# November 13 — Beijing Humanoid Robot Innovation Center Fully Open-Sources Pelican-VL 1.0
## Overview
On **November 13**, the **Beijing Humanoid Robot Innovation Center** officially released **Pelican-VL 1.0**, a **fully open-source embodied Vision-Language Model (VLM)**.
- **Parameter sizes**: 7B and 72B — *the largest open-source embodied multimodal model to date*
- **Benchmark results**:
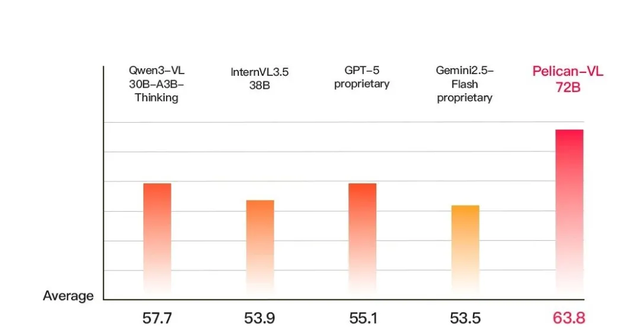
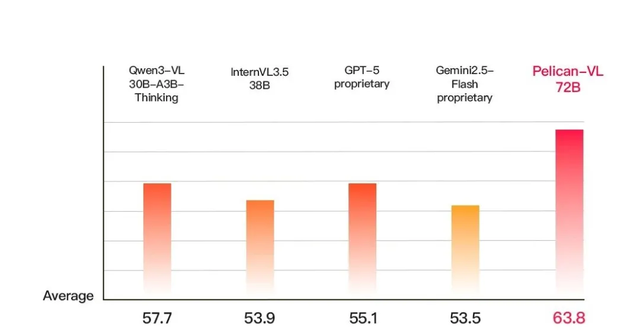
- **+15.79%** over comparable GPT-5-based models
- **+19.25%** over Google Gemini series
- Outperforms key domestic models like **Tongyi Qianwen** and **ShuSheng Wanxiang**
- **Positioning**: *Most powerful open-source embodied multimodal model currently available*
---
## Team & Innovation
- **All-female core creative team**
- Developed **DPPO (Deliberate Practice Policy Optimization)** — *world’s first self-evolving post-training paradigm for embodied multimodal models*
- Achieved top performance with **only 200K samples**, i.e. **1/10 to 1/50** the dataset size used in comparable large models
- Optimized for **value and efficiency** in open-source VLM development
**Applications**:
Commercial & industrial services, high-risk specialty work, household services — enabling complex, multi-step planning for autonomous robotics.
---
## Core Strengths
### Large-Scale Training
- Trained on **1000+ NVIDIA A800 GPUs**
- Checkpoint size: **50,000+ GPU-hours**
- Data foundation: distilled hundreds of millions of high-quality, labeled tokens
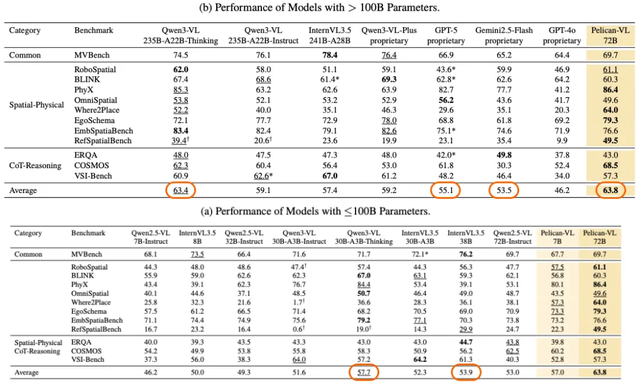
**Performance boost**:
- **+20.3%** over baseline
- **+10.6%** over Qwen3-VL and InternVL3.5 on average
---
### DPPO Paradigm
DPPO trains Pelican-VL like an active learner:
1. **Watch videos**
2. **Self-practice tasks**
3. **Identify mistakes**
4. **Correct via targeted fine-tuning**
**Benefits**:
- Detects “knowledge gaps”
- Improves vision-language comprehension & embodied task abilities
- Strengthens spatial-temporal reasoning and action planning
---
## VLM: Empowering Embodied Intelligence
Humanoid robots require:
- **Spatial-temporal comprehension**
- **Multi-step decision planning**
In a **Vision–Language–Action (VLA)** system:
- Pelican-VL = *visual-language brain*
- Integrates camera input + natural language → multimodal scene representation
- Passes structured data to decision modules
**Challenge**: Pure end-to-end systems = “black box” behavior
**Solution**: Layered models + mutual correction between VLM & world models
---
## Mutual Correction Workflow
1. **VLM** plans tasks in the cloud
2. **World model** builds & predicts physical outcomes
3. Strategies rehearsed inside world model
4. Feedback loop refines capabilities
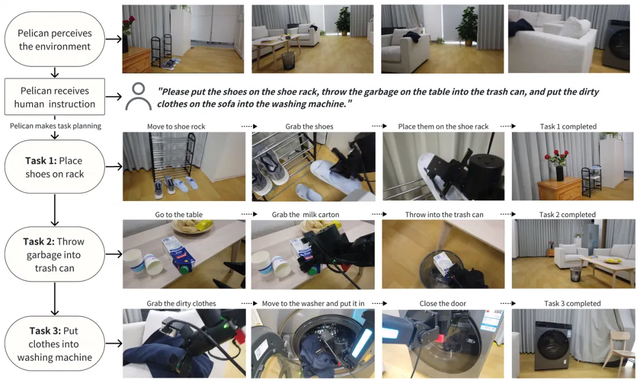
> Example: “Put the shoes on the shoe rack, throw the trash on the table into the trash bin, then place the clothes in the washing machine.”
Pelican-VL:
- Perceives environment layout
- Generates sequential actions:
- Move to shoe rack → place shoes
- Move to trash bin → throw trash
- Move to washing machine → place clothes
---
## Market & Ecosystem Integration
- Open-source model = **“open-type brain”** for robotics
- Accelerates manufacturing, logistics, retail, home automation
- Supports **1,000 Robots Real-Scene Data Collection Program**
Potential to form **domestic general robotics intelligence platform**, acting as a “general smart OS” for robots.
---
## Broader Open-Source Synergy
Frameworks like **[AiToEarn官网](https://aitoearn.ai/)**:
- Generate AI content
- Publish across **Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X**
- Integrate analytics & AI model rankings ([AI模型排名](https://rank.aitoearn.ai))

---
## Resource Links
- **Official Homepage**: [https://pelican-vl.github.io/](https://pelican-vl.github.io/)
- **GitHub**: [Open-X-Humanoid/pelican-vl](https://github.com/Open-X-Humanoid/pelican-vl)
- **HuggingFace**: [Pelican1.0-VL-72B](https://huggingface.co/X-Humanoid/Pelican1.0-VL-72B)
- **ModelScope**: [Model page](https://modelscope.cn/models/X-Humanoid/Pelican1.0-VL-72B)
---
## Pelican1.0-VL-72B Model Overview
**Parameter count**: **72 billion**
**Specialization**: Complex multimodal tasks — deep semantic comprehension, cross-modal reasoning
---
### Key Features
1. **Multimodal Input Support** — images + text
2. **High Parameter Count** — strong generalization and fine-grained understanding
3. **Multi-Step Reasoning** — structured data analysis across modalities
4. **Wide Application** — assistants, content generation, data analytics, multimodal search
---
### Example Application Scenarios
- **Visual Content Analysis** — context-aware image captioning
- **Creative Assistance** — design, marketing, multimedia generation
- **Cross-Language Tasks** — multilingual capacity for global reach
- **Data-Augmented Decision Making** — integrate visuals & text for reports
---
### Technical Specs
- **Training data**: High-quality, diverse multimodal datasets
- **Integration**: ModelScope-compatible pipelines
- **Deployment**: API & cloud service support
**Ethics**: Respect privacy, avoid harmful uses, ensure transparency in AI-assisted outputs.
---
### Related Tools
**[AiToEarn](https://aitoearn.ai/)**:
- Open-source platform for AI content creation
- Cross-platform publishing
- Model performance analytics ([rankings](https://rank.aitoearn.ai))
**Documentation**: [https://docs.aitoearn.ai/](https://docs.aitoearn.ai/)
---
**Reference**: [ModelScope Pelican-VL Page](https://modelscope.cn/models/X-Humanoid/Pelican1.0-VL-72B)
---