C3 Repository AI Code Access Control Best Practices: Code Review with Qwen3-Coder + RAG

# LLM + RAG Code Review in C3-Level Repositories
## Summary
This article details the **practical implementation** of an **LLM-based code review agent** in a **C3-level security** code repository. Due to strict security requirements and the prohibition of closed-source models, the solution is built on:
- **Qwen3-Coder**
- **RAG (Retrieval-Augmented Generation)**
- **Iflow**, with a Bailian Embedding–generated knowledge index
The **RAG knowledge base** is maintained within the same repository as production code, ensuring documentation and code remain synchronized.
**Workflow Highlights:**
- CI pipeline detects code changes and triggers AI review
- LLM performs:
- Code explanation
- Logical analysis
- Detection of:
- Concurrency defects
- Resource leaks
- Boundary errors
- Performance bottlenecks
- Compliance violations
Using a large-scale C/C++ block storage library as an example:
- Thousands of review sessions completed
- Deployed to unified storage code-gate platform
- Supports all repositories via platform integration
**Results:**
- AI detects logical risks often missed by human reviewers
- Intercepted dozens of high-risk defects
- Improved review efficiency and quality
**Current focus:** Accuracy optimization, false positive reduction, broader adoption, enhanced contextual understanding, automated fix suggestion generation.
The practice is **reusable for other code gate platforms** and AI-assisted programming tools.
---
## Human–AI Collaboration in Code Review
### Terminology
1. **RAG (Retrieval-Augmented Generation)**
Combines document retrieval with generative LLM capabilities by injecting retrieved external knowledge (documents, DB data) into prompts. Improves accuracy, timeliness, and reduces hallucination/security risks.
2. **Iflow CLI**
Internal adaptation of Gemini CLI, compatible with models like Kimi-K2 and Qwen3-Coder, suitable for C3-level secure environments.
3. **Qwen3-Coder**
Open-source **MoE programming engine** with:
- **480B parameters** (35B active)
- **256K context window**
---
### Application Scenario
**Why Code Review?**
Code review serves as a **fault-tolerant, enhancement-focused** task without replacing humans.
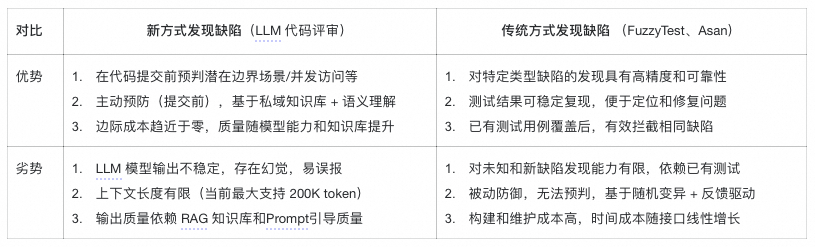
**Limitations of Traditional Review:**
- High cost and inefficiency
- Dependent on reviewer experience
- Misses deep logical defects in complex systems
**Limitations of Copilot-like Tools:**
- Syntax-level error detection only
- Weak contextual/logical reasoning
- Inability to detect sensitive, domain-specific issues without proprietary data
**Security Constraint:**
C3 classification prevents use of Cursor, Qoder, etc.
**Solution:**
A bespoke **code review agent** leveraging:
- **Qwen3-Coder**
- **RAG with private knowledge** (design docs, historical defects)
- **Iflow** integration into CI
- Triggered automatically on submission
- Provides:
- Logical check assistance
- Risk analysis
---
### Examples
**Example 1:** ~5000 LoC change
**Example 2:** ~1500 LoC change
Risk adoption rate: **80%** (boundary checks, division-by-zero, parameter mismatches)

Top adopted risks:
1. Missing boundary index check
2. Multi-thread concurrent access

---
### Advantages & Limitations
- **Acts as an assistant, not a replacement**.
- Strengths:
- Excellent logic summarization
- Frequent detection of boundary, concurrency, and resource leak issues
- Challenges:
- Output inconsistency
- False positives in risk analysis
- **Different strengths vs. traditional reviews**
---
### Related Tool Inspiration
In broader AI-assisted development, platforms like [AiToEarn官网](https://aitoearn.ai/) unify:
- AI content creation
- Workflow automation
- Analytics
- Multi-platform publishing
Potential inspiration for **single-pipeline CI→AI→distribution workflows**.
---
## Implementation: Qwen3-Coder + RAG
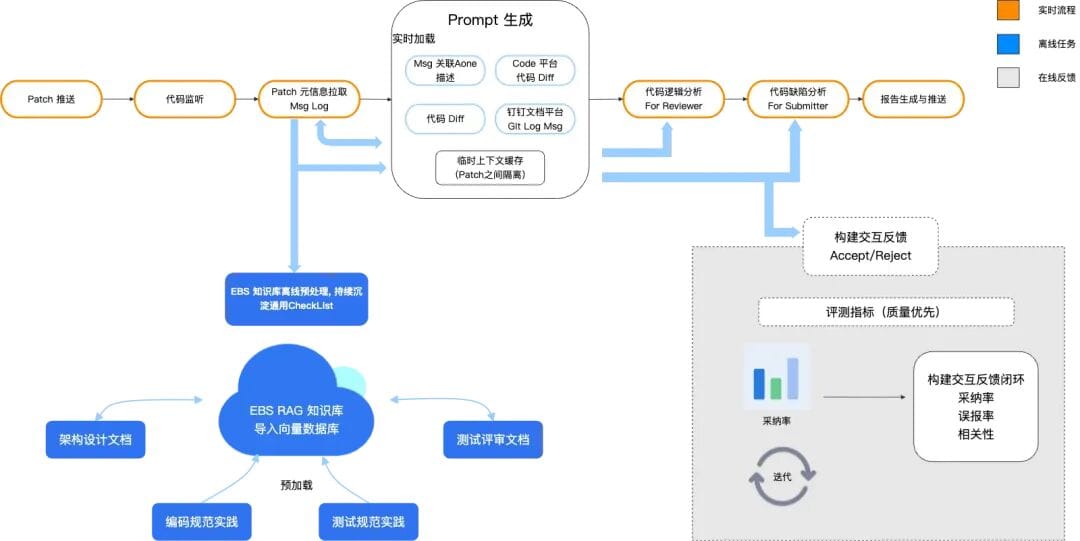
### Workflow Deployment
**Process:**
1. Webhook monitors code changes
2. Knowledge base vector retrieval
3. Prompt guidance + concatenation
4. Input to LLM
5. Output and results
**Implementation:**
- RAG + Iflow + Qwen3-Coder
- Bailian `text-embedding-v4` used to build FAISS-based indexes
---
### Knowledge Base Construction
- Reuse **existing** high-quality team documentation:
- System design
- Component intros
- Coding standards
- Testing protocols/templates
- Converted to LLM-friendly formats via **internal IdeaLab Gemini**
- **Manual validation before submission**

**Retrieval Mechanism:**
- RAG reads from local FAISS DB (Agent service)
- DB updated offline/scheduled
- Knowledge base in Git is for human sharing, not real-time AI retrieval
Example doc repo layout:ebs/
Documentation/
design/
test/
---
### Prompt Engineering
- **Template Design:**
- Role definition
- Principles
- CoT reasoning
- Output specs
- Few-shot examples
- **Interaction Roles:**
- *For Reviewer*: logic explanation
- *For Submitter*: risk analysis
- LLM summary
---
## Example: For Reviewer.md Structure
**Markdown Format**
- Title: `# EBS CodeReview For Reviewer Summary Report`
- Headings (`##`, `###`)
- Bold key info
- Bullet lists for clarity
**Sections:**
1. **Core Purpose:** concise problem/function description
2. **Reason/Principles:** technical background, detailed rationale
3. **Major Changes:** by module/file/function
4. **Detailed impact analysis:** per system area
---
## Example: For Submitter Report
### 1. Core Purpose
- **Goal:** Optimize EBS data sync (write consistency & recovery speed in multi-node replication)
### 2. Main Change Principles
#### BlockMaster
- Delta sync logic to reduce network load
#### Client
- Parallel write-ack for lower latency
#### Protocol
- New `SyncDeltaMessage` for backward-compatible negotiation
---
### 3. Impact & Risks
- Positive: Reduced CPU/net load, faster recovery
- Risks: More complex recovery logic, potential edge failures
---
### 4. Review Focus Points
- **Architecture:** State machine consistency
- **Performance:** Delta computation overhead
- **Exception handling:** Async callback safety
- **Code quality:** Protocol documentation clarity
---
### 5. Recommendations
- **High Risk:** Sequence verification before applying deltas
- **Medium Risk:** Optimize delta for low-change workloads
- **Low Risk:** Improve debug logging
---
### 6. Extended Note
RAG + LLM outputs can integrate with [AiToEarn官网](https://aitoearn.ai/) for multi-platform distribution.
---
## Analysis Guidelines
### Dimensions
- Logical correctness
- Boundary handling
- Resource release
- Concurrency safety
- Performance
- Security
- Maintainability
- Compatibility
- Extensibility
### Depth & Expression
- Cite files/functions/line numbers
- Clear, concise professional language
- Emphasize key findings
- Bullet lists for structure
---
## Analysis Workflow
1. Retrieve patch files:
- `/tmp/ebs_code_review.{PatchId}.merge_request_detail`
- `/tmp/ebs_code_review.{PatchId}.changed_files_list`
- `/tmp/ebs_code_review.{PatchId}.changed_files_diff`
- `/tmp/ebs_code_review.{PatchId}.doc`
- `/tmp/ebs_code_review.{PatchId}.reviewer.md`
2. Deep analysis: file-by-file & context-based
3. Supporting tools:
- `ebs_doc_rag`: coding standards + architecture info
4. Professional report:
- Categorize by risk
- Suggest fixes per issue
---
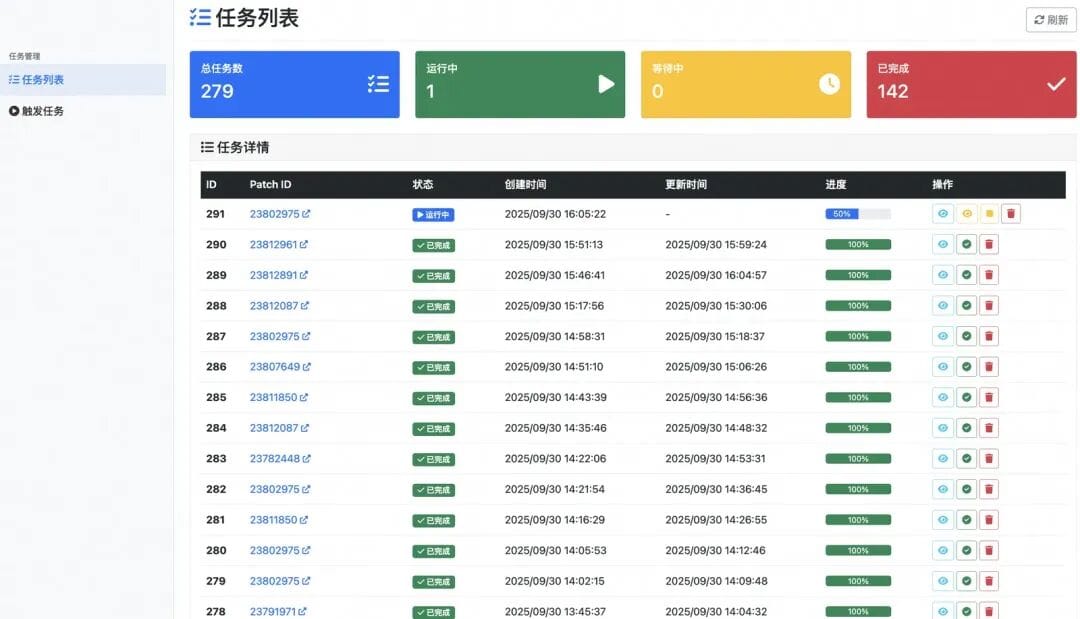
## CI Code Gate Integration
### Pipeline
- Collaborated with Storage Code Gatekeeping Platform
- Unified AI Agent workflow across repos

### AI Task List
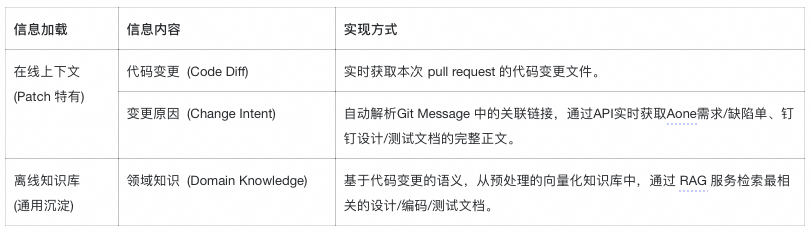
### Context Construction
Combines:
- **Online** context (short-term memory: patch data)
- **Offline** (long-term memory: KB)
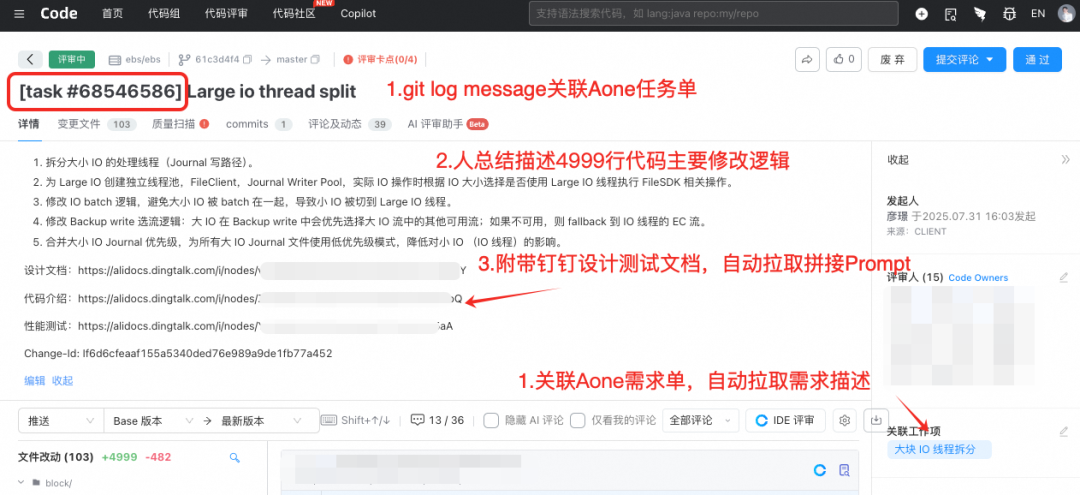
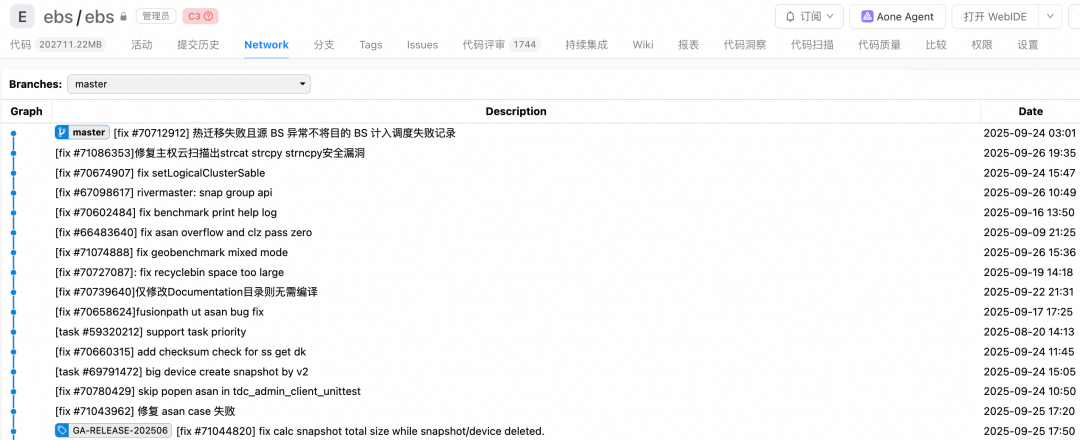
Commit–ticket linkage recommended:
---
## Review Effectiveness
Initial metrics:
- **Usage:** Thousands of reviews in EBS repo; ~10K model calls/day; 500M tokens/day
- **Efficiency:** ~10 min from PR → AI first comment
- **Problem scope:** From coding errors to concurrency/resource issues
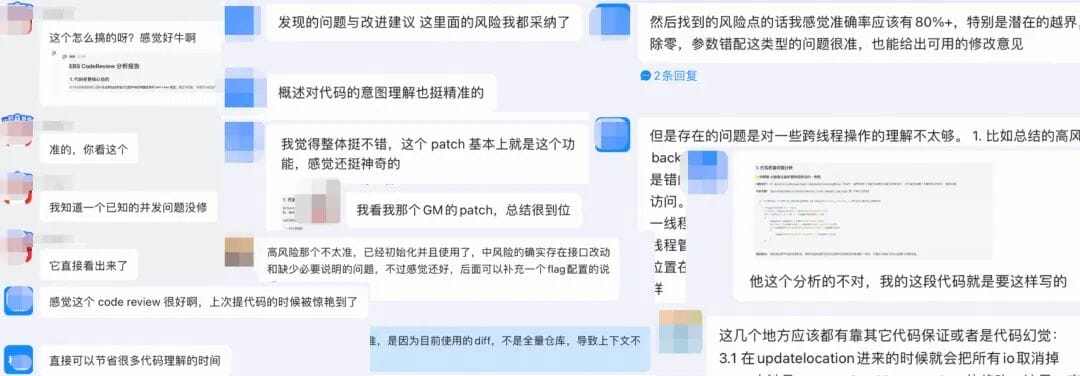
Feedback:
- Reviewer role: Strong code logic summaries
- Submitter role: Mixed risk detection acceptance
---
## Best Practices
**Setup Tips:**
- Link commits to requirements/bugs
- Write clear Git log messages
- Periodic sampling of review outputs
**Prompt Context:**
Quality of **context + prompt** strongly affects performance.
Recommendations visual:

---
## Maintenance Experience
"Optimal" doesn't always mean "effective" — practical tuning insights:

---
## Continuous Optimization & Reuse
### Reuse Scenarios
- **Horizontal:** Plug-in atomic AI review capability for all repos/IDE plugins
- **Vertical:** RAG KB reuse for test design, case generation, failure analysis
### Optimization Directions
- Feedback–evaluation–optimization loop with regression/A-B validation
- Variables: model, prompt, KB, parameters
Parallel to [AiToEarn官网](https://aitoearn.ai/)’s measurable iteration in multi-platform publishing — the same principles apply to engineering AI review workflows.
---