Choreographers Out of Work! NUST + Tsinghua + Nanjing University Create: One Song Enables High-Quality Harmonious Group Dance

TCDiff++: Breaking Barriers in Multi-Person AI Dance Generation

---
Overview
Xin Zhiyuan Report
When the metaverse’s digital humans need advanced “group dance skills,” traditional music-driven generation technologies hit serious bottlenecks:
- Dancer collisions
- Stiff, unnatural movements
- Failures in long-sequence choreography
Researchers from NUST, Tsinghua University, and Nanjing University have jointly developed TCDiff++, an end-to-end model that achieves high-quality, long-duration, multi-dancer automatic choreography without collisions or foot sliding.
TCDiff++ supports cross-modal choreography — one click generates harmonious group dances, offering a complete AIGC workflow for virtual concerts, theatre, and metaverse events.
This is an upgrade from the AAAI 2025 open-source TCDiff model and has been accepted by IJCV 2025.
---
Challenges in AI Group Dance Generation
1. High Similarity in Motion Data
- In typical datasets, 80%+ of movements are nearly identical.
- Each dancer’s motion data: 100+ dimensions, but position data is only 3D.
- Result: AI confuses dancer identities → leads to collisions.
2. Foot Sliding Phenomenon
- AI struggles to synchronize upper-body motion and foot placement.
- Foot sliding breaks realism and immersion.
3. Long-Sequence Instability
- Short clips (few seconds) are easy.
- Long sequences (minutes): mutations, stutters, positional drift.
- Real-world performances last much longer — current models fail here.

---
From TCDiff to TCDiff++
In TCDiff (AAAI 2025), researchers introduced the trajectory-controllable concept:
- Two-stage framework: separate trajectory prediction from action generation.
- Worked for collision prevention, but caused rigid transitions and jitter in long sequences.
TCDiff++ solves these with a fully end-to-end architecture.
Core Components:
- Group Dance Decoder
- Generates collision-free coordinated movements from music.
- Footwork Adaptor
- Refines foot trajectories, eliminates sliding, ensures grounded footwork.

---
Links:
📄 Paper: arxiv.org/pdf/2506.18671
🌐 Project: da1yuqin.github.io/TCDiffpp.website
💻 Code: github.com/Da1yuqin/TCDiffpp
---
System Workflow
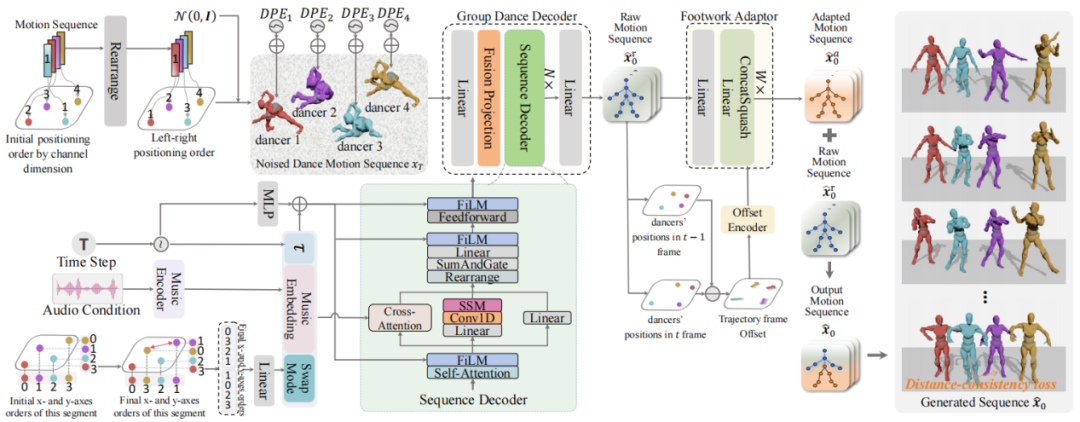
- Step 1: Group Dance Decoder → initial movements, no collisions.
- Step 2: Footwork Adaptor → optimizes feet, removes sliding.
- Step 3: Integration → stable, realistic dance sequences.
---
Key Innovations
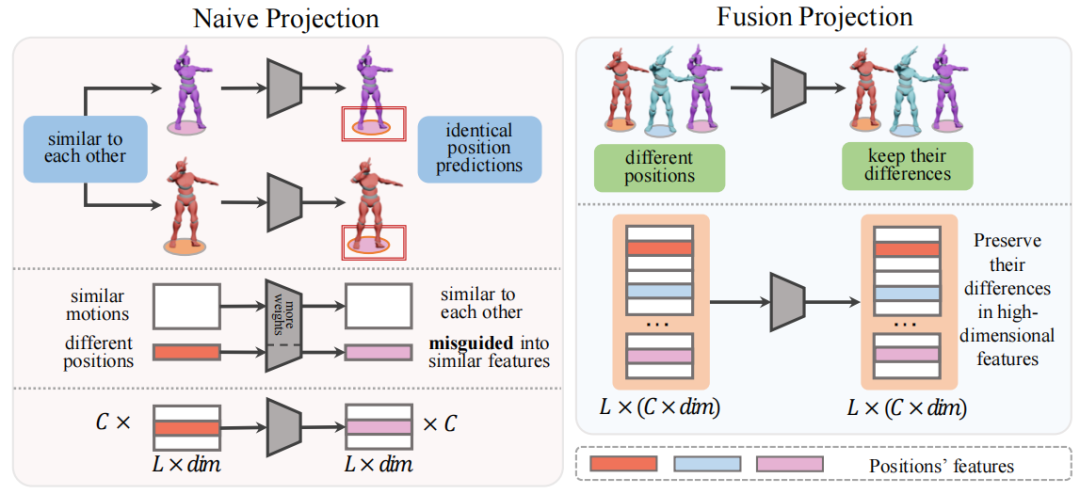
1. Collision Prevention

- Dance Positioning Embedding — encodes dancer positions (left/right) in formation.
- Fusion Projection Module — boosts feature dimensions, improves dancer distinction.
- Global Distance Constraint — maintains safe spacing between dancers.
---
2. Precise Footwork

- Swap Mode Conditioning — guides realistic foot movement from start.
- Footwork Adaptor — uses heel/toe contact & root bone velocity to refine steps.
---
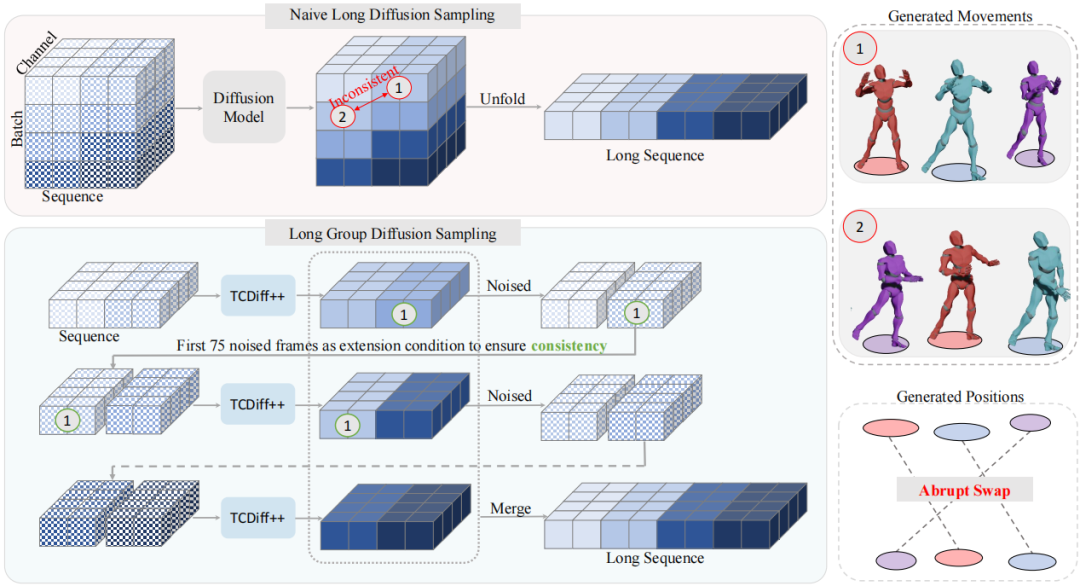
3. Long-Sequence Optimization

- Long Group Diffusion Sampling — segmented generation with half-segment overlap.
- Preserves positional continuity and motion smoothness.
---
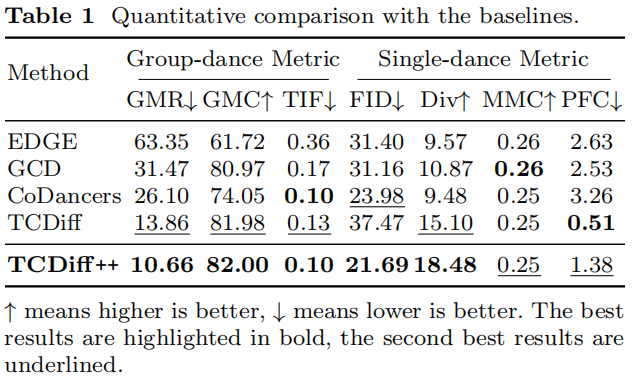
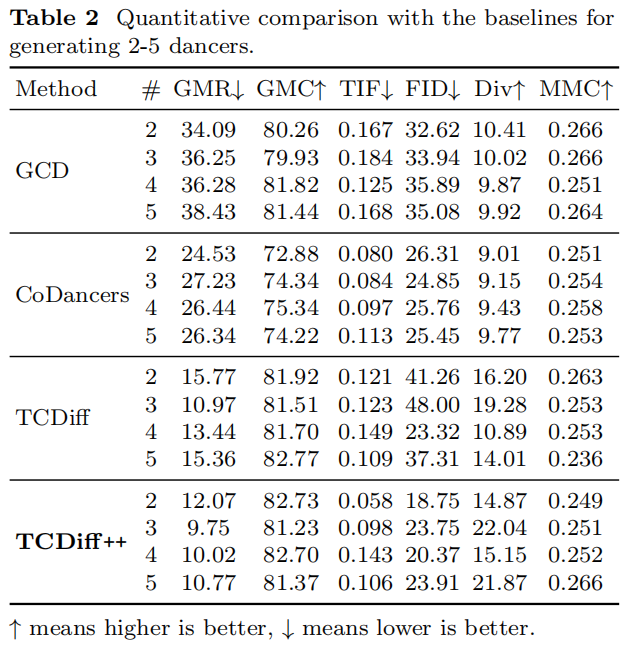
Performance Comparisons
Model Benchmarks

Why TCDiff++ Excels:
- Best multi-dancer coordination
- High solo realism & diversity
- Strong long-duration stability
---
Other Models’ Limitations:
- EDGE: Can’t distinguish dancers → sliding & collisions.
- GCD: Ignores coordinate modeling → severe sliding.
- CoDancers: Improves ID clarity but loses formation harmony.
- TCDiff: Better formation but mismatched actions & positions.
---
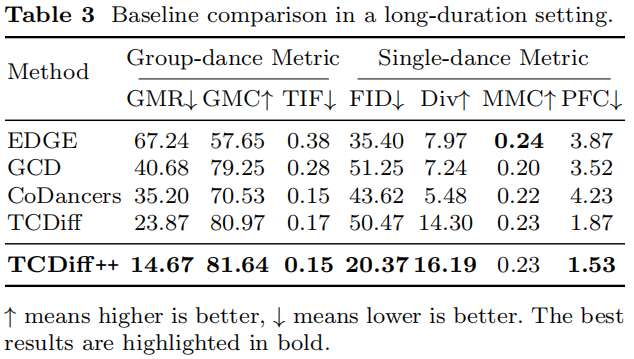
Long-Sequence Capability Test

- EDGE / GCD: Abrupt position swaps.
- CoDancers: Poor formations.
- TCDiff: Cumulative position–motion errors.
- TCDiff++: Maintains position–movement consistency for 720-frame sequences.
---
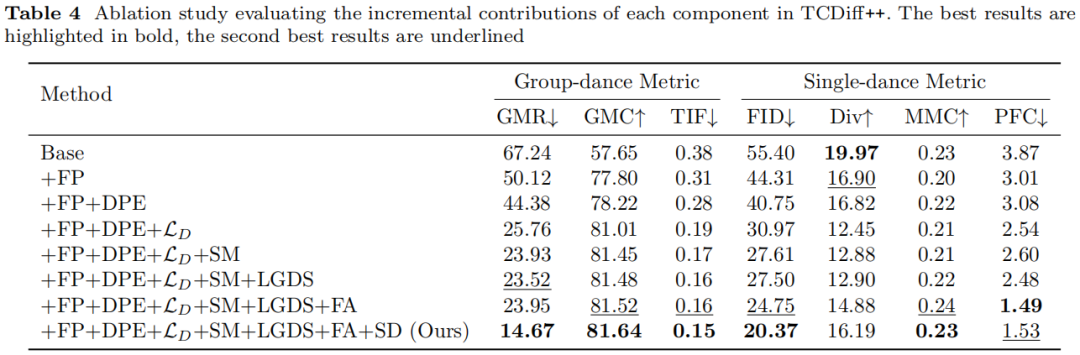
Ablation Study
- All modules reduce collisions & sliding.
- Maximum performance achieved when all modules combined.
---
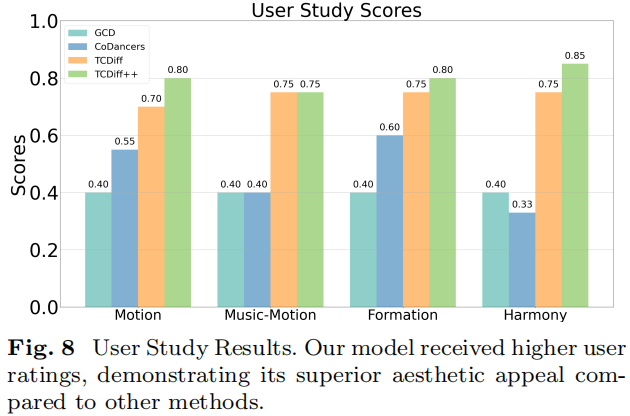
User Preference Survey

Criteria:
- Movement realism
- Music–movement correlation
- Formation aesthetics
- Dancer harmony
Result: TCDiff++ most visually preferred.

---
Limitations & Future Directions
- Currently music-only input
- No support for text input, keyframes, or style parameters.
- Future plans: rich multimodal controls for interactive use.
- Formation change learning (e.g., swaps)
- Dataset scarcity of swap motions & annotations.
- Need larger, richer datasets for dynamic formation choreography.
---
Integration with AI Content Ecosystems
TCDiff++ can be integrated with open-source platforms like AiToEarn, enabling:
- AI-generated choreography
- Cross-platform publishing (Douyin, Bilibili, YouTube, Instagram, etc.)
- Analytics & monetization
---
References:
📄 https://arxiv.org/pdf/2506.18671
---
If you want, I can also prepare a short, visually-optimized summary version of this TCDiff++ feature set for quick reading, which would be ideal for GitHub README or project landing pages. Would you like me to do that?


