Can Reading Countless Books Help Large Models “See” the Visual World? Meta Reveals the Origins of LLM Visual Priors

How LLMs Learn to “See” Without Visual Input
A Large Language Model (LLM) trained exclusively on text — without any visual data — can still develop prior abilities transferable to vision tasks.
This surprising discovery comes from a recent paper by Meta Superintelligence Labs and the University of Oxford.
---
Study Overview
Researchers conducted an extensive 33-page investigation featuring:
- 100+ controlled experiments
- 500,000 GPU hours of computation
- Systematic analysis of how visual priors emerge in LLMs
The study introduces two categories of visual priors:
- Reasoning Priors
- Perception Priors
It also proposes a text-only pre-training recipe that “plants the seeds” of visual ability long before the model ever encounters visual data.
---

Quick Links:
- Paper Title: Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
- Paper PDF: https://arxiv.org/pdf/2509.26625
- Project Page: https://junlinhan.github.io/projects/lsbs/
---
Core Insight
Two Distinct Sources of LLM Visual Priors
Visual priors are not a single ability — they consist of:
- Reasoning Prior
- An abstract, cross-modal general ability
- Learned from reasoning-rich data such as code, mathematics, and academic papers
- Transfers well to complex vision tasks
- Comparable to humans developing logical skills before applying them to visual problem-solving
- Perception Prior
- Concrete recognition abilities (e.g., color, shape, object names)
- Emerges gradually from broad, diverse text corpora
- Highly sensitive to visual fine-tuning and vision encoder choice
---
Key Finding
> Massive reasoning data drives gains — while visual descriptions saturate quickly.

Experimental Approach
Researchers used an adapter-style multimodal pipeline:
- Text-only pre-training of multiple decoder-based LLMs (following Llama-3 architecture, \(340M to 13B parameters; focus on 3B and 7B\)).
- Integration stage: visual alignment + supervised fine-tuning.
- Measurement of visual priors in downstream tasks.
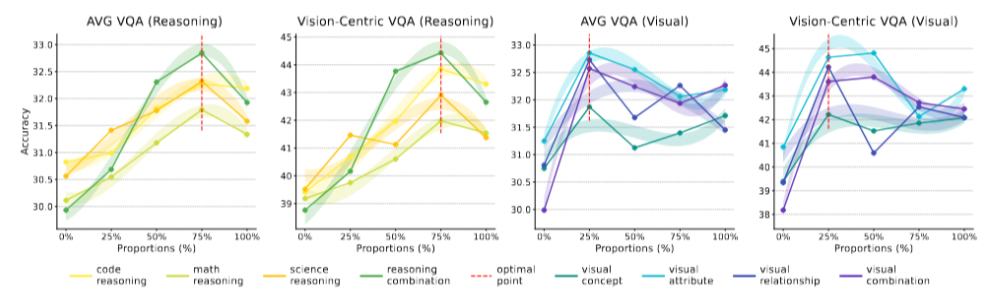
Six conclusions and three hypotheses emerged. Highlights include:
- Tracing Capability Origins
- Models trained on code, math, and academic text excelled in visual-reasoning-heavy tasks (e.g., Vision-centric VQA).
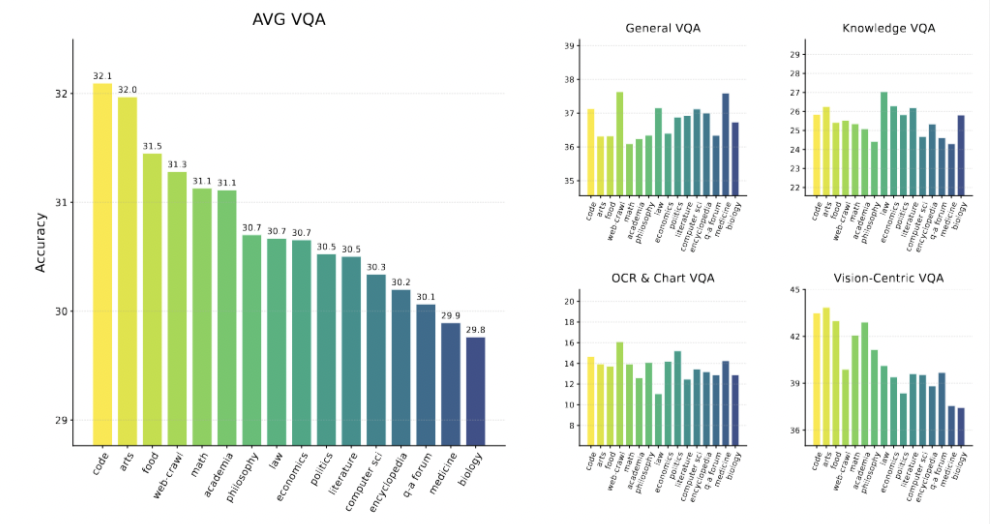
- Reasoning Data Matters Most
- Increasing reasoning-intensive text (up to ~75% of training data) significantly boosts downstream visual reasoning.
- In contrast, visual-descriptive text (color, shape, locations) yields rapid early gains but plateaus quickly.
---
Implications for Multimodal AI Development
Insights like these guide better pre-training strategies and practical workflows.
Platforms such as AiToEarn官网 provide a global, open-source ecosystem where creators:
- Generate AI content
- Publish across multiple platforms (Douyin, Bilibili, YouTube, Instagram)
- Analyze performance via dashboards
- Rank models via AI模型排名
---
Reasoning vs. Perception: Independence and Dependency
- Reasoning priors:
- Universal capability
- Independent of vision encoder choice
- Strong reasoning during pre-training improves multimodal reasoning later
- Perception priors:
- Dependent on fine-tuning data and vision encoder features
- Emerge later in the training pipeline
---
In short:
To nurture strong visual potential in an LLM — train its “mind” with logic, math, and code rather than flooding it with raw visual descriptions.
---
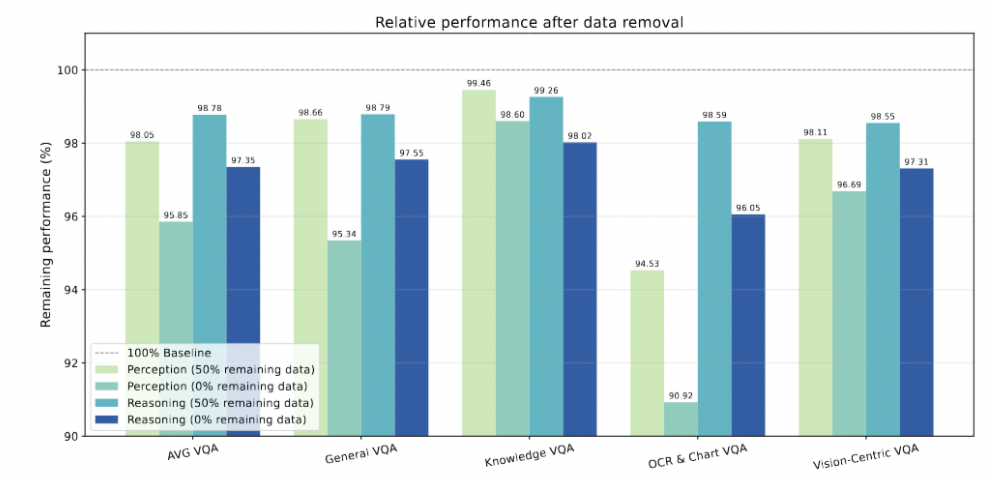
Pre-training Recipe: From Theory to Practice
The team designed an optimal mixed-data recipe:
- Rich reasoning content for cognitive sharpness
- Small but sufficient amount of visual world knowledge
Results:
- The 7B model using this recipe surpassed language-only optimized models in language tasks.
- Outperformed all competitors in visual benchmarks.
- Demonstrated that textual pre-training can intentionally inject visual priors.

---
Significance & Outlook
- Moves multimodal capability cultivation earlier in the pipeline
- Supports the Platonic Representation Hypothesis
- (Text and images are projections of the same underlying reality)
Future implication:
Model pre-training will evolve from single-modality focus to cross-modal planning — embedding visual seeds from day one.
---
For Creators & Researchers
AiToEarn官网 helps teams:
- Publish AI-generated content across Douyin, Bilibili, Instagram, YouTube
- Track analytics
- Connect to AI generation tools
- Access global model rankings (AI模型排名)
This streamlined workflow complements the research’s vision of integrated multimodal intelligence.
---
Would you like me to also create a diagram summarizing the Reasoning vs. Perception priors so the Markdown becomes visually more engaging? That could make the two-pillar concept instantly clear for readers.