Becoming Linus Torvalds’ Guest: How I Achieved a 47% Performance Leap for a Tencent Programmer’s Comeback
📑 Table of Contents
- Problem Essence: When the Scheduler Becomes the Performance Bottleneck
- Core Contributions of This Work
- Solution: Giving the Scheduler Semantic Awareness
- Design Principles: Considerations for Production
- Performance Evaluation: Let the Data Speak
- Implementation Details: The Devil Is in the Details
- From Technology to Philosophy: Redefining the Cognitive Boundaries of the Scheduler
- Summary
---
🎯 Introduction
At the Open Source Technology Summit, during a discussion with Linus Torvalds, we touched on an underappreciated aspect of kernel design:
> Elegance comes not from complex algorithms, but from a deep understanding of semantics.
That idea, reinforced through hours of discussion, guided a restructuring of the KVM scheduler, producing a 47.1% performance boost for Dedup workloads in high-density virtualization.
---
🚀 When the Virtualization Scheduler Gains Semantic Awareness
In cloud computing, hardware is rarely the real limit — the scheduler’s ability to interpret workload intent is.
In dense scenarios where many vCPUs fight for the same cores, a naïve scheduler enforces rigid rules;
What’s needed is a context-aware scheduler that perceives the essence of contention.
By injecting semantic awareness into the Linux kernel’s KVM scheduler, we achieved a 47.1% jump in Dedup workloads.
This was not just “tuning parameters” — we upgraded the scheduler’s cognitive model.
---
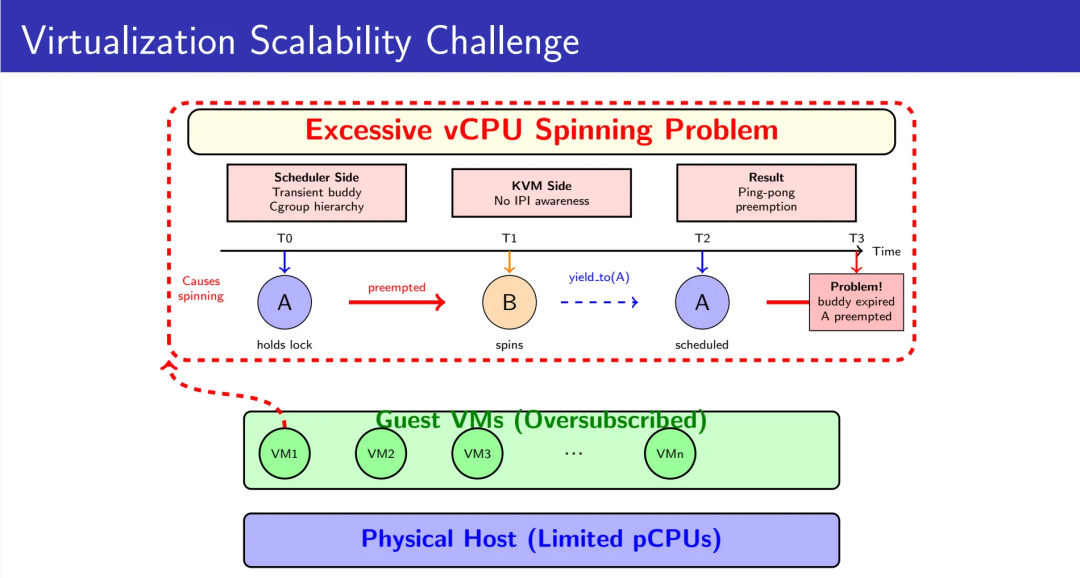
1️⃣ Understanding the Problem: The Scheduler Bottleneck
Ping-Pong Preemption from One-Off Preferences
The current `yield_to_task_fair()` uses a “buddy” system to hint preferences for the next scheduling decision only.
Issue:
- Once the buddy task runs, the hint disappears instantly.
- In nested cgroups, this leads to ping-pong preemption — lock holders lose CPU time before completing critical sections.
- The result: wasted context switches and cache thrashing.
---
Blind Spots in KVM’s Yield Targeting
When a vCPU sends an IPI and waits, the KVM logic might boost an unrelated vCPU instead of the intended recipient.
Cause:
- No awareness of IPI sender/receiver relationships.
- Boosting the wrong vCPU delays the critical path.
---
2️⃣ Core Contributions
- Semantic-Aware Scheduling Framework — works in existing KVM without guest changes.
- Persistent Cgroup-Aware Preferences — fixes buddy limitation in nested containers.
- IPI-Aware Targeting — tracks cross-vCPU comms to pick correct boost targets.
- Empirical Benchmarking — quantified gains across workloads and densities.
---
3️⃣ Solution: Embedding Semantics into Scheduling
Two complementary components:
- Scheduler vCPU Debooster — persistent, hierarchy-aware `vruntime` penalties at the lowest common ancestor in cgroups.
- IPI-Aware Directed Yield — lightweight tracking to identify and boost the right vCPU.
---
Debooster Implementation Highlights
- Apply Penalty at LCA — affects all scheduling paths between competing tasks.
- EEVDF Compatibility — adjust `vruntime`, `deadline`, and `vlag` cohesively.
- Adaptive Penalty Strength — scales by queue length to prevent starvation.
- Anti-Oscillation Detection — halves penalty if two vCPUs yield to each other within 600µs.
- Rate Limiting — 6 ms window to prevent excessive overhead.
---
IPI-Aware Yield Implementation Highlights
- Minimal Per-vCPU Context (16 bytes) — lock-free read/write operations.
- Tracking Hook at LAPIC Delivery — logs sender→receiver link for unicast IPIs.
- Two-Phase Cleanup at EOI — ensures accurate removal of stale context.
- Priority Cascading — guaranteed attempt to boost the most relevant task.
- Rollback Safety Net — relax conditions if no strict candidate exists.
---
4️⃣ Design Principles for Production
- Guest Independence — no guest kernel modifications required.
- Low Overhead — lockless tracking and integer math.
- Runtime Tunable — control via `sysfs`/`debugfs`.
- Conservative Boundaries — empirically balanced rate limits, penalties, and detection windows.
---
5️⃣ Performance Evaluation
Testbed
- Intel Xeon, 16 pCPUs, Hyper-Threading off
- VM: 16 vCPUs
- N:1 dense deployment
Workload Results:
- Dbench: +14.4% throughput (2 VMs)
- Dedup: +47.1% throughput (2 VMs)
- VIPS: +26.2% throughput (2 VMs)
---
Density Analysis:
- 2:1 / 3:1 — sync bottleneck dominates → large gains
- 4:1+ — starvation bottleneck → diminishing returns
Key Insight:
Optimization benefits are limited by the secondary bottleneck.
When starvation becomes primary, more cores—not smarter scheduling—drive gains.
---
6️⃣ Implementation Details
Advantages over Paravirtualization:
- OS-agnostic
- No guest recompilation
- Works across all IPI-based sync (spinlocks, RCU, TLB shootdowns)
- Immediate benefit to existing VM images
Zero Intrusiveness:
Essential for diverse cloud environments with thousands of heterogeneous customer images.
---
7️⃣ From Technology to Philosophy
Schedulers traditionally know “what” is happening.
Semantic schedulers also know “why” — unlocking predictive, intent-driven scheduling.
Lessons:
- Track the highest ROI semantics (e.g., IPI patterns)
- Avoid overcomplicating with low-yield signals
- Maintain mathematical fairness invariants
---
8️⃣ Summary
- Mechanisms: Debooster + IPI-Aware Yield
- Gains: Up to 47.1% performance boost in relevant high-density workloads
- Principle: Understanding intent is a higher lever than tuning algorithms
- Deployment: Guest-independent, low-overhead, tunable at runtime
---
📌 Code submission:
Bottom line:
> As hardware plateaus, the depth of system behavior understanding becomes the new performance frontier.
---
Would you like me to produce an executive summary slide deck for this, so stakeholders can digest the high-level gains without diving into the kernel details? That would make it easier to communicate the 47% leap to non-technical decision-makers.


