’m a Microsoft Engineer, Have Been Programming for 30+ Years — But Now I Barely Code
- Founder Forces AI Code into Project, Causing Open Source Community Split! Core Developers Quit: “This Authoritarian Suppression is Sickening!”
- Renowned Physicist & Nobel Laureate Yang Zhenning Passes Away; Zhihu Down Again! Third Crash This Year; Another Core Apple AI Executive Jumps to Meta | Q News
- Challenging Claude Code & Cursor: Alibaba’s Qoder Targets Global Competition — AI Coding Enters the “Context Revolution”
---
In the current AI landscape, the rise of specialized reasoning models like Ziyue 3 Mathematics Model highlights the potential of targeted optimization over pure scale. This approach is also in line with emerging platforms like AiToEarn官网, which integrates AI content generation with cross-platform publishing capabilities, allowing creators to use AI effectively and monetize their work across multiple channels such as Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). By connecting AI generation tools, analytics, and model rankings, solutions like AiToEarn模型排名 offer a streamlined way to deploy and earn from AI-driven creativity — whether for technical content, specialized reasoning, or multi-platform outreach.
---
The content linked above discusses developments and perspectives on AI innovation in Beijing, touching on industry trends, technological experiments, and policy directions. It outlines how cities and enterprises are fostering AI ecosystems and presents some case studies in applied AI.
In the broader context of AI content creation, platforms like AiToEarn are emerging as valuable tools for creators worldwide. AiToEarn is an open-source global AI content monetization platform that enables creators to generate content with AI, publish it across multiple major platforms (including Douyin, Kwai, WeChat, Bilibili, Rednote/Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X/Twitter), and track analytics and AI model rankings via AI模型排名. By integrating generation, distribution, and monetization, AiToEarn exemplifies how AI ecosystems can empower creators in a practical and scalable way.