Bilibili’s Multimodal Fine-Grained Image Quality Analysis Model Excels at ICCV 2025 Competition

Preface


During the summer, the Bilibili Multimedia Lab team participated in the ICCV MIPI (Mobile Intelligent Photography and Imaging) Workshop’s Detailed Image Quality Assessment Track international challenge.
We proposed an innovative multimodal training strategy, boosting the composite score by 13.5% and ultimately winning second place.
This competition served as staged verification for our lab’s research in:
- Video Quality Assessment (VQA)
- Multimodal Large Language Models (MLLMs)
- Reinforcement Learning (RL)
---

Figure 1 — Collaboration between Bilibili and Shanghai Jiao Tong University on multimodal image quality assessment and diagnosis.
---
Background
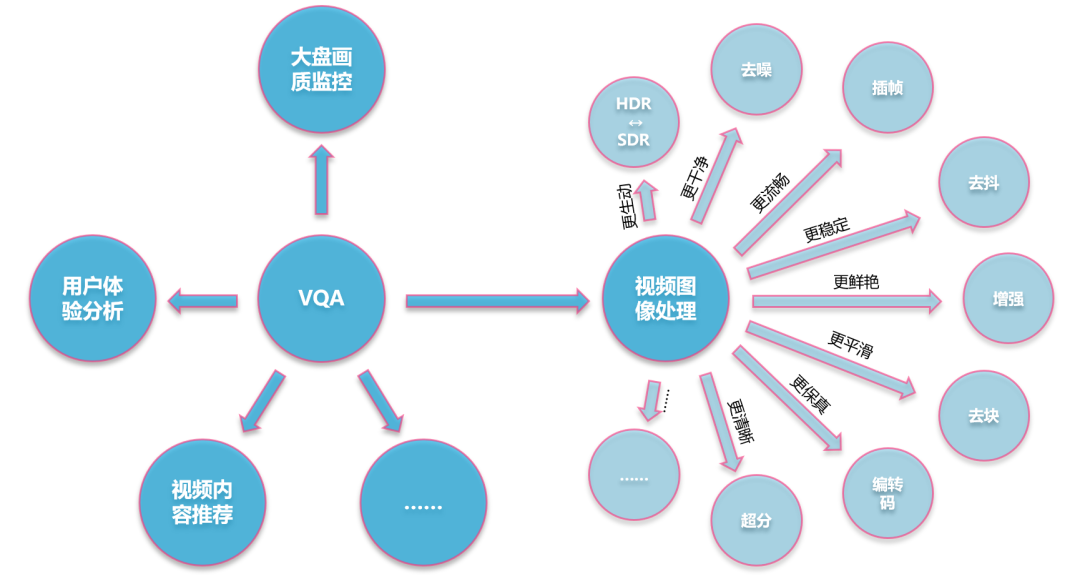
Figure 2 — Video quality assessment’s role in Bilibili’s production pipeline.
Since releasing BILIVQA 2.0 in autumn 2023, our goal has been a full-chain video quality system:
- Video quality pre-analysis
- Automated image processing
- Automated result validation
Problem:
- Distortions vary in type and position, and a single MOS score can’t fully guide processing.
- Toolchain models excel in different distortion scenarios.
- Fine-grained diagnostics greatly improve processing results.
Solution Direction:
Exploit MLLMs for semantic (high-level) and quality (low-level) analysis.
---

Figure 3 — Dynamic resolution handling in mainstream open-source multimodal LLMs.
Current leaders:
- Qwen-VL — temporal position encoding for video.
- InternVL — flexible image input resizing.
Challenges:
- Pretraining lacks quality assessment data.
- Open-source datasets mostly have MOS, not detailed distortion type/position labels.
- Manual annotation is costly; automatic is inaccurate.
Opportunity:
An unsupervised or weakly supervised method could fit MOS while enabling Chain-of-Thought (CoT) reasoning for detailed descriptions.
We discovered GRPO (Group Relative Policy Optimization) fits this need.
---
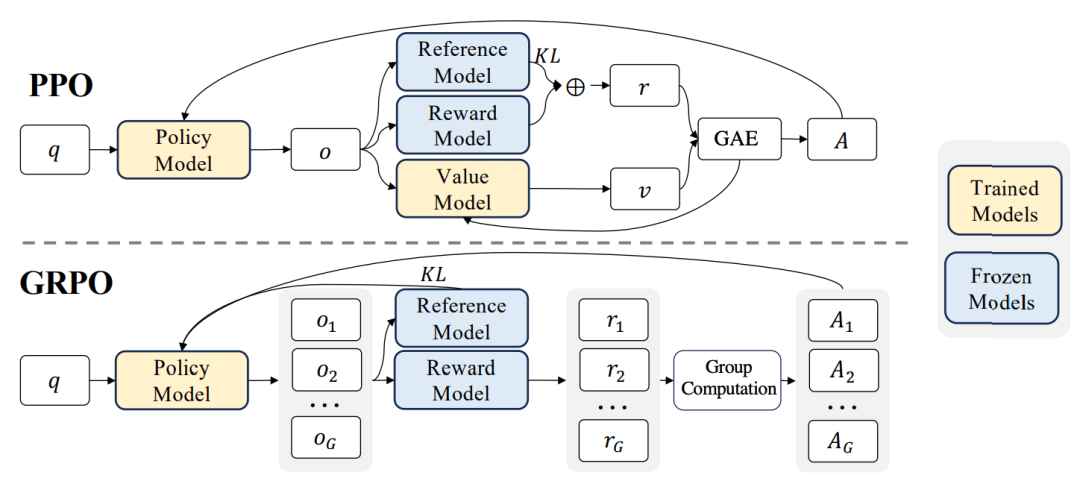
Figure 4 — GRPO vs PPO.
---
GRPO Overview
GRPO is a lightweight reinforcement learning method from Deepseek, ideal for low-resource scenarios.
Key steps:
- Sample G diverse outputs via higher temperature prompts.
- Replace reward model with direct reward functions (rule-based evaluation possible).
- Calculate relative advantage to update the policy model.
Differences from PPO:
- No Critic Model or reward model.
- May cause sparse optimization due to sequence-level rewards vs token-level actions.
- Effective in semantic tasks where reward is naturally sparse.
---
Applying MLLM + GRPO to SDR2HDR Analysis
Context:
- Our SDR2HDR work already covered multiple genres.
- Needed automated model selection based on content & quality analysis.
Goal:
Assess videos for factors like brightness contrast across frames to select the best SDR2HDR model.
Experiments:
- Tried GRPO to enable CoT reasoning.
- For smaller models (≤7B), CoT emergence sometimes helped, but harmed metric optimization.
Final Pipeline: SFT + GRPO
- SFT (Supervised Fine-Tuning) adapts model quickly to domain.
- GRPO boosts accuracy further.
- Removed KL divergence constraints & skipped CoT reasoning for better metrics.
Result:
+3 percentage points in model selection accuracy vs SFT or GRPO alone.
---
ICCV MIPI Competition
Figure 5 — ICCV MIPI Workshop.
Focus Track: Fine-grained Image Quality Localization
Tests capabilities in:
- Image content understanding
- MOS prediction
- Distortion type prediction
- Distortion location tagging
Timeline:
- May–Aug competition window
- Resources available: July → Only 1 month to deliver
Approach:
Start from validated SFT + GRPO, add:
- Data Compression
- Hard Sample Mining
---
Data Compression SFT
Dataset:
- 10,000+ images with MOS
- Organizer-labeled distortion types/positions
- GPT-generated descriptions & 550k prompts:
- Description (content + distortions + MOS)
- Localization (distortion types + positions)
- Perception (MCQs on content/quality)
Compression Strategy:
- Merge multiple questions per image → prompts reduced from 550k to ~110k
- Training time: ~7 days → 2 days
- Minimal performance loss
SFT Goals:
- Rapidly adapt pretrained Qwen2.5-VL 7B to domain data.
- Use compression to reduce overfitting & preserve GRPO exploration space.
---
Difficult Sample Mining with GRPO
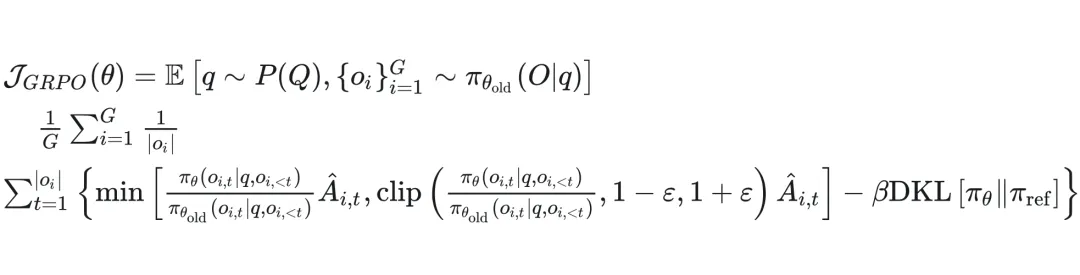
Figure 6 — GRPO objective function.
Problem:
- GRPO needs output diversity; convergence causes entropy collapse.
Solution:
- Mine “moderately difficult” samples (avoid all-correct/all-wrong cases).
- Description/Localization: filter by reward threshold.
- Perception: compress MCQs per image, reward proportional to correct count.
GRPO Training:
- Vision encoder frozen
- LLM component updated
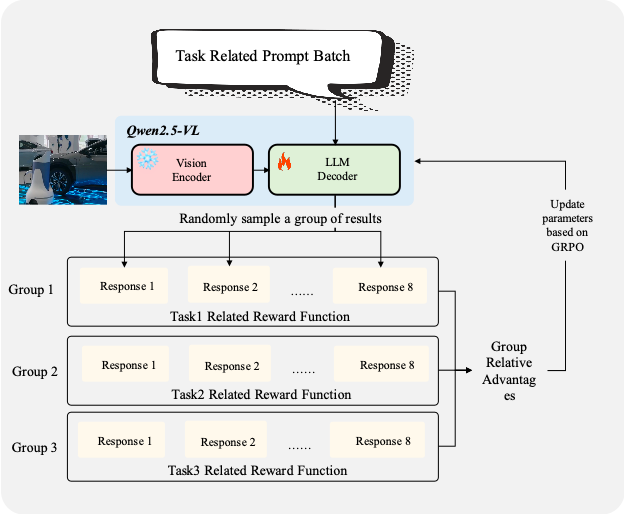
Figure 7 — Our GRPO training framework.
---
Competition Results
- Dev Leaderboard: 1st place
- Final Leaderboard: 2nd place (gap likely due to not using InternVL3)
- Scores:
- Baseline: 2.51
- Compressed SFT: +0.22 → 2.73
- GRPO Mining: +0.13 → 2.86
---
Visualized Output Example
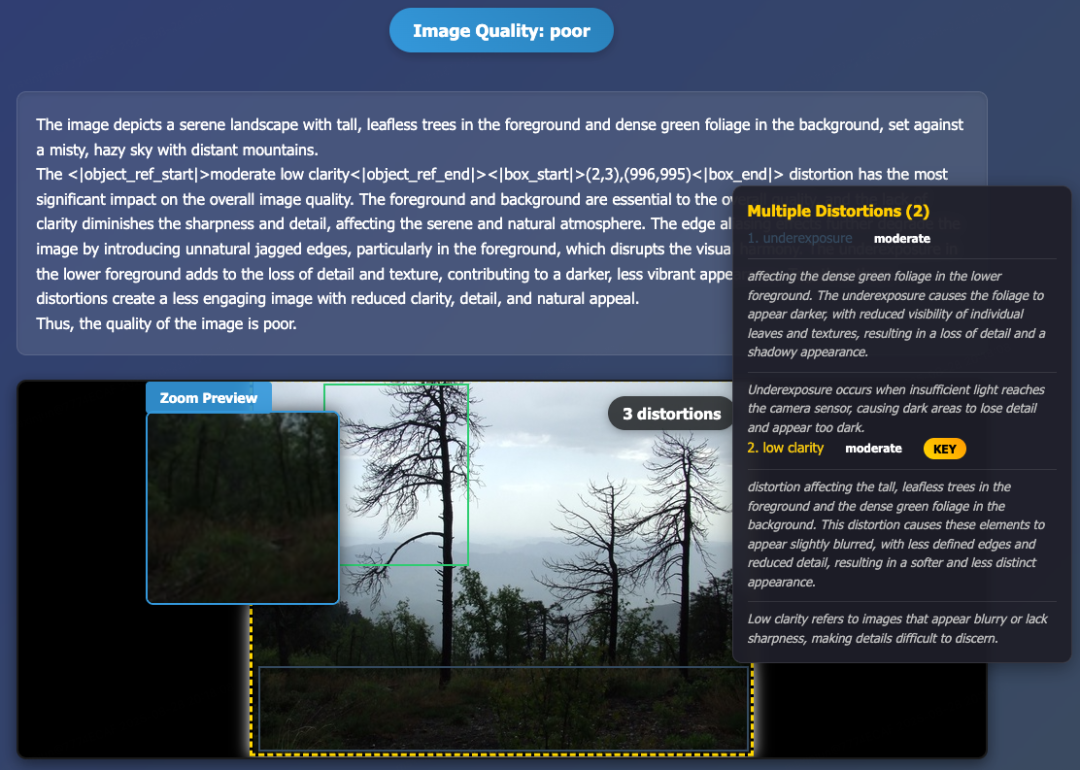
Figure 8 — Partial result visualization.
Analysis Flow:
- Quality classified as poor.
- Content: landscape, tall leafless trees, green foliage, misty sky & mountains.
- Distortions:
- Edge aliasing (green box)
- Underexposure (dark blue box)
- Low sharpness (yellow box) — most impactful, KEY tag.
---
Future Plans
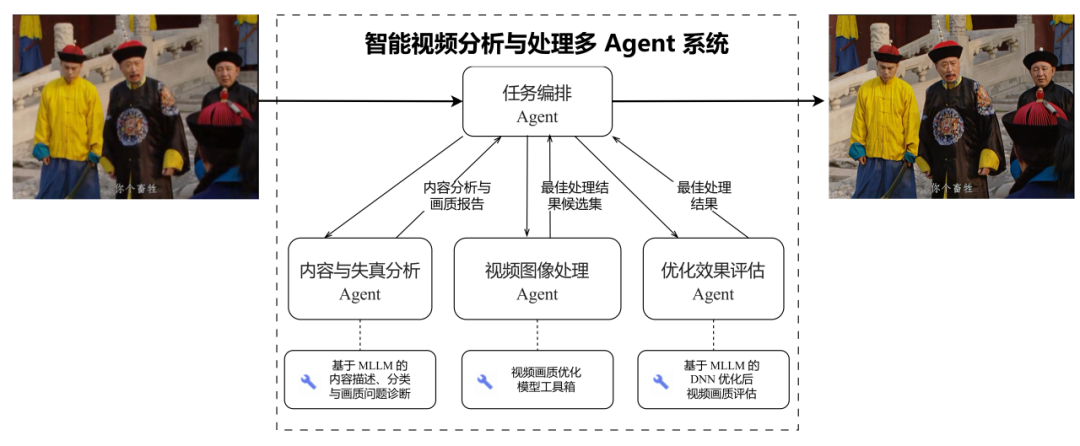
Figure 9 — Intelligent video processing system.
Goal: Build a full-chain intelligent video processing system:
- Content & distortion analysis (current MLLM covers in-the-wild videos).
- Video & image processing (rule-driven → future MLLM-driven).
- Optimization effect assessment (processed video evaluation).
We believe LLMs/MLLMs can deliver substantial efficiency gains today.
---
About Bilibili Multimedia Lab
Young, tech-driven team advancing:
- Multimodal video content analysis
- Image processing
- Quality assessment
- Proprietary encoders
- Efficient transcoding
---
Related Ecosystem Insight
Open-source platforms like AiToEarn官网 help creators:
- Generate, publish, monetize AI content
- Cross-platform reach: Douyin, Kwai, Bilibili, YouTube, Instagram, X, and more
- Analytics & model rankings (AI模型排名)
Benefit for Labs:
Coupling our SFT+GRPO pipeline with AiToEarn’s ecosystems streamlines the path from AI research → production → global monetization.
---
End



