# JD Retail — November 11, 2025 — Beijing

## High-Performance Distributed Cache: A New Paradigm

**JIMDB** is a distributed cache service built on Redis, designed for **high performance**, **high availability**, and **online scalability**.
It supports diverse JD Group business units and excels in **high-throughput** and **low-latency** scenarios.
This article explores how JIMDB optimizes and manages *big-hot keys*.
---
## **The Challenge: Big Keys & Hot Keys**
High-performance caches like JIMDB/Redis are plagued by:
- **Big Keys** — large data values that consume memory excessively
- **Hot Keys** — high-access-frequency keys that overload shards
### Why It's a Problem
These issues can cause:
- Single-node resource exhaustion
- Increased latency
- Cascading failures
Traditional **static threshold** detection and reactive handling are no longer sufficient in high-QPS, complex environments.
---
## **The Innovation: Impact-Based Definition**
JIMDB redefines "problem keys" using the **Big-Hot Key** concept:
> **Big-Hot Key**: evaluated based on **real-time resource impact** — CPU usage + network bandwidth consumed — rather than static attributes.
This is a **paradigm shift**:
From *"attribute-based"* → To *"impact-based"* detection.
---
## **Solution Framework**
JIMDB’s **multi-layer proactive governance** includes:
- **Server-side auto-caching**
- **Command request circuit breaking**
- **Blacklist mechanisms**
- **Intelligent client-side caching** with consistency checks
**Detection Engine**: A server-side module that **instantly identifies** risk operations.
---
## **Proven Results**
- In production: Server-side caching of serialized results reduced CPU usage **from 100% to 30%**
- Throughput boosted from **~6,700 OPS → ~12,000 OPS** (+~80%)
- Dramatically cut stability risks
---
## Chapter 1 — Redefining Bottlenecks
### 1.1 Traditional Definitions
**Big Key**
- **Definition**: Value length > 1 MB (Strings), or > 5,000 elements (collections) / >100 MB memory
- **Risks**:
- Memory imbalance / OOM
- Event loop blocking
- Increased persistence/replication delays
**Hot Key**
- **Definition**: QPS > 10,000
- **Risks**:
- Single-node bottlenecks
- Cache breakdown / avalanche when expired
---
### 1.2 Why Big-Hot Keys?
**Big-Hot Key** ≠ Big Key + Hot Key
It focuses on **operation cost**: large data + frequent access → resource exhaustion.
#### Key Differences:
- **Context-dependent**
- Bound to **specific command + parameters**
- Detects "hidden bottlenecks" missed by Big/Hot Key definitions
**Example**:
- List with 8,000 elements, QPS=4,000 — not big/hot by thresholds but `LRANGE key 0 -1` saturates CPU.
---
**Comparative Table:**
| Type | Feature | Criteria | Risk |
|----------------|--------------------------|-----------------------------------|------------------------------|
| Big Key | Large volume | Static size threshold | Memory/slow ops |
| Hot Key | High frequency | Static QPS threshold | Shard bottlenecks |
| Big-Hot Key | Size + frequency impact | Dynamic, real-time impact analysis| CPU/network exhaustion |
---
## Chapter 2 — JIMDB Detection Engine
### 2.1 Three-Level Waterfall Detection
1. **Bandwidth bottleneck** — Instant traffic over threshold
2. **Collection size bottleneck** — Elements > 100,000 or data > 1MB
3. **CPU bottleneck** — Actual QPS > predicted sustainable QPS (ML model)
Stop checks once matched → minimal overhead.
---
### 2.2 Strategy Details
#### Strategy 1 — Bandwidth Bottleneck Detection
- Threshold: 70% of instance output limit (`config get output-limit`)
- Hot Key Index ≈ bytes/sec from command
Example: **140 MB/s** outbound → ~250 OPS per second
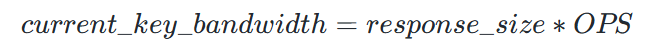
---
#### Strategy 2 — Collection Size Risk
- Element count limit: 100,000
- Single-return size limit: 1 MB
- **Super Hot Key Index**: `INT_MAX` (high-priority warning)
---
#### Strategy 3 — CPU Prediction (ML Model)
- Combines **polynomial regression** & **linear interpolation**
- Predicts per-command sustainable QPS given element count + length
- **Hot Key Index**: grows exponentially beyond limit
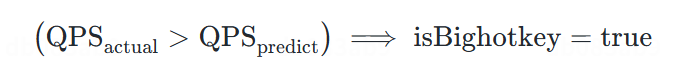
---
## Chapter 3 — Governance Suite
### 3.1 Server-Side Auto Mitigation
- **Auto-cache** serialized responses for repeated reads
- **Circuit breaker**: reject all risky key requests (disabled by default)
---
### 3.2 Client-Side Collaboration
- SDK caches value + version
- Server version check → only full value on change
- Strong consistency + reduced bandwidth
---
### 3.3 Manual Operations Toolkit
- **Manual blacklist**: reject requests without deleting data
- **High-availability management port**: control even if worker thread blocked
- **One-click emergency plans**: UI with instance status, hot key logs, quick actions
---
### 3.4 Cluster Profiling
Defines business attributes & disaster policies:
- Core level (priority)
- Persistence strategy
- Deployment mode
- Delay-read acceptance
- Hot key blockage policy
---
## Chapter 4 — Quantitative Performance Tests
### Environment:
- Physical machine, 8 cores / 16GB RAM
### Scenario 1 — CPU Hot Key
- Before: CPU 100%, OPS ~6,700, frequent alerts
- After: CPU ~30%, OPS ~12,000, stable
### Scenario 2 — Bandwidth Hot Key
- Before: Outbound traffic > limit, CPU near 100%, degraded service
- After: Circuit breaker instantly reduced load, recovery to normal
**Improvement Table**:
| Metric | Before | After | Change |
|-----------------|--------|--------|------------|
| CPU Usage | 100% | ~30% | ↓ 70% |
| OPS | 6,700 | 12,000 | ↑ ~79% |
| Stability | Unstable | Stable | High gain |
---
## Chapter 5 — Deployment & Roadmap
### Current Deployment
- Rolled out to thousands of instances
- >3,000 hot key detections prevented risk
### Upgrade Plan
- Server upgrades independent of client; minimal downtime (~10 min/shard)
---
## Chapter 6 — Industry Context
### Mainstream Approaches:
- More read replicas
- Proxy layers
- Client local caches
- Key sharding
**Issues**: high cost, complexity, inconsistency
---
**JIMDB Advantage**:
Native integration at **platform level** → consistent, reliable, automated governance.
Benefits:
- Lower hardware & ops cost
- Faster development
- Higher system resilience
---
## Chapter 7 — Conclusion
Key takeaways:
1. **Impact-based definition** improves detection precision
2. **Intelligent detection + multi-layer governance** form effective risk control
3. **Wide deployment** validates stability & performance gains
---
### Recommended Reading
- [Generative Recommendations — Evolution & Challenges](https://mp.weixin.qq.com/s?__biz=MzU1MzE2NzIzMg==&mid=2247501334&idx=1&sn=9cfe399e7594ea833227c6a0994b5264&scene=21#wechat_redirect)
- [JoyCode SWE-bench Leaderboard Report](https://mp.weixin.qq.com/s?__biz=MzU1MzE2NzIzMg==&mid=2247501325&idx=1&sn=8de68e5fac3fb1f76e61049470add00e&scene=21#wechat_redirect)
- [Chart Rendering in ROMA](https://mp.weixin.qq.com/s?__biz=MzU1MzE2NzIzMg==&mid=2247501308&idx=1&sn=4ab58b99a43a866d50c766f9ed2df28c&scene=21#wechat_redirect)
- [Scenario-Based Insurance Claims](https://mp.weixin.qq.com/s?__biz=MzU1MzE2NzIzMg==&mid=2247501283&idx=1&sn=e191d994b673fa228f660b36b3bc75ff&scene=21#wechat_redirect)
---
### **Join Us!**
- **Position**: Distributed KV Storage R&D Engineer
- **Location**: Beijing Yizhuang
- **Requirements**:
1. CS major, Linux + C/C++
2. Concurrent/network programming
3. Large-scale storage/DB experience preferred
4. Familiar with Redis, Valkey, RocksDB, LevelDB, TiKV, HBase, NebulaGraph source code
5. Strong engineering discipline
**Contact**: wangqiwang1@jd.com
[Read Original](2247501343) | [Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=5ed302d9&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzU1MzE2NzIzMg%3D%3D%26mid%3D2247501343%26idx%3D1%26sn%3Dbbb3f81dfff1b0c40272b5f73cae628d)
---



