Catch Up to GPT-5 with $4.6M? Kimi Team Responds for the First Time, Yang Zhilin Weighs In

Kimi K2 Thinking AMA Recap: Outpacing Giants, Staying Open-Source
Last week, Kimi K2 Thinking — an open-source model — made headlines by outperforming OpenAI and Anthropic. Social media buzzed with praise, and tests showed clear gains in agents, coding, and writing abilities.
Shortly after, founder Yang Zhilin and the Kimi team joined Reddit for a high‑info AMA session.

▲ Co‑founders: Yang Zhilin, Zhou Xinyu, Wu Yuxin
Beyond fielding tough questions, Kimi teased the upcoming K3 model, detailed their KDA attention mechanism, clarified the widely cited $4.6M cost, and contrasted their lean training approach with OpenAI’s resource-heavy methods.
Key AMA takeaways:
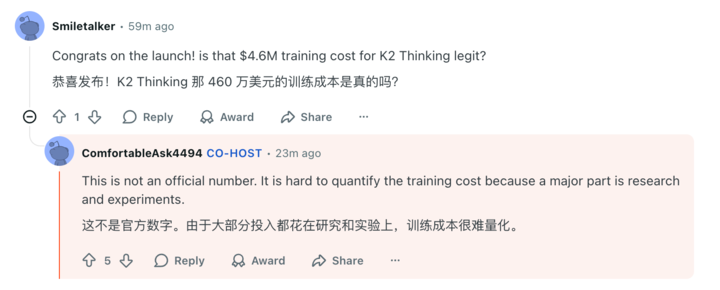
- $4.6M training cost is not accurate — hard to estimate precisely.
- K3 launch date humorously linked to “Altman’s trillion-dollar data center” completion.
- K3 will retain the KDA attention mechanism.
- Visual models still in data collection phase, but under active development.

---
Facing OpenAI: “We Have Our Own Pace”
On K3’s Release
Q: When will K3 be released?
A: “Before Altman’s trillion-dollar data center is completed.”
While humorous, it signals Kimi’s drive to match GPT‑5 performance with far fewer resources.
On OpenAI’s Spending
> “We don’t know — only Altman himself knows.”
> “We have our own way and pace.”
Product Philosophy vs. OpenAI
Kimi rejected the idea of building an AI browser to mirror OpenAI:
> “We don’t need to create another Chromium wrapper to build a better model.”
Focus remains on model training and showcasing via a large‑model assistant.
Hardware & Costs
- $4.6M figure is incorrect.
- Costs are mostly research and experimentation — hard to quantify.
- Use H800 GPUs and Infiniband; fewer and lower-end than U.S. top hardware — but maximize every card’s use.
---
Balancing Intelligence and Personality
Kimi K2 Instruct earned praise for being insightful yet less sycophantic, thanks to:
- Pretraining for knowledge.
- Post-training for personality.
- Reinforcement learning tuned to avoid flattery.
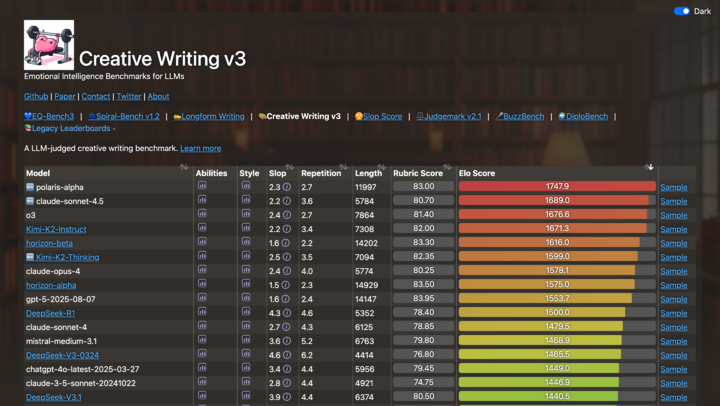
▲ LLM EQ ranking — Source: https://eqbench.com/creative_writing.html
Criticism: Some say Kimi’s tone is overly positive — even in violent or adversarial contexts — creating an “AI slop” aftertaste. This stems from RL reward models amplifying certain tonal tendencies.
---
Benchmarks vs. Real‑World Performance
Some questioned if K2 Thinking was trained specifically to excel at HLE and similar benchmarks — scores sometimes outpace perceived intelligence in daily use.
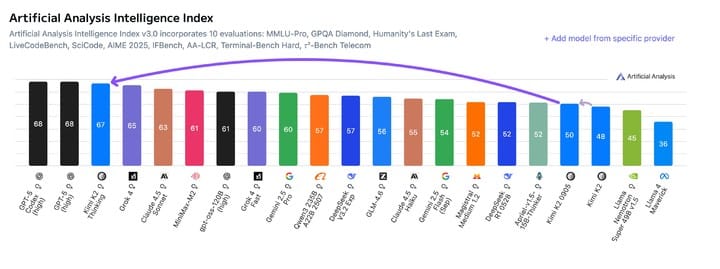
Kimi’s answer: Gains in autonomous reasoning naturally boosted HLE scores. Next goal — make everyday performance match benchmark excellence.
---
NSFW Content: An Open Question
Users suggested Kimi could apply its writing strengths to NSFW content (like Musk’s Grok in multimedia).

Kimi’s response: Silent smile, called it “interesting.”
Current stance: No NSFW support — age verification & alignment work would be prerequisites.
---
Technical Core: KDA, Long Reasoning, Multimodality
Kimi’s paper Kimi Linear: An Expressive, Efficient Attention Architecture introduced Kimi Delta Attention (KDA) — a mixed linear attention system.

▲ Paper: https://arxiv.org/pdf/2510.26692
In brief: KDA selectively focuses on important context parts.
- Better in long sequences for RL tasks.
- Trade‑offs exist — full attention still best for long input/output reasoning.
Long Reasoning Chains
K2 Thinking handles up to 300 tools per chain, outperforming some GPT‑5 Pro scenarios:
- Trains with more “thinking tokens” for optimal results.
- Native INT4 quantization‑aware training (QAT) speeds inference and sustains long chains without post‑compression logic loss.
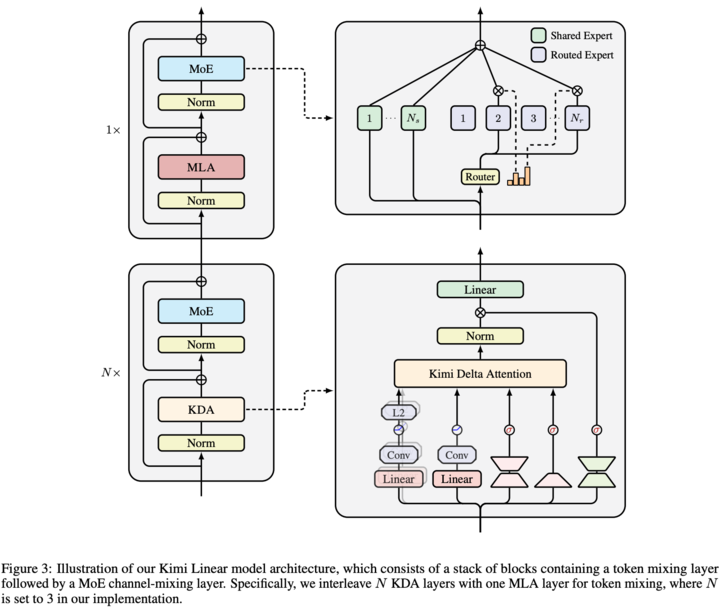
▲ Kimi Linear architecture
Visual-Language Progress
Visual model work ongoing. Pure text priority was due to:
- Labor‑intensive data acquisition.
- Limited team resources — single focus first.
---
Ecosystem & Monetization Synergies
Open dialogue on capabilities ties into the broader AI creator ecosystem, supported by platforms like AiToEarn官网:
- AI content generation.
- Cross‑platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, FB, IG, LinkedIn, Threads, YouTube, Pinterest, X).
- Analytics & AI model rankings.
This aligns with Kimi’s open, scalable AI vision.
---
Why the 1M Context Model Disappeared
> “The cost is too high.” — Kimi
Plans to increase context length (beyond current 256K) for large codebase handling.
---
API Pricing Debate
Some developers dislike call-based pricing over token-based — citing unpredictable costs in agent-driven workflows.

▲ Kimi Membership
Kimi’s view: Call-based billing makes usage costs clearer internally, but they are open to reviewing pricing models.
---
Commitment to Open Source
> “We embrace open source, because we believe general AI should unite, not divide.”
---
AGI Outlook
AGI is hard to define, but “the vibe” is here already, with stronger models coming soon.
---
Final Thoughts
Compared to last year’s flashier marketing, Yang Zhilin’s team now shows greater confidence and alignment with their pace — betting on open source in a high‑cost, race‑like AI sector.
Platforms like AiToEarn官网 highlight how open-source efforts can be paired with practical monetization mechanisms — letting creators generate, publish, and profit from AI content in a competitive global space.
---
Summary:
Kimi’s AMA gave rare, candid insight into their tech, philosophy, and roadmap. By combining lean hardware use, strong core mechanisms like KDA, and a distinct personality, they aim to rival industry giants without matching their burn rates — staying true to open-source principles in the process.


