Cambridge Unveils the Black Box of LLM Failures — Reasoning Isn’t the Problem, Actions Are

New Intelligence Source — October 13, 2025, 17:51 Beijing


---
New Intelligence Report
Overview
> Why do large models tend to fail at long-horizon tasks?
> Some experts suspect this reveals an "illusion of thought." A joint study by the University of Cambridge and partners found the root issue lies not in reasoning ability, but in execution capability.
---
Example:
- During debugging in Cursor, Gemini entered a self-blame loop, repeating “I am a disgrace” 86 times.
Despite big strides in reasoning, such loops fuel doubts about true intelligence.
---

Key Study: The Illusion of Diminishing Returns
Paper: https://arxiv.org/pdf/2509.09677
Core Finding:
- Failures often stem from execution breakdowns, not reasoning failures.
- Slight boosts in single-step accuracy can exponentially increase task length before failure.
New Phenomenon: Self-conditioning
- Mistakes embedded in context cause the model to replicate errors step after step.

---
1. Why Long-Horizon Tasks Fail
Measuring Step Capacity
Industry focus shifts toward agents that complete entire projects.
Key Question: How many steps can a large model reliably execute?
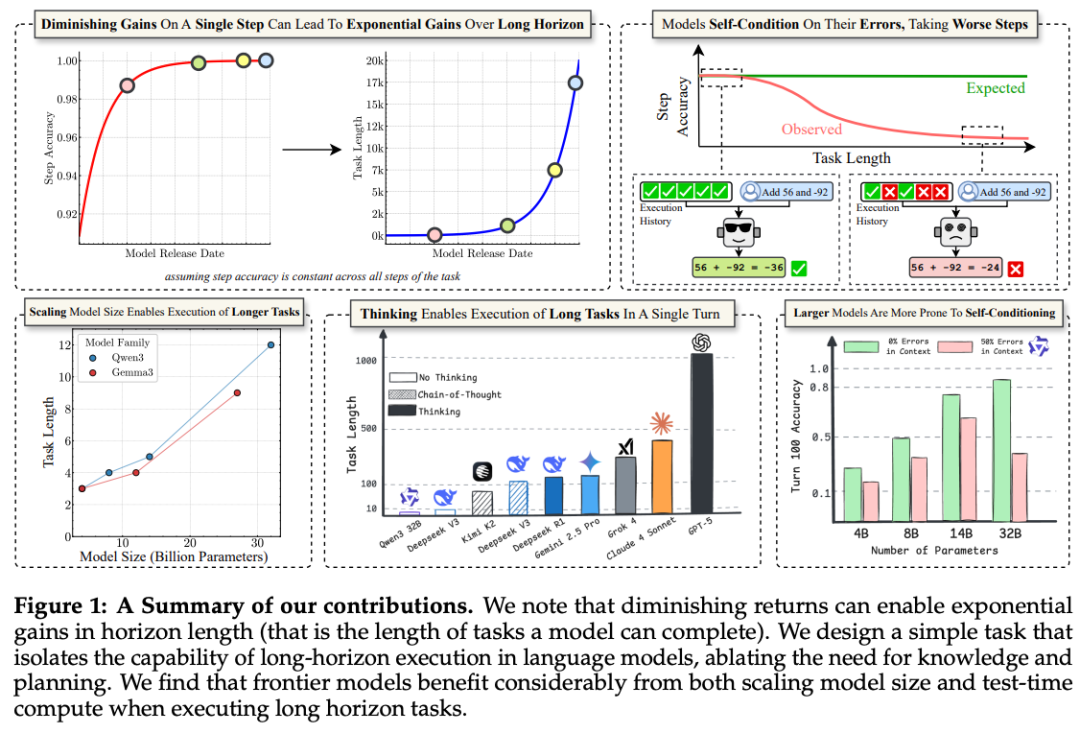
Studies show that:
- Models follow multi-step instructions well initially.
- Failures grow with task length, due to execution degradation.
- Execution stability needs more research attention.
---
2. Execution Metrics

Researchers measured:
- Step Accuracy — Correct state updates from step i–1 to step i, regardless of prior-step correctness.
- Turn Accuracy — Correct updates from turn t–1 to turn t.
- Turn Complexity (K) — Steps required per turn.
- Task Accuracy — Whether all steps are correct until task completion.
- Horizon Length (Hs) — Step count until success falls below a set probability threshold.
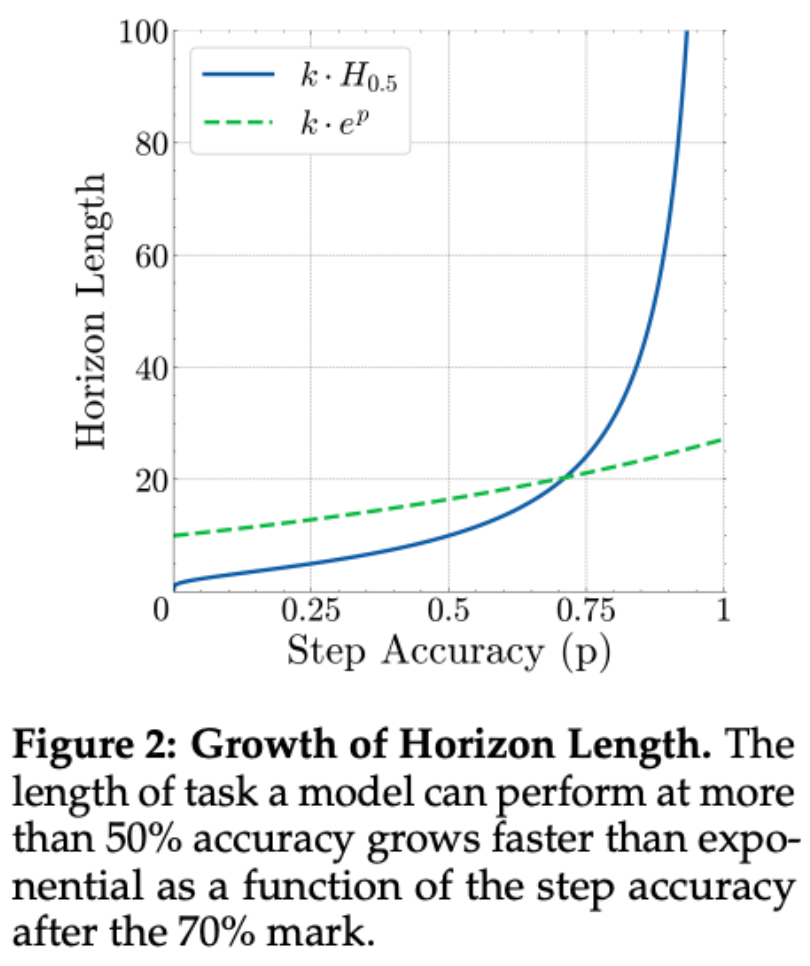
> Finding: Task length grows faster than exponentially when single-step accuracy exceeds 70%.
---
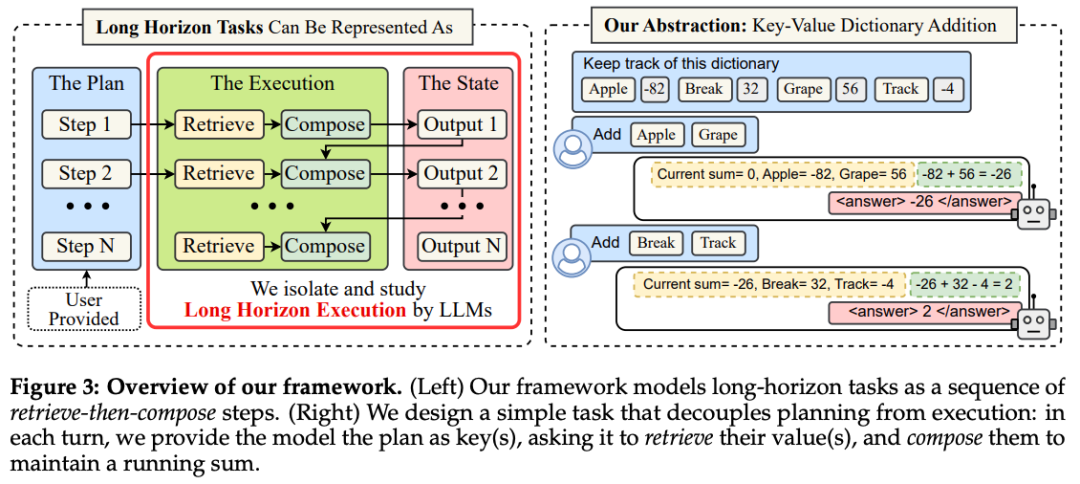
3. Decoupling Planning from Execution
Testing Only Execution Power
- Feed the model explicit plans and required knowledge.
- Measure ability to run all steps accurately.
Example: Flight booking involves sequential steps — opening details, checking times, applying discounts, weighing trade-offs.
Even with perfect plans & knowledge, models fail on extended sequences.
---
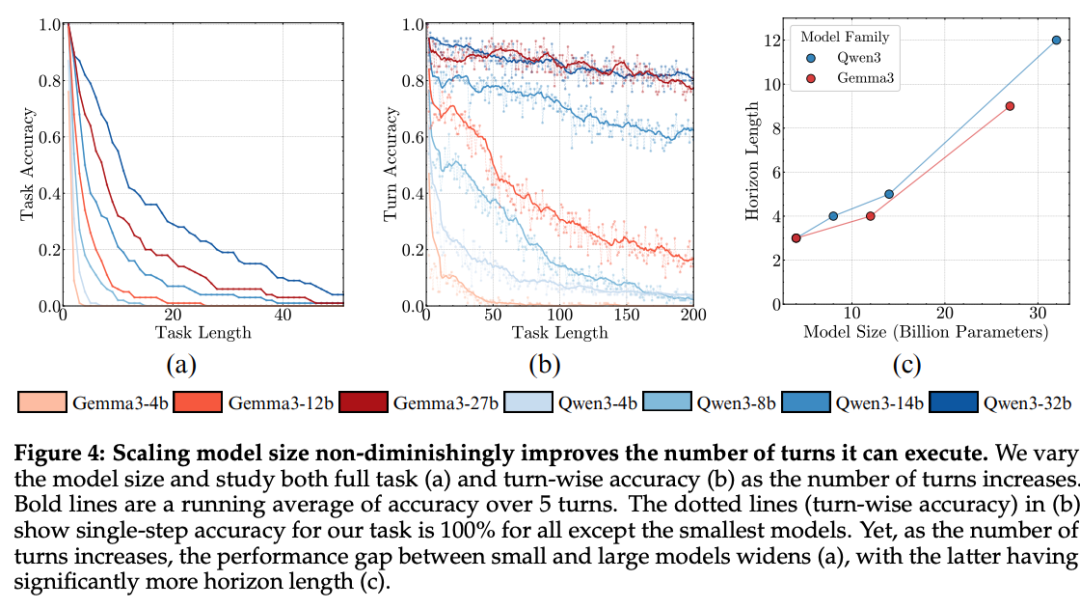
Experimental Results (Figure 4):
- Initial step accuracy often at 100%.
- Accuracy drops sharply within a few turns.
- Larger models (Qwen3-32B) still fall below 50% accuracy by turn 15.
Key Conclusion:
> Long-horizon execution is inherently hard, even without reasoning or knowledge demands.
---
4. Scaling Model Size

Result:
- Bigger models sustain accuracy longer → Horizon length scales with model size.
- Scaling benefits remain strong; challenges persist.
---
5. Self-conditioning Effect
Two Hypotheses:
- Long-context degradation — Accuracy loss simply from extended input length.
- Self-conditioning — Past mistakes bias future outputs toward failure.
Method: Counterfactual context injection
- Artificial histories with controlled error rates.
- Comparing error-free vs. error-injected contexts reveals impact of self-conditioning.
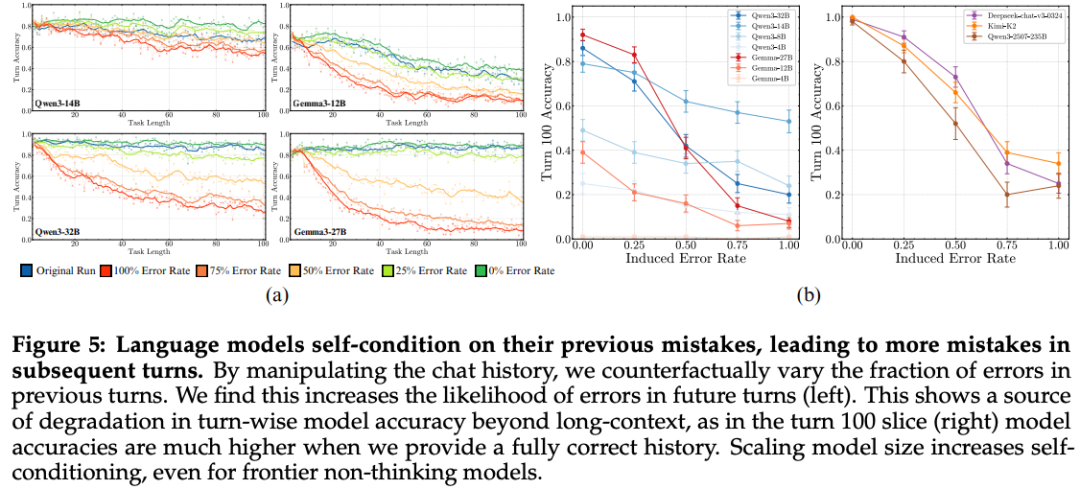
Findings:
- Both effects degrade performance.
- Self-conditioning persists despite large model scale.
- Long-context issues can be mitigated by scale; self-conditioning cannot.
---
6. Mitigation via "Thinking"

Enabling reason-first, act-later thinking mode in Qwen3:
- Eliminates self-conditioning.
- Maintains stable accuracy regardless of past error rates.
Reasons:
- RL training focuses on task success, not token likelihood continuation.
- Strips prior thinking traces, isolating each reasoning cycle.
---
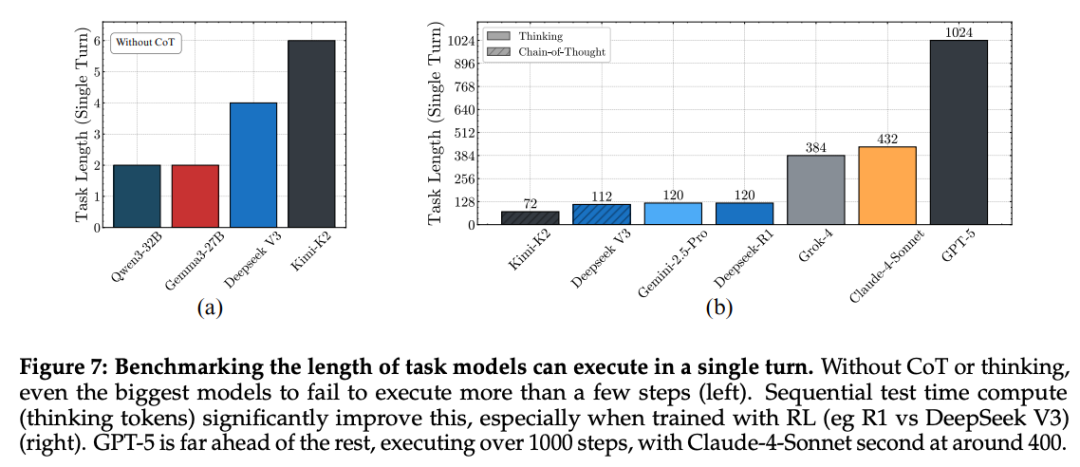
7. Benchmarks for Thinking Models
- Less susceptible to early error propagation.
- Longer single-turn task execution.
Examples:
- DeepSeek-V3 (no CoT) → fails at 2 steps
- DeepSeek-V3-R1 (Thinking mode) → 200+ steps
- GPT-5 Thinking → 1000+ steps
- Claude-4-Sonnet → ~432 steps

Ref: https://x.com/arvindh__a/status/1966526369463951424


---
8. Practical Implications
Platforms like AiToEarn bridge AI generation with automated multi-platform publishing and analytics.
- For researchers: Share benchmarks, insights globally.
- For creators: Monetize research-based content.
- Ecosystem supports Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter.
Learn more: AiToEarn官网, AiToEarn博客, AI模型排名
---
Read the original article | Open in WeChat
---
Key Takeaways
- Long-horizon execution is a bigger challenge than reasoning for LLMs.
- Scaling improves long-context handling but not self-conditioning.
- Thinking modes can fully remove self-conditioning.
- Future agent systems should be benchmarked by maximum reliable execution length, not just reasoning quality.


