Building an ImageNet for Image Editing? Apple Open-Sources a Massive Dataset with Nano Banana

Apple Intelligence — One Year Later
Apple Intelligence has now been available for over a year, but outside of global markets (notably unavailable in China), its real-world usefulness remains limited.
Visual Generation Performance
When it comes to image generation, Apple’s style still tends to look something like this:

By contrast, in academic research, Apple often delivers cutting-edge work.
---
A Surprising New Dataset: Pico-Banana-400K
Apple’s latest project showcases this transformation — using Google’s Nano-Banana model to create a specialized ImageNet for visual editing.

This pairing of Nano-Banana with Gemini has ignited plenty of speculation:
In text-guided image editing, models like GPT-4o and Google’s Nano-Banana have proven exceptionally capable, performing high-quality edits while preserving the essence of the original.
Nano-Banana stands out as a milestone benchmark in this field.
However, the community still lacks a large-scale, high-quality dataset based on real images for image editing research.
---
Introducing Pico-Banana-400K
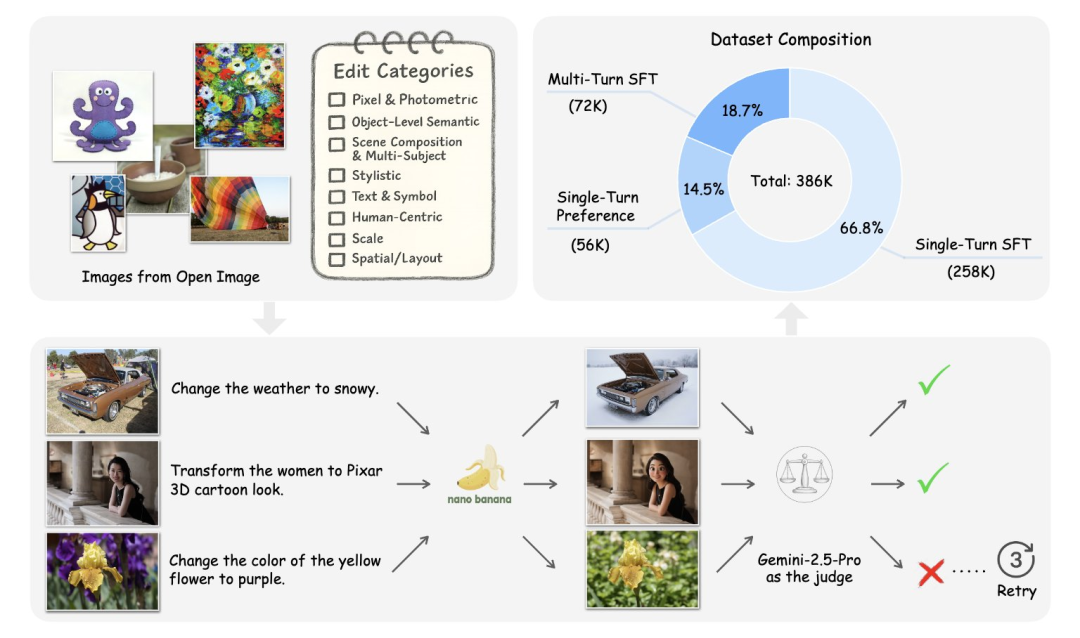
To address that gap, Apple’s researchers built Pico-Banana-400K — a 400,000-image instruction-based image editing dataset.

- Paper: Pico-Banana-400K: A Large-Scale Dataset for Text-Guided Image Editing
- Link: https://arxiv.org/pdf/2510.19808
This dataset was created using Nano-Banana to generate diverse edit pairs from OpenImages real-world photos.
Its key features include:
- Fine-grained taxonomy covering all editing types
- Multimodal LLM scoring + human verification for quality control
- Designed for both diversity and realism
---
Dataset Structure
Core SFT (Single-turn Supervised Fine-tuning) Subset
- 258,000 single-step successful edits
- Spans 35 editing categories
- Provides strong supervisory signals for instruction-following models
Additional Subsets for Advanced Research:
- 72K Multi-turn Editing Set
- Multi-step sequences (2–5 turns)
- Context-aware instructions from Gemini-2.5-Pro
- Enables research on iterative refinement and multi-step reasoning
- 56K Preference Set
- Triplets: original image + instruction + successful edit + failed edit
- Supports DPO and reward model training with contrastive failure data
- Long–Short Instruction Pairing Set
- For instruction rewriting & summarization research
This scale and task-rich design makes Pico-Banana-400K a robust foundation for next-gen text-guided image editing models.
---
Self-Editing & Self-Evaluation Pipeline
Apple didn't just release a dataset — they also built a fully automated pipeline:
- Nano-Banana handles editing
- Gemini-2.5-Pro evaluates results
- Failed cases are automatically retried until successful
- No human intervention required

---
Example: Single-turn Edit
Original (left) → Edited (right), covering:
- Photometric changes
- Object edits
- Stylization
- Scene/lighting adjustments
---
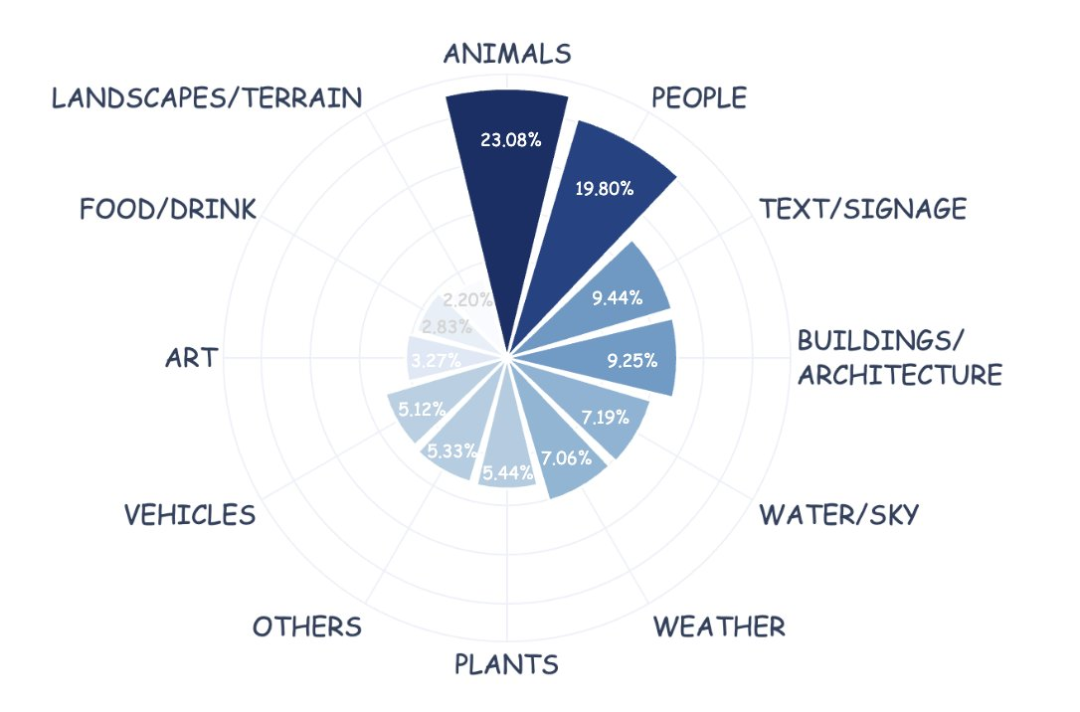
Editing Instruction Distribution
The dataset covers 35 real-world editing operations — essentially all Photoshop skills:
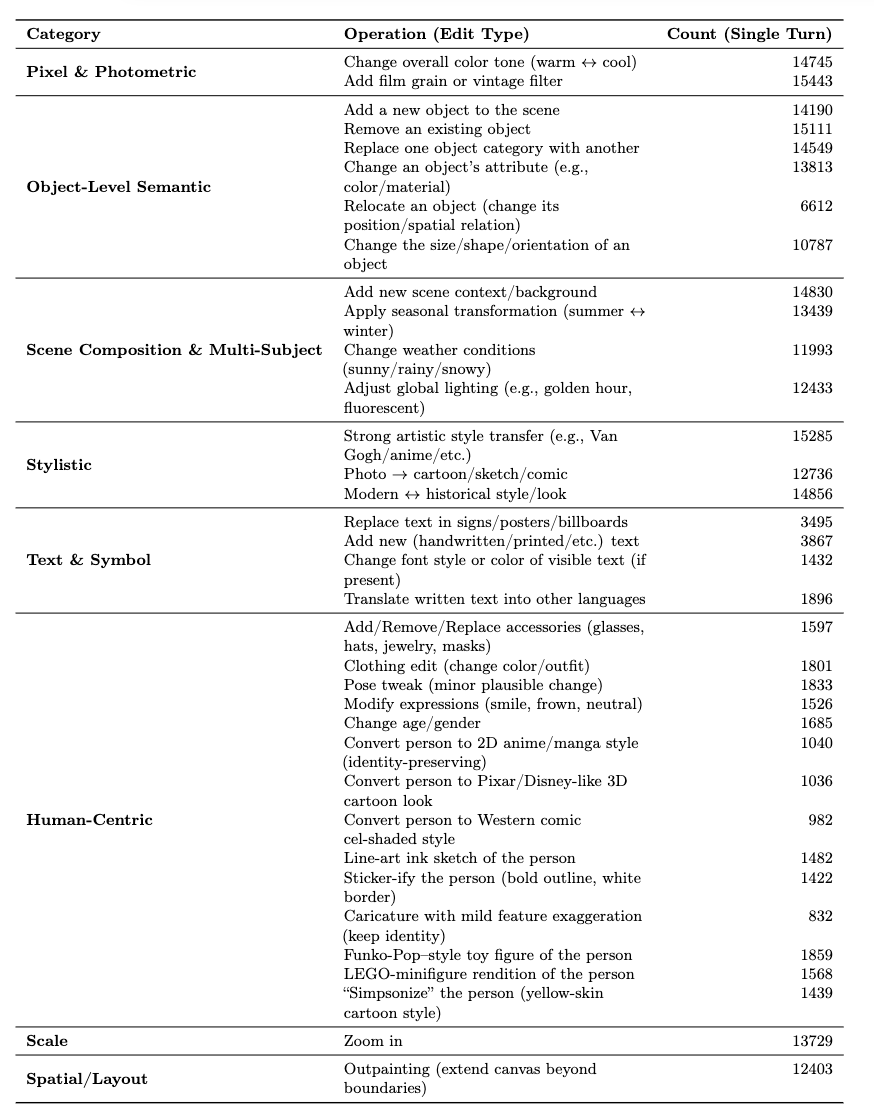
Each edit type is categorized, scored, and included only if instruction-compliant and visually acceptable within three attempts.
Failures are preserved as preference data — enabling models to learn what “better” looks like.

---
Preference Triplet Example
From left to right:
- Original image
- Instruction: e.g. move the pink and white straw into the leftmost glass
- Successful edit
- Failed edit
This preservation of failed attempts offers new opportunities for alignment and reward modeling:
- Identify common failure modes (geometry errors, artifacts, incomplete edits)
- Train models with Direct Preference Optimization (DPO)
- Improve judgment in multimodal systems
---
Data Analysis
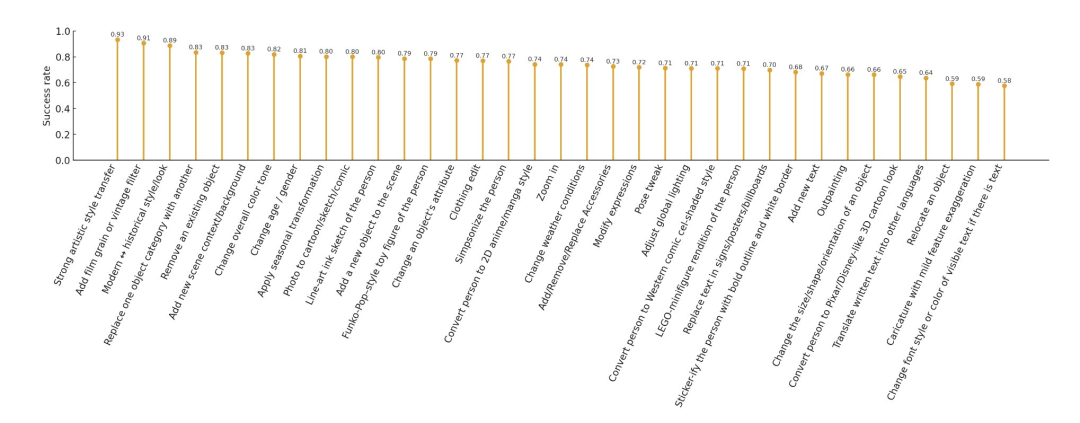
Success Rate Highlights
High Reliability (Global Edits & Stylization)
- Artistic style transfer: 0.9340
- Vintage effects: 0.9068
- Historical ↔ modern transfer: 0.8875
Moderate Challenges (Object/Semantic Edits)
- Object removal: 0.8328
- Category replacement: 0.8348
- Seasonal changes: 0.8015
Lowest Reliability (Precise Layout & Text)
- Object movement: 0.5923
- Orientation/size changes: 0.6627
- Outpainting: 0.6634
- Text font/style change: 0.5759
---
Summary of Contributions
- Large-Scale, Organized Dataset
- ~400K examples, 35-category taxonomy
- Automated + manual quality control
- Multi-Objective Support
- SFT samples, preference pairs for DPO/reward modeling
- Robustness and alignment research
- Complex Editing Scenarios
- Multi-round sequences (2–5 edits)
- Both detailed and concise prompts
Pico-Banana-400K proves AI can generate and verify its own high-quality training data without human supervision — marking a leap for multimodal learning.
---
The Broader Context: Monetization Platforms
Tools like AiToEarn官网 now bridge AI research and creative monetization:
- Cross-platform publishing (Douyin, WeChat, Bilibili, Instagram, etc.)
- Analytics & model ranking
- Open-source, creator-friendly design
For datasets like Pico-Banana-400K, such platforms enable global reach and feedback loops that improve multimodal AI performance.
---
Bottom line:
Layout accuracy remains the biggest challenge in multimodal AI, and Apple’s Pico-Banana-400K is poised to be a cornerstone resource for addressing it over the next decade.


