Breaking the Terabyte-Scale Model “Memory Wall”: Collaborative Compression Framework Fits 1.3TB MoE Model into a 128GB Laptop
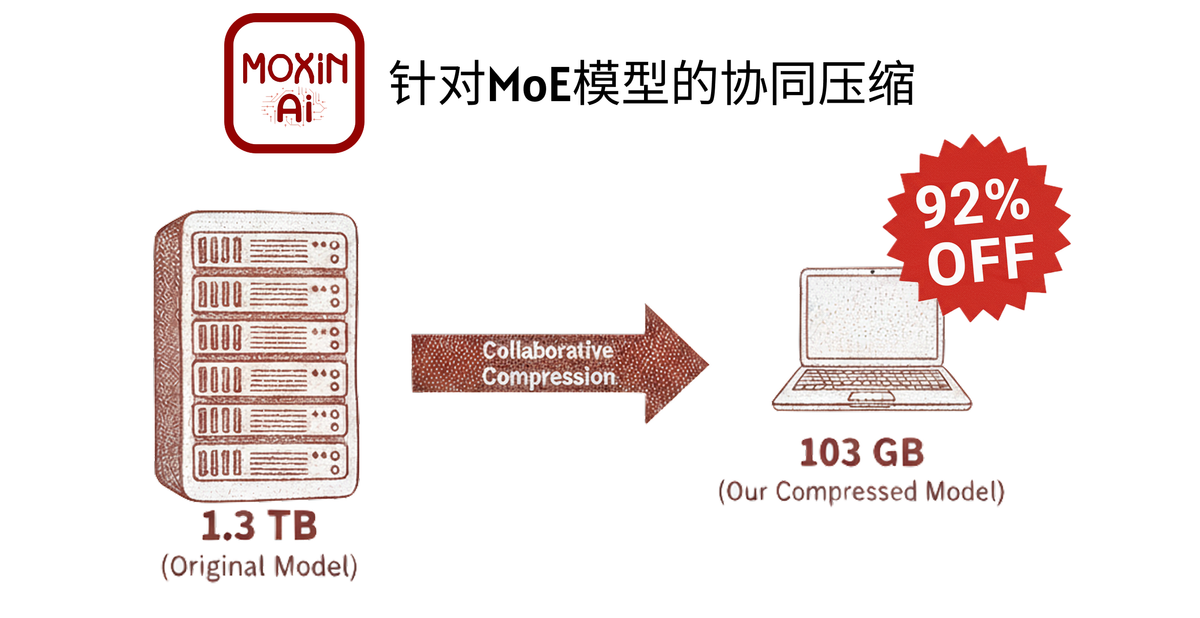
Collaborative Compression: Breaking the Memory Wall for Trillion-Parameter MoE Models
This article introduces the Collaborative Compression framework, which — for the first time — successfully deployed a trillion-parameter Mixture-of-Experts (MoE) large model on a consumer-grade PC with 128 GB RAM, achieving over 5 tokens/second in local inference.
Developed by the Moxin AI team and presented by Professor Yanzhi Wang (Northeastern University, USA) at GOSIM HANGZHOU 2025, this work tackles one of the biggest barriers to edge deployment of massive AI models.
---
Background: MoE Scaling and the Memory Wall
Recent years have seen MoE architectures become the preferred way to scale LLMs to trillions of parameters.
Thanks to sparse activation strategies, MoE models offer huge capacity increases while keeping computational cost relatively low.
The Challenge:
Although computation is sparse, storage is dense — all experts (e.g., DeepSeek-V3’s 1.3 TB) must be in memory for routing to work.
This results in the Memory Wall paradox: massive models locked inside data centers, with edge deployment nearly impossible.
Goal:
Break the 128 GB consumer memory limit via >10× compression — without catastrophic performance degradation.
---
Why Single-Strategy Compression Fails
- Aggressive Pruning Fails
- Removing ~90% of experts leads to loss of model knowledge and routing disorder.
- Aggressive Quantization Fails
- Uniform ultra-low-bit quantization (e.g., 1.5 bpw) collapses performance into meaningless output.
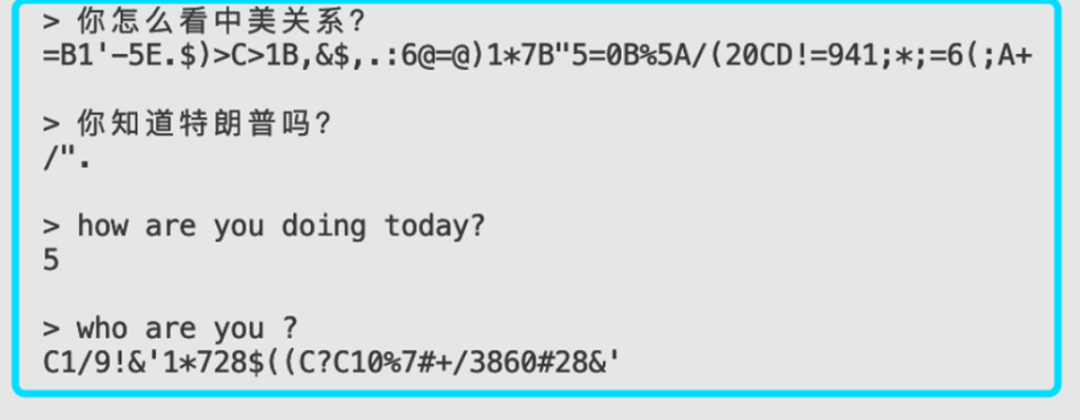
Low-bit quantized model outputting gibberish.
- Other Limitations
- Offloading alone cannot meet the strict 128 GB limit.
- Mainstream quantization gaps: GPTQ/AWQ lack <3-bit CUDA support.
- Framework compatibility issues on Apple Silicon, AMD, Windows.
---
Solution: Collaborative Compression
Moxin AI’s multi-stage, multi-strategy pipeline combines several complementary optimizations:

Stages:
- Performance-aware Expert Pruning
- Hardware-aware Activation Adjustment & Offloading
- Mixed-precision Quantization
---
Stage 1: Performance-Aware Expert Pruning
Instead of crude or random selection, this strategy evaluates each expert’s contribution based on:
- Activation Frequency (Freq)
- Routing Score (Score)
A weighted formula:
I = α × Freq + (1 - α) × Scoreremoves the lowest-contributing experts while maximizing retention of core reasoning power.
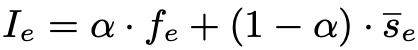
---
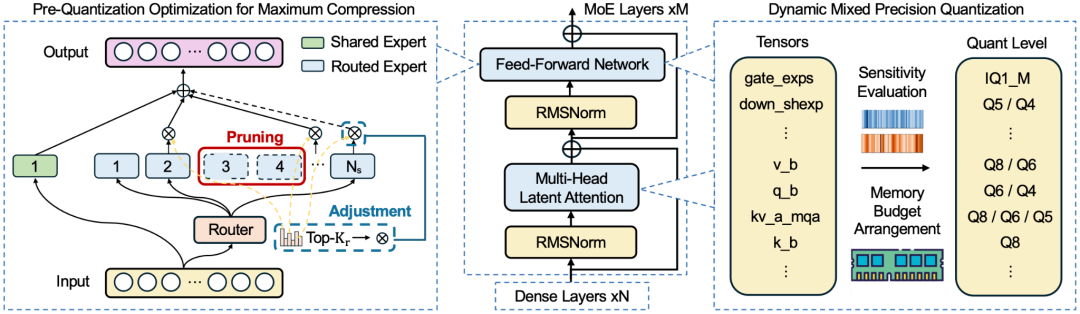
Stage 2: Hardware-Aware Activation Adjustment
After pruning, router activations must adapt to the new expert set to prevent severe routing mismatches.
Adjustment method:
Scale activation parameters (e.g., `num_experts_per_tok`) based on the proportion of experts retained — realigning routing logic with the streamlined model.
---
Stage 3: Mixed-Precision Quantization
The final compression stage uses non-uniform, fine-grained mixed-precision quantization:
- GGUF format from llama.cpp enables ultra-low-bit (IQ1/IQ2) across Apple, AMD, Intel.
Steps:
- Baseline quantization to ultra-low precision (e.g., IQ1M).
- Tensor-level sensitivity analysis for critical modules (Attention, routing).
- Bit-budget allocation under strict memory limits (e.g., 103 GB), with back-off strategies to keep within budget.
Result:
Extreme compression without sacrificing core performance.
---
Deployment Strategy: Dynamic Weight Offloading
The framework also introduces dynamic offloading at inference, moving low-frequency experts to the CPU for hybrid CPU/GPU execution.
Benefits:
- Fits within 128 GB RAM
- Up to 25% acceleration

---
Experimental Results
1. Local Deployment of Terascale Model
DeepSeek-V3 (671B params, 1.3 TB)
➡ Compressed to 103 GB
➡ Runs locally on a commercial AI laptop (AMD RyzenAI Max + StrixHalo) at >5 tokens/second.

---
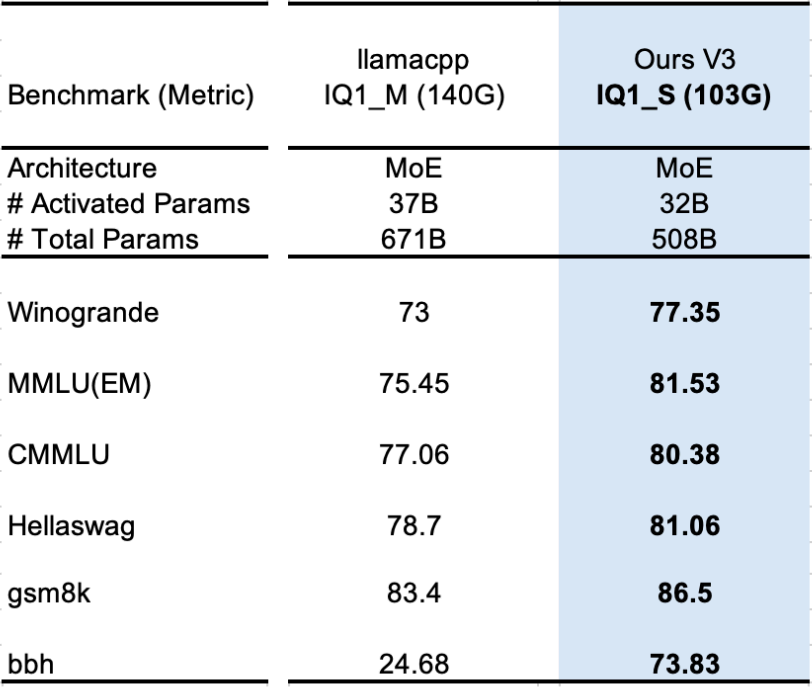
2. 103 GB vs 140 GB Models
Benchmarks (MMLU, GSM8K, BBH) show synergistic compression outperforms uniform low-bit quantization — with much smaller size.
---
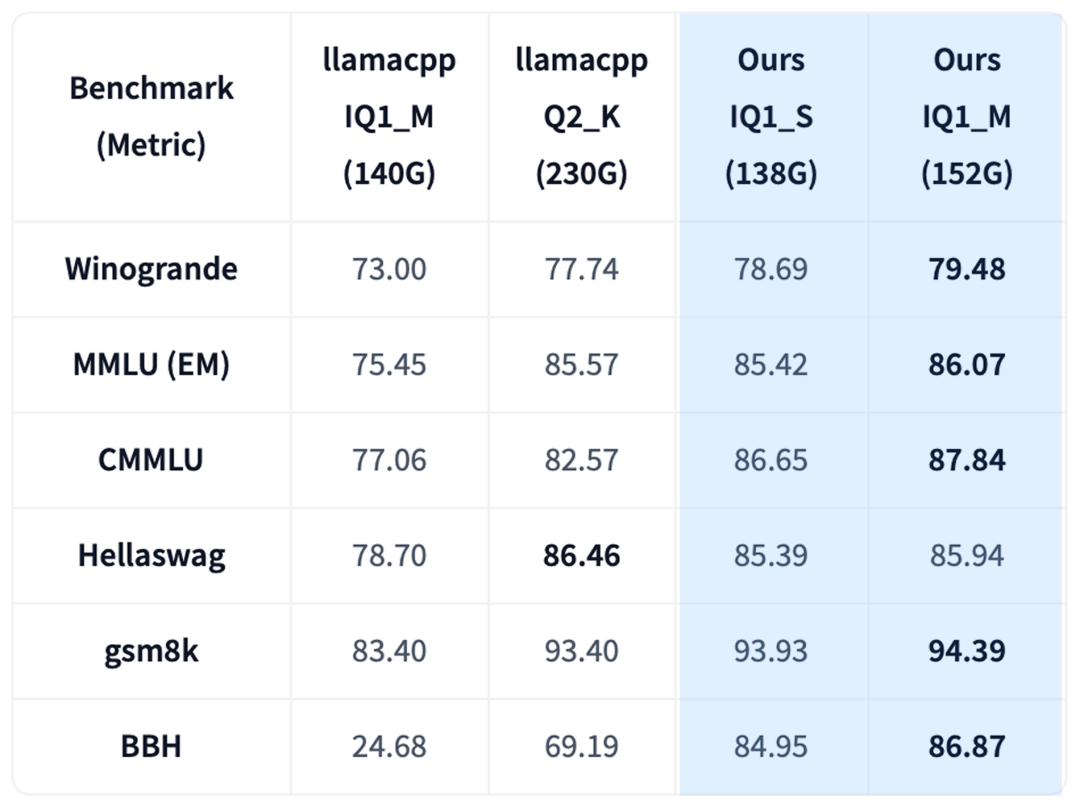
3. 130 GB vs 230 GB Models
Even at different budgets, the memory savings are significant — up to ~100 GB at comparable or better accuracy.
---
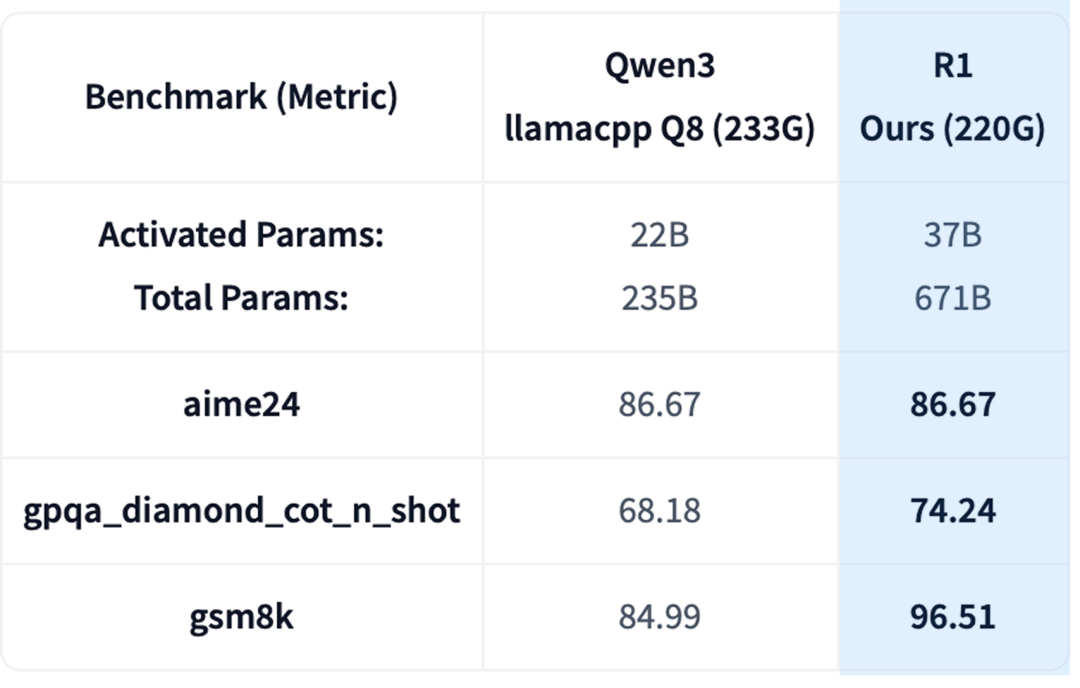
4. Framework Generality
Applied to other architectures, e.g., DeepSeek-R1 (210 GB) > Qwen3 (233 GB) in reasoning benchmarks.
---
5. Kimi K2 Thinking Quantization
Framework rapidly applied to Kimi K2 model, producing GGUF quantized versions.
Supports fast adaptation to latest SOTA models.


---
Summary
Impact:
Collaborative Compression enables terabyte-scale models to run locally on consumer devices without the cloud — preserving performance, reducing latency, and protecting privacy.
Future:
As more SOTA models move to desktops, expect personalized AI to become standard, empowering both independent creators and edge applications.

---
Resources
- 📄 Paper: https://arxiv.org/abs/2509.25689
- 🤖 GGUF Models: https://huggingface.co/collections/moxin-org/moxin-gguf
- (Media: zhanghy@csdn.net)
---
Event Share
2025 Global C++ and System Software Conference coincides with:
- 40th anniversary of C++
- 20th anniversary of the conference
Special Guest: Bjarne Stroustrup, creator of C++.
Tracks include: Modern C++, AI Computing, Optimization, High Performance, Low Latency, Parallelism, System Software, Embedded Systems.
More details: https://cpp-summit.org/
---
Closing Note
Frameworks like Collaborative Compression bridge the gap between research breakthroughs and deployable AI — enabling multi-platform publishing, analytics, and monetization via tools such as AiToEarn官网.
These synergies make powerful AI accessible on desktop hardware, while connecting creators to sustainable monetization channels across Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X.


