Can AI Perform “Pilgrimage” Tours? New Multimodal Evaluation Benchmark VIR-Bench Released
From Anime Pilgrimages to AI-Powered Travel
Many of us have felt that spark:
- Watching an anime you love, you suddenly want to visit its real-life locations.
- Seeing a beautifully edited travel vlog, you bookmark it, hoping to follow that exact route someday.
Travel combined with video inspires curiosity and a desire to explore.
Now imagine: what if AI could automatically analyze these travel videos, tell you “which places were visited”, “in what order”, and even generate an instant, personalized itinerary?
This is more than a pop culture fantasy — it’s a realistic scenario for multimodal large language models (MLLMs).
---
Introducing VIR‑Bench
Researchers from Waseda University (Japan), CyberAgent, and the Nara Institute of Science and Technology have developed VIR‑Bench — a benchmark to evaluate whether AI can truly grasp the geographical and temporal structure in travel videos.
The core question:
> “Where did I come from? Where am I going?”

---
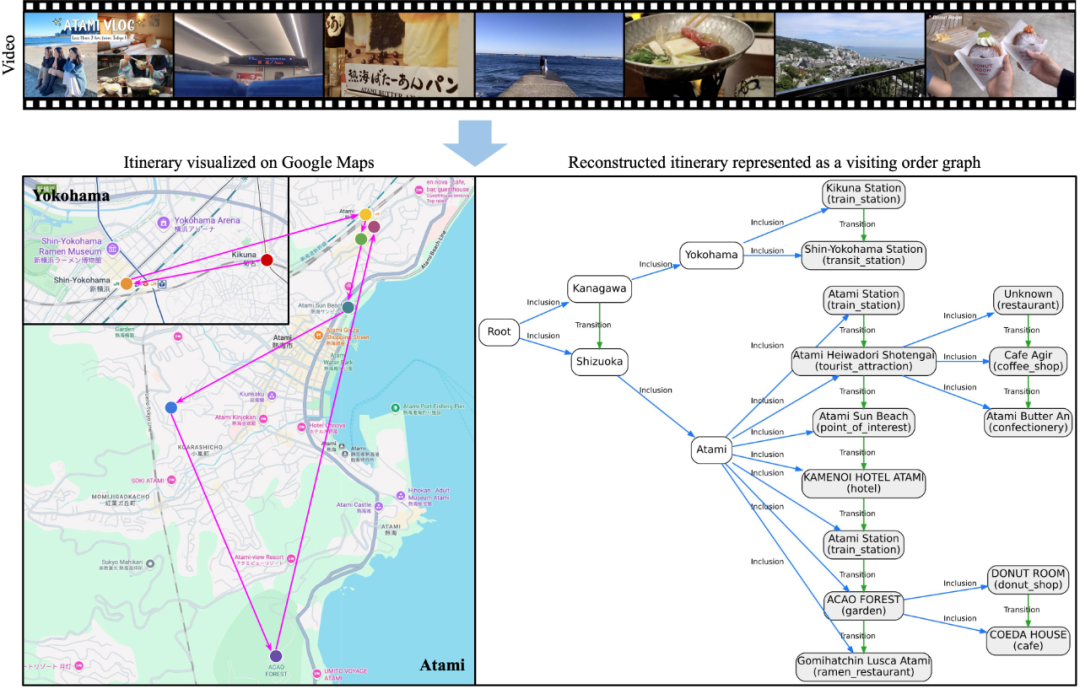
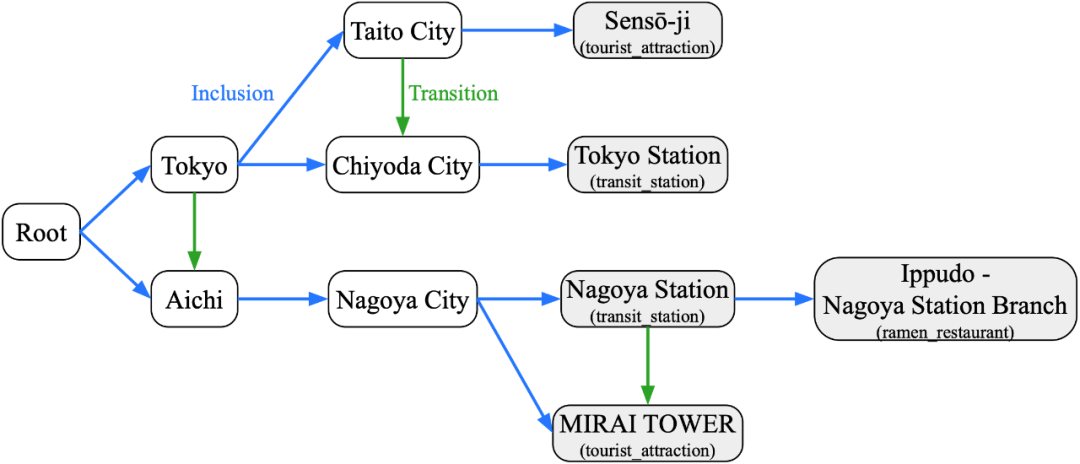
Task Overview — Itinerary Reconstruction
Objective: Automatically produce a visiting order graph from a travel vlog.
A visiting order graph is a directed graph with:
- Nodes: visited locations in three hierarchical levels — Prefecture → City → Point of Interest (POI).
- Inclusion edges: “A contains B” (e.g., City contains POI).
- Transition edges: chronological travel from one node to another within the same level.
This requires combining:
- Location recognition — identify each place visited.
- Temporal sequencing — determine the order of visits.
- Spatial reasoning — map containment relationships.
---
Subtasks
To simplify evaluation, the authors split the problem into two subtasks:
- Node Prediction
- Input: travel video.
- Task: list all visited prefectures, cities, and POIs.
- Edge Prediction
- Input: video + unordered node list.
- Task: identify all inclusion edges and transition edges.
This approach allows separate testing of:
- Geographic recognition ability
- Temporal reasoning ability
- How these abilities combine in practice
---
Dataset Details
Scale & Scope:
- 200 Japan travel vlogs
- 3,689 POIs across 43 prefectures
Annotation Process:
- Human annotators marked start/end times for each POI with Google Maps links.
- Verification by a second annotator.
- Automated generation of visiting order graphs.
---
Why It Matters
Applications could include:
- AI travel apps that watch your videos and map your trip automatically.
- Interactive itinerary generation for vlog creators.
- Synchronization with maps, timelines, and monetizable content platforms.
Platforms like AiToEarn already integrate AI content generation, multi-platform publishing, analytics, and model ranking — turning ideas like VIR‑Bench into sustainable creative tools.
Explore:
---
Experimental Findings
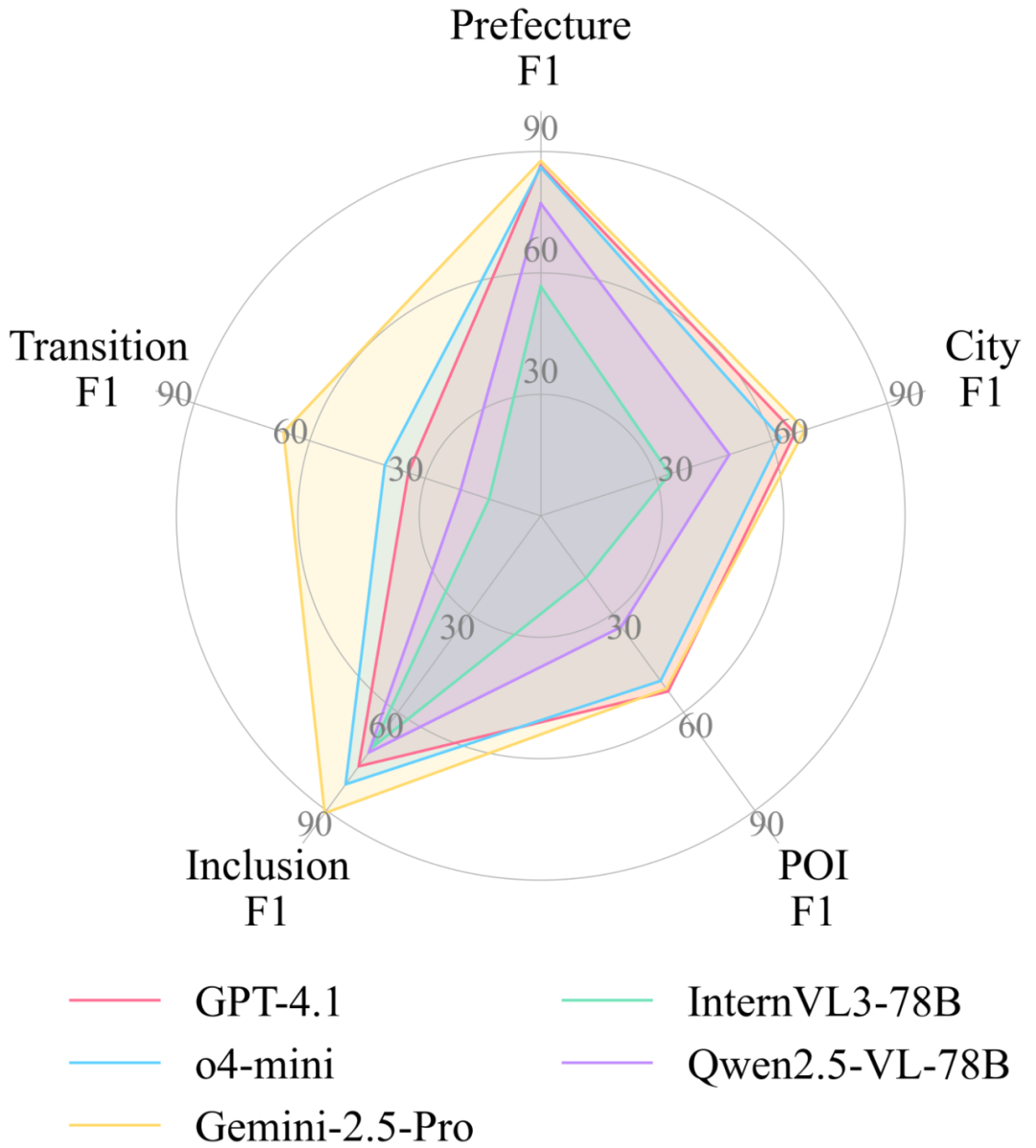
Key Insights:
- Open-source models lag behind commercial ones (especially in POI node recognition and transition edge prediction).
- Transition edge prediction is the hardest challenge — many models misinterpret constraints (edges only exist between nodes at the same level).
- Model size matters — bigger models perform better in edge prediction.
- Geo-relevant pretraining boosts POI recognition accuracy.
- Chain-of-Thought (CoT) reasoning helps edge prediction much more than node prediction.
- Audio input significantly improves performance (e.g., Gemini‑2.5‑Pro).
Ablation Insights:
- More input frames = more travel clues.
- Longer reasoning chains = better sequence reconstruction.
- Audio provides semantic hints for location and order.
Despite these gains, even top models like Gemini‑2.5‑Pro still make many errors — showing how challenging long-range temporal and geographic understanding is.
---
Tables
Table 1: Node Prediction
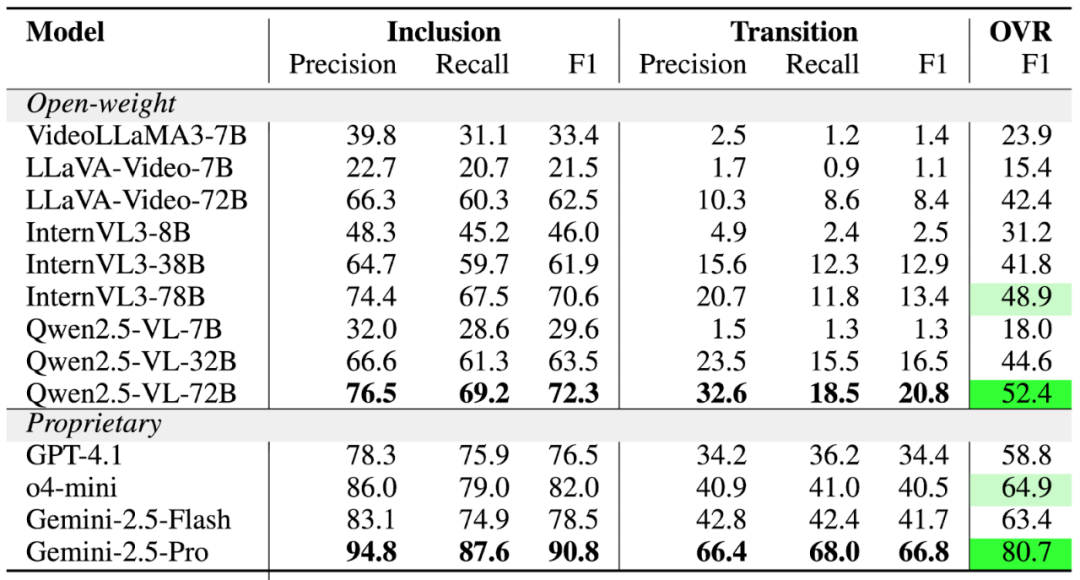
Table 2: Edge Prediction
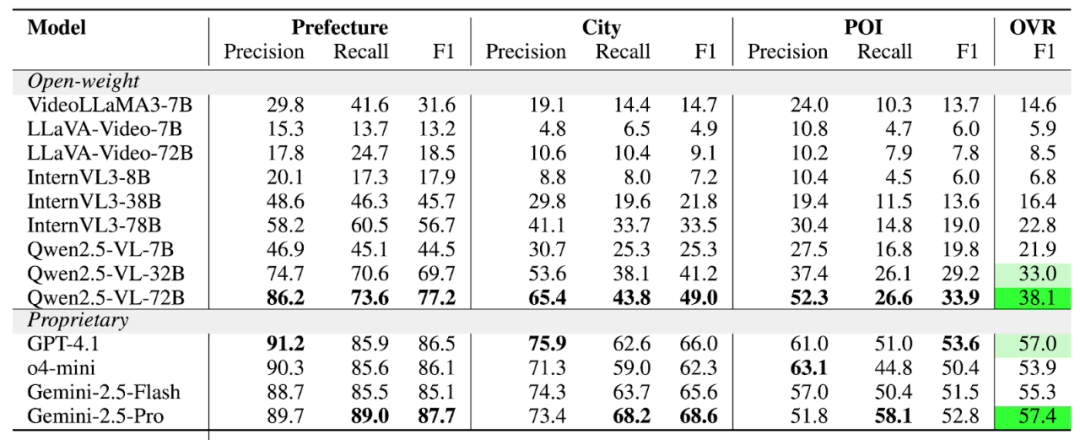
---
Conclusion
VIR‑Bench is more than a benchmark — it’s a bridge toward future AI applications requiring joint understanding of where and when.
Potential impacts:
- Robotics: route comprehension and planning.
- Autonomous driving: decision-making in dynamic environments.
- AI content tools that convert raw travel footage into mapped, shareable experiences.
Current challenge:
> Large models still struggle with long-range reasoning and spatiotemporal integration.
Growth path:
- Stronger geo-spatial awareness
- Reliable temporal logic
- Enhanced multimodal fusion
With these advances, AI will progress from simply watching videos to truly acting within the world.
---
For developers and creators exploring multimodal spatiotemporal AI, platforms like AiToEarn官网 offer a practical way to publish and monetize innovations across:
Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).
---
Would you like me to also redesign the visiting order graph diagram in a simplified style so it’s easier for general readers to understand? That could make your Markdown even more reader-friendly.



