# Bridging the Gap Between Vision-Language and Robotic Manipulation
**Date:** 2025-10-16 12:49 Beijing

---
> **China's first domestic few-shot, general embodied manipulation foundation model released — connecting vision-language understanding with robotic control.**
---
## The Data Bottleneck in Embodied Intelligence
In **natural language** and **computer vision** research, large datasets are common.
In **embodied intelligence**, however, high-quality data is scarce.
**Why?**
- Real-world robotic manipulation involves **complex physical interactions**, **real-time feedback loops**, and **dynamic environments**.
- Data collection is **costly**, **time-intensive**, and **hard to scale**.
- Datasets with hundreds of thousands of physical interaction samples are rare.
---
## Limitations in Current Vision-Language-Action (VLA) Models
Even with strong semantic capabilities, existing VLA models:
- **Depend heavily** on large annotated datasets.
- Show **poor generalization** in real manipulation tasks.
- Struggle with **cross-scene adaptation** when data is limited.
**The challenge:**
Enable embodied robots to:
1. Learn **quickly** in few-shot settings.
2. Execute **accurately** in the real world.
3. Transfer learned skills **flexibly** across scenarios.
---
## Introducing FAM-1
**FiveAges** (中科第五纪), a Chinese embodied intelligence startup, announced **FiveAges Manipulator-1 (FAM-1)**.
Core foundation:
- Based on NeurIPS 2025 paper — *BridgeVLA: Bridging the Gap between Large Vision-Language Models and 3D Robotic Manipulation*.
- First effective integration of **large-scale VLM knowledge transfer** with **3D robotic control spatial modeling**.
**Performance Highlights:**
- Requires **only 3–5 samples per task** for training.
- Achieves **97% success rate**.
- Outperforms state-of-the-art (SOTA) baselines.
- Winner of **CVPR 2025 Embodied Manipulation Challenge**.
---
## FAM-1: From VLA to BridgeVLA
**Goals:**
- Address scarcity of manipulation data.
- Improve generalization **across tasks and environments**.
**Key Innovations:**
1. **Multi-type Data Integration**
- Builds a multi-dimensional manipulation knowledge base.
- Secondary pretraining to mine implicit VLM knowledge.
- Improves goal/scenario understanding and generalization.
2. **3D Heatmap Alignment**
- Aligns outputs of VLM with inputs of VLA in the spatial domain.
- Effective fine-tuning with only **3–5 samples per task**.
- Improves spatial comprehension and data efficiency.
---
## Architecture Overview
FAM-1 consists of **two core modules**:
1. **Knowledge-driven Pretraining (KP)**
- Uses web-collected large-scale images/videos.
- Builds an **operation-oriented** knowledge base.
- Second-stage pretraining to adapt VLM to manipulation tasks.
- Predicts robotic arm key positions and trajectories.
2. **3D Few-Shot Fine-Tuning**
- Avoids the “dimensional bottleneck” of flattening 3D data to 1D vectors.
- Uses **3D heatmaps** to preserve spatial structure.
- Reduces sample requirements drastically.
---
## Main Experimental Results
### Benchmarks: RLBench and Colosseum
- Compared with Microsoft, MIT, Stanford, and other teams.
- **RLBench success rate:** 88.2% (6% higher than SOTA).
- Major lead in tasks:
- Insert Peg
- Open Drawer
- Sort Shape
- Door Close
- Hammer Strike
- Average success improvement: **30%+**.

---
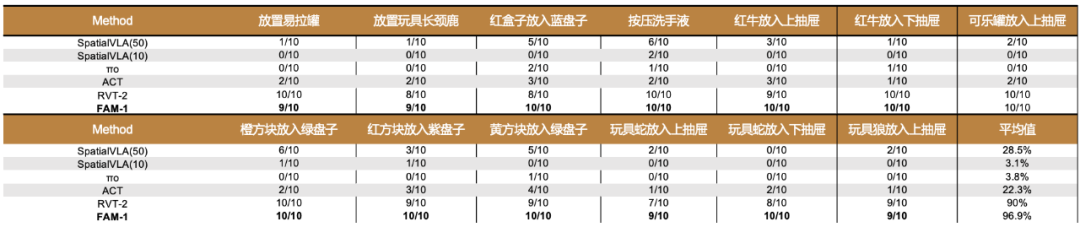
## Real-World Deployment
### Few-Shot Superiority
- Compared against:
- RVT-2 (NVIDIA)
- PI0 (Physical Intelligence)
- SpatialVLA (Shanghai AI Lab)
- **Only 3–5 samples** per basic task:
- Achieves **97% success rate**.
- Shows robustness to distractors, lighting changes, and background variation.
---
## Summary and Outlook
FAM-1 delivers:
- **Few-shot learning** for real-world robotic arm manipulation.
- Cross-scenario generalization via **implicit multimodal knowledge transfer**.
- Preservation of **3D spatial structure** for precise control.
**Future Directions:**
1. **Enhance** generalization and reliability in operational environments.
2. **Promote industrial applications** of foundational models.
3. **Expand** foundational models to navigation tasks.
**Related Work:**
- *EC-Flow* — Self-supervised learning of manipulation strategies from **action-unlabeled videos**.
- Accepted at **ICCV 2025**.
- Robots can learn manipulation simply by watching human operation videos — reducing application barriers.
---
## In the Larger AI Ecosystem
Platforms like [AiToEarn官网](https://aitoearn.ai/) empower creators and researchers to:
- Generate AI content.
- Publish across multiple platforms.
- Analyze performance.
- Access [AI模型排名](https://rank.aitoearn.ai) for model comparison.
This parallels how **FAM-1** unifies knowledge transfer and real-world fine-tuning, enabling wide-scale sharing and monetization of technical innovations — whether in robotics or content creation — across networks like Douyin, WeChat, Bilibili, Facebook, and X (Twitter).
---
[Read Original](2650995884)



