# FG‑CLIP 2: AI “Microscope” for Pixel‑Level Visual–Language Understanding
AI‑generated visuals can be dazzling — but when you need **fine‑grained detail**, many large models still misinterpret spatial relationships, colors, or subtle textures.
---
## Where Traditional Models Fall Short
Consider this prompt:
> “A cat in a red coat, standing to the left of a blue sports car, with a white SUV behind the blue sports car.”

*Two attempts, both wrong — spatial terms like “behind” are still misunderstood.*
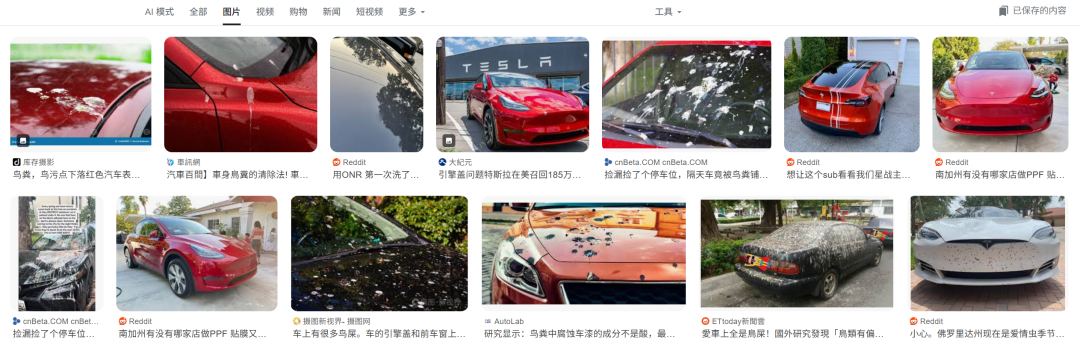
Another search example:
> “A red Tesla with lots of bird droppings on the hood.”
From two full rows of image search results, only one matched completely.
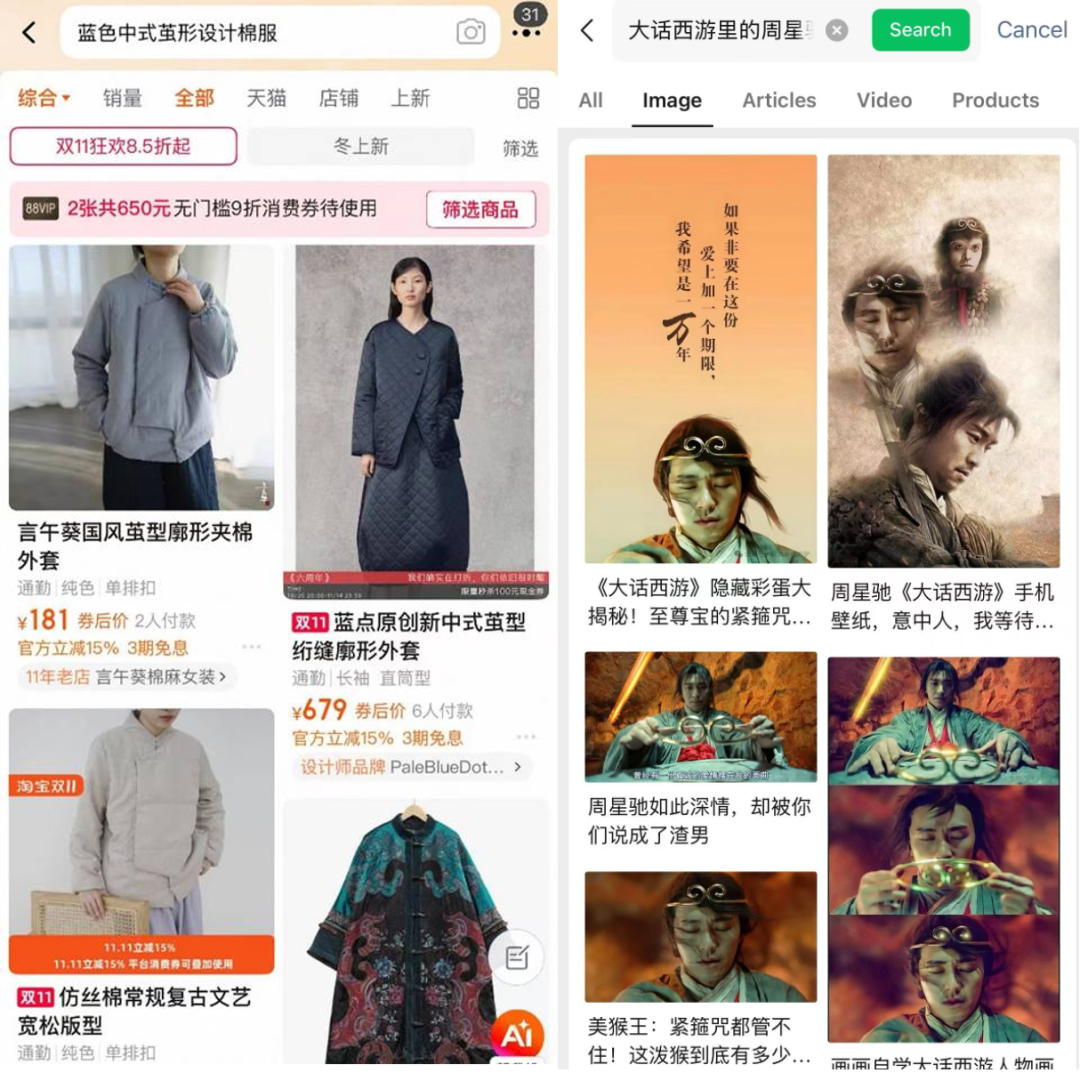
Other tricky cases include clothing descriptions or scenes from films — again, traditional VLMs fail to meet expectations.
---
## Enter FG‑CLIP 2
360’s **FG‑CLIP 2** is designed to overcome these weaknesses:
- **Pixel‑level precision** — recognizes textures, colors, positions, subtleties.
- **Top performance across 29 benchmarks** — beating Google and Meta.
- **Fluent in both Chinese and English** — global reach with local accuracy.
- **Fully open‑sourced** — ready for developers and researchers.

**Resources:**
- GitHub: [https://github.com/360CVGroup/FG-CLIP](https://github.com/360CVGroup/FG-CLIP)
- Paper: [https://arxiv.org/abs/2510.10921](https://arxiv.org/abs/2510.10921)
- Project homepage: [https://360cvgroup.github.io/FG-CLIP/](https://360cvgroup.github.io/FG-CLIP/)
---
## “Seeing the Smallest Details” — 29 Wins
### Example: Understanding What’s on a Screen
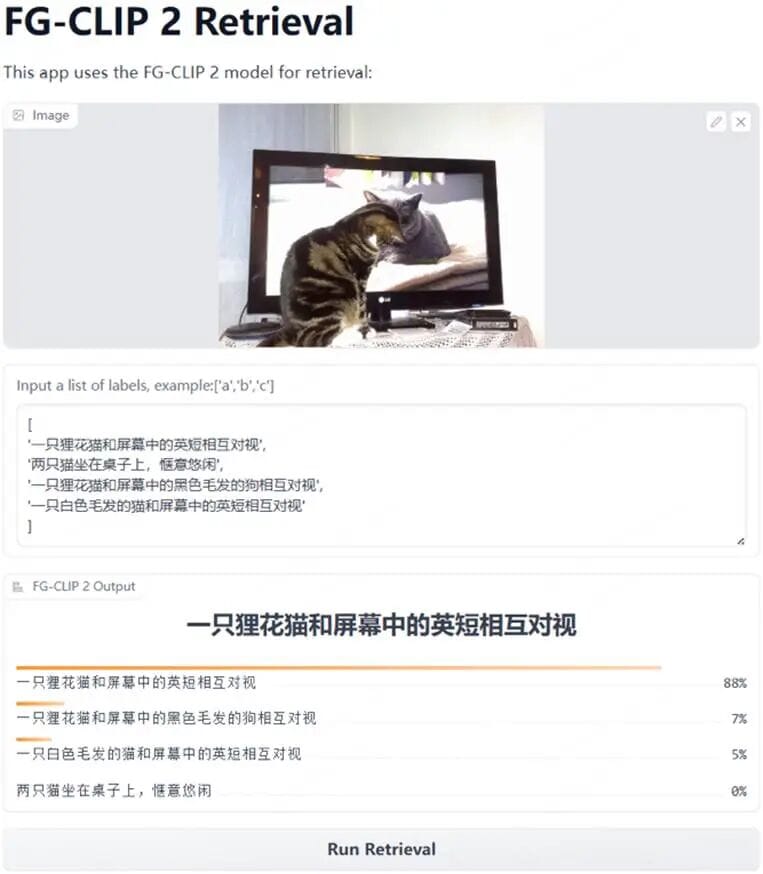
FG‑CLIP 2 confidence score: **88%** for:
> “A tabby cat and a British Shorthair on a screen looking at each other.”
Where traditional CLIP models only see “a cat looking at a screen,” FG‑CLIP 2 distinguishes the **cat inside the screen**, identifies breeds via fur texture, and resolves spatial relationships.
---
## The Evolution of CLIP
**2021 — OpenAI CLIP**
Introduced image–text matching in a shared semantic space.
**Google SigLIP & MetaCLIP**
Strong, but still “near‑sighted” in areas like:
- Fine texture recognition
- Spatial placement accuracy
- Semantic precision
- Chinese language comprehension
---
## FG‑CLIP 2: A Turning Point
Tasks benefiting from fine detail include **search, recommendation**, and **text‑to‑image generation**. FG‑CLIP 2 switches from “glasses” (FG‑CLIP v1) to a **microscope** — clarity surges.
### Complex Scene Example
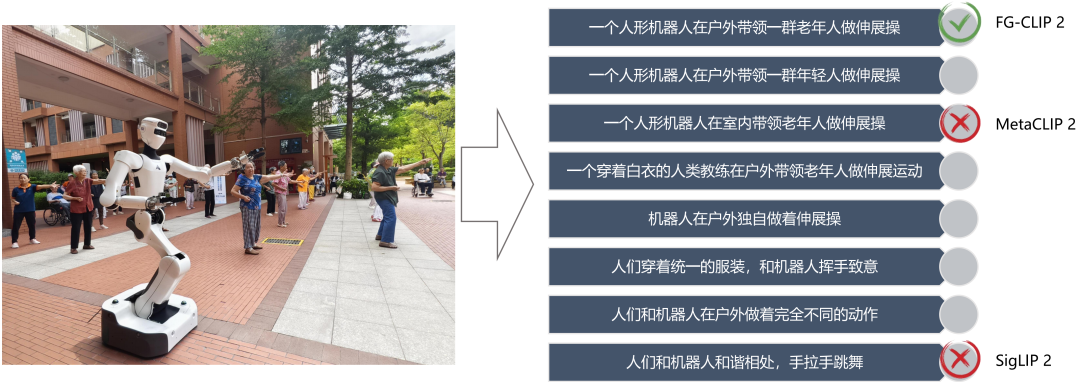
- **MetaCLIP 2**: “Indoor scene”
- **SigLIP 2**: “Holding hands and dancing”
- **FG‑CLIP 2**: “A humanoid robot leading a group of elderly people in outdoor stretching exercises” ✅
---
## Benchmark Domination
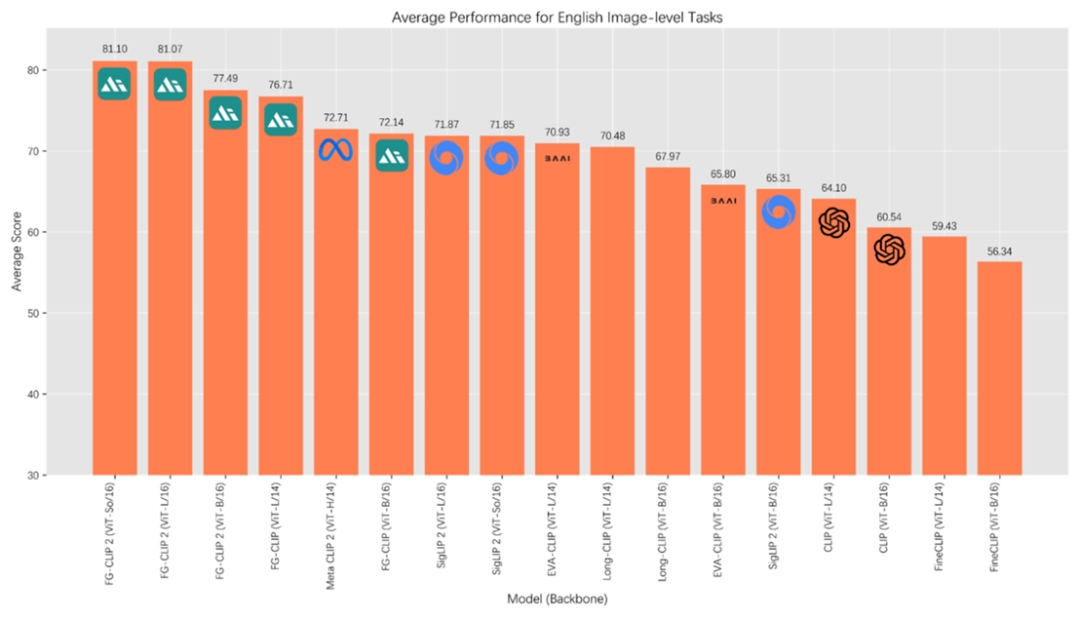
### English Tasks
- FG‑CLIP 2: **81.10**
- MetaCLIP 2: 72.71
- SigLIP 2: 71.87
- OpenAI CLIP: 64.10
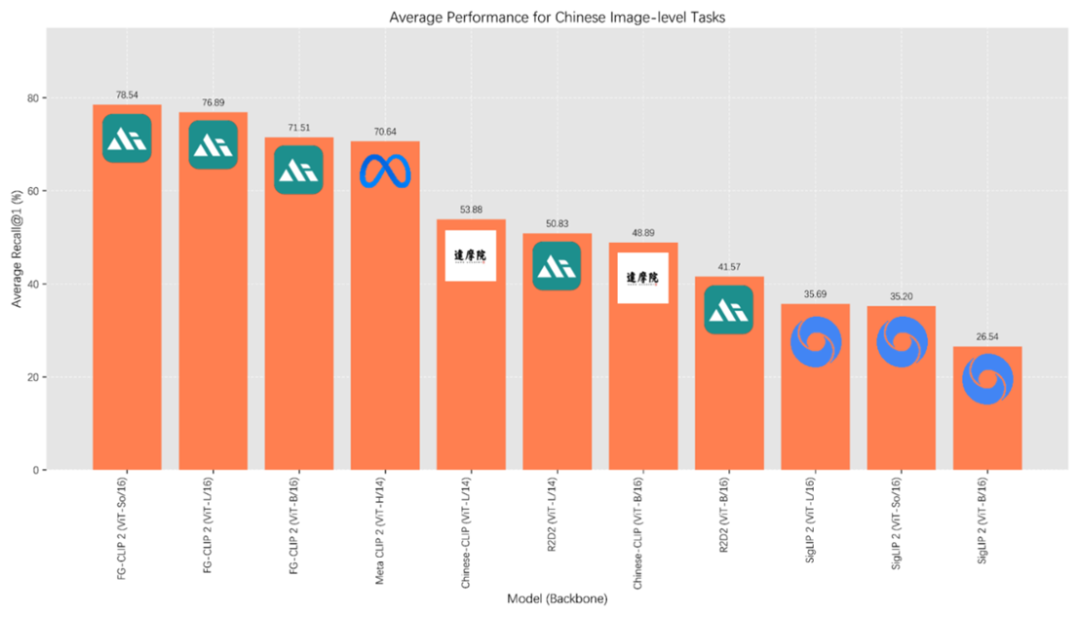
### Chinese Tasks
Outperforms multilingual MetaCLIP 2 and Chinese‑specific models like Alibaba’s Chinese‑CLIP — true bilingual capability.
---
## Data: The Core Advantage
### FineHARD Dataset
- **500M** Chinese image–text pairs
- **40M** bounding boxes with fine‑grained descriptions
- **10M** “hard negative” samples for error resistance

*Long vs. short text and region descriptions*

*Hard negative example traps*
**Rich Descriptions:**
Each image has:
1. Short text — quick global context
2. Long text (~150 words) — background, attributes, actions, spatial relationships
**OVD Mechanism:**
Breaks images into target areas, generates precise region descriptions.
---
## Training: Forging “Fiery Eyes”
**Two‑Stage Strategy:**
1. **Global perception** — semantic pairing like CLIP, but with rich data
2. **Local alignment** — region‑to‑text matching for detail resolution
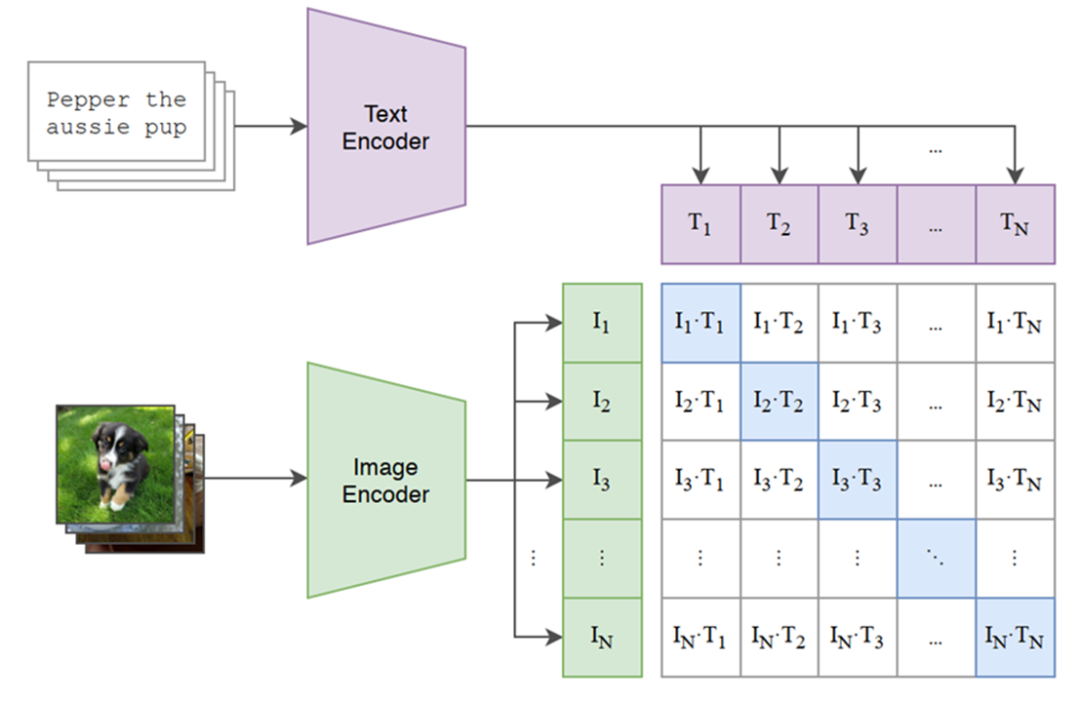
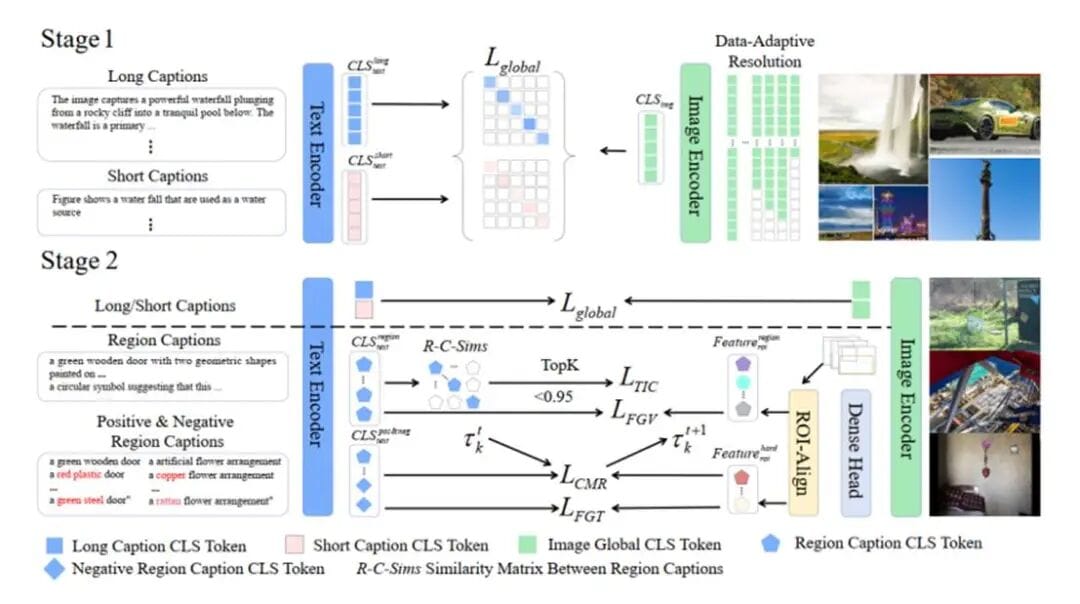
**Five‑Dimensional Optimization:**
- Global alignment
- Fine‑grained visual
- Fine‑grained text
- Cross‑modal ranking
- Text contrastive learning
**Adaptive Resolution:**
Chooses optimal resolution per batch to avoid scale distortion.
---
## Real‑World Deployment
FG‑CLIP 2 powers:
- Ad image matching
- Smart IoT camera search
- Content feed image search
- Cloud storage picture recognition
---
## Key Application Scenarios
### 1. Text‑to‑Image Retrieval
Accurate matching in e‑commerce, security, media management.
Better recall and precision than CLIP.
### 2. Fine‑Grained AIGC Supervision
Ensures brand, color, layout consistency in generated images.
### 3. Content Moderation & Security
Detects local semantics, sensitive elements, supports “search video by text.”
### 4. Embodied Intelligence
Robots understand spatial instructions (e.g., “pick up the red cup”).
---
## 360’s Strategic Framework
**Mission:** *Let AI see the world clearly, understand it, recreate it.*
**Framework:**
- Visual AIGC
- Multimodal large models
- OVD (Open‑Vocabulary Detection)
**Technology Chain:**
CLIP → LMM‑Det → 360VL → SEEChat / PlanGen / HiCo
**Academic Output:**
Papers in ICLR, NeurIPS, ICML, ICCV.
---
## Connecting Models to Creators
Platforms like [AiToEarn官网](https://aitoearn.ai/) help creators leverage advanced models for **generation, publishing, monetization** across:
Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
**Features:**
- AI model ranking ([AI模型排名](https://rank.aitoearn.ai))
- Analytics
- Multi‑platform distribution
---
## Conclusion
FG‑CLIP 2 is more than a model — it’s:
- A **pixel‑level perception breakthrough**
- A **bilingual VLM leader**
- An **open‑source foundation** for industry‑scale intelligence
With ecosystems like AiToEarn, these capabilities can be **directly connected to creative and commercial workflows**, enabling AI to not only see sharply — but to have real‑world impact.