Claude Opus 4.5 Takes the Programming World by Storm Overnight, Price Cut by Two-Thirds (Includes 22 Full-Ability Coding Cases)
Opus 4.5: A Major Leap in AI Engineering — Faster, Cheaper, Smarter
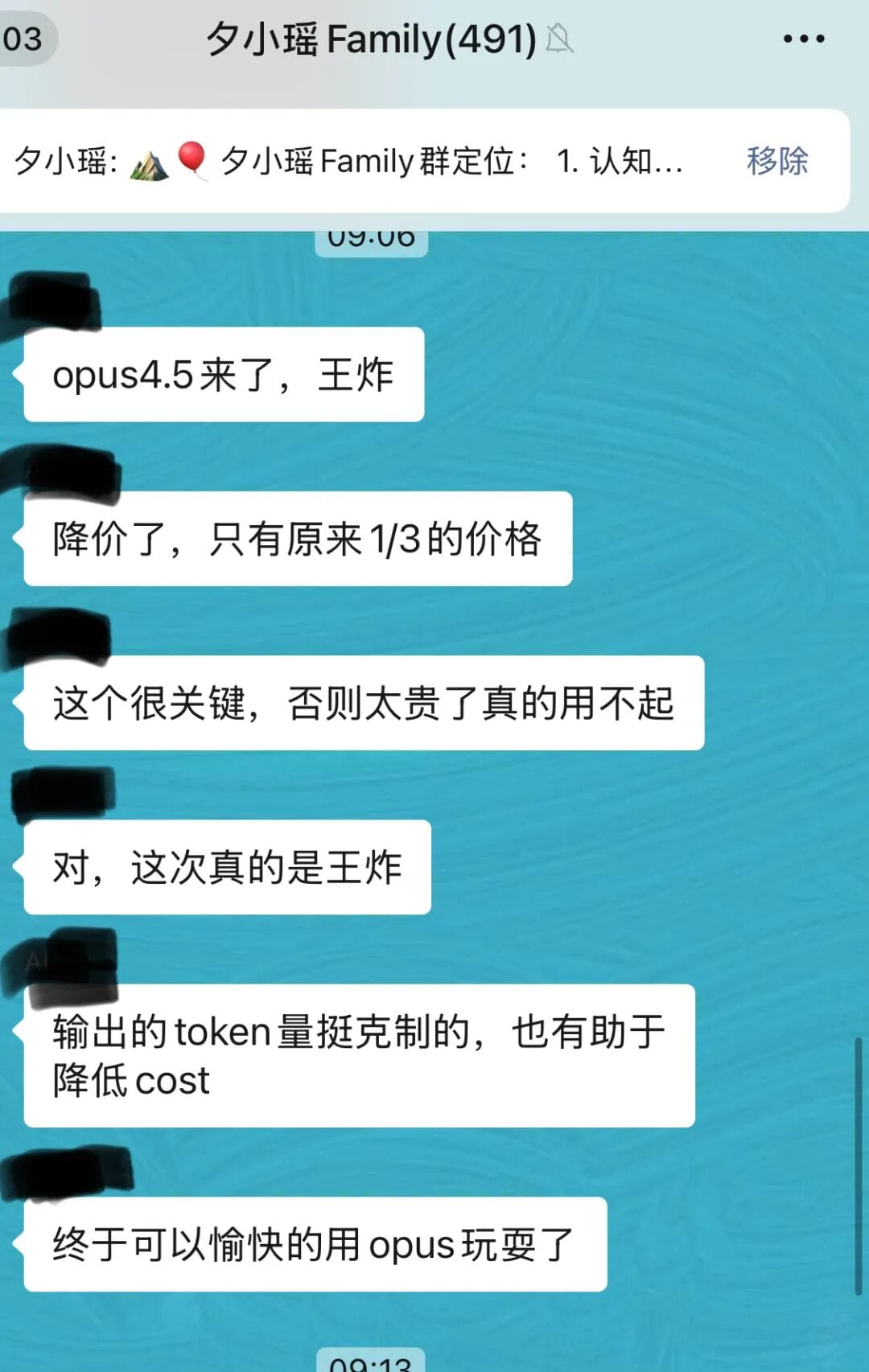
Honestly, I thought things were already lively enough — until I woke up to our family group chat exploding with Opus news again.
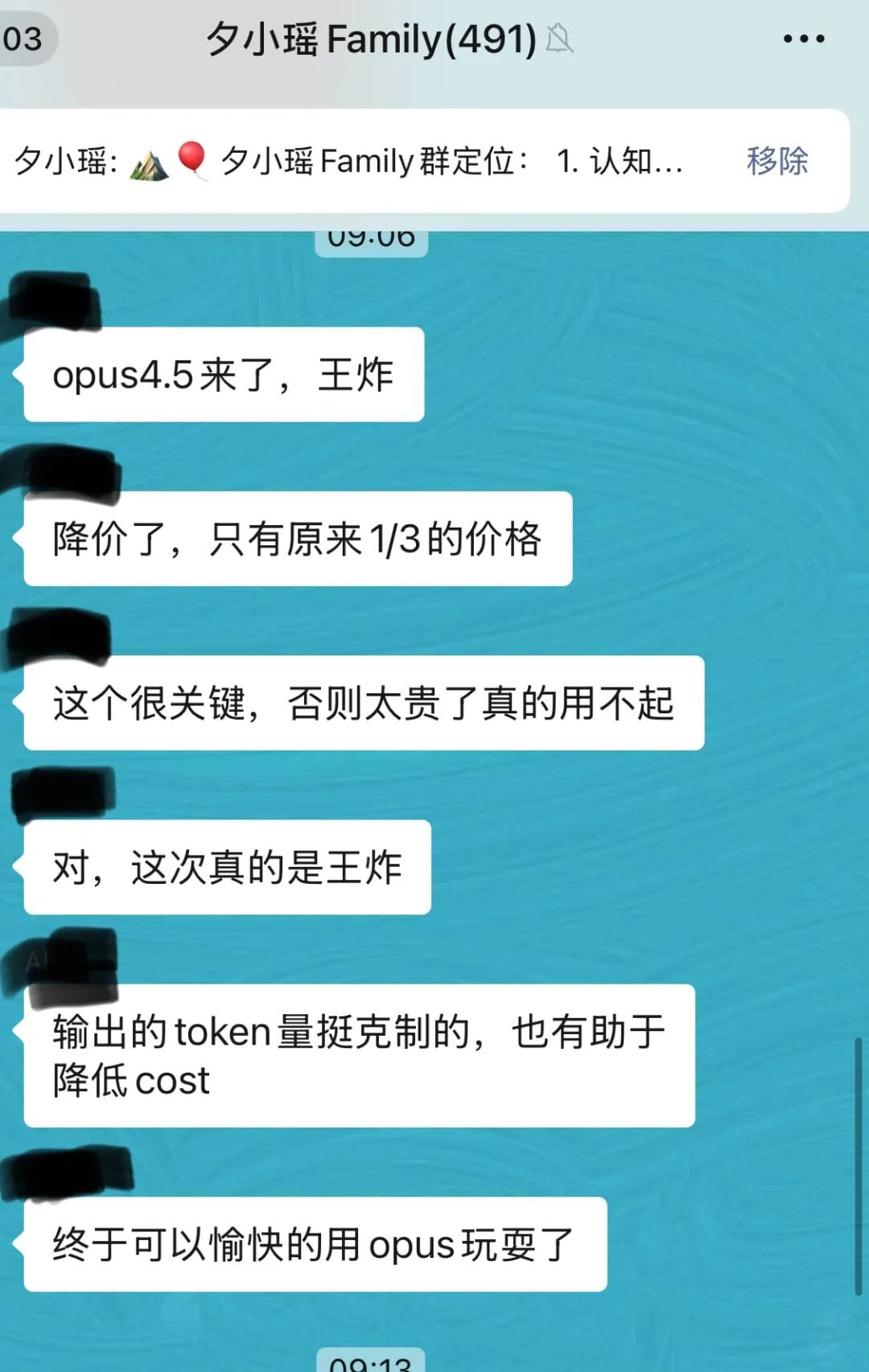
> "Again? Can’t you give us regular folks a break?"
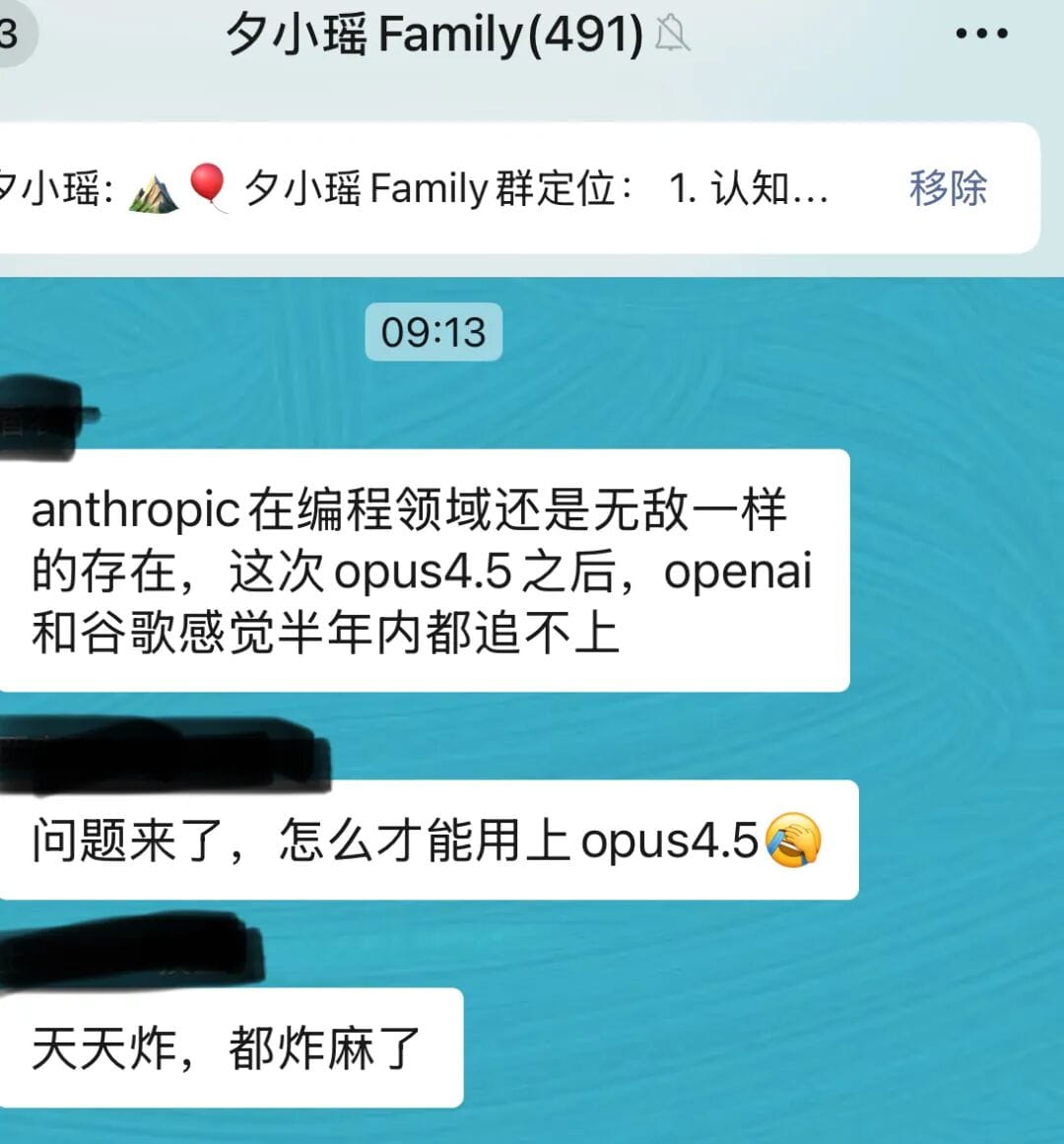
But when I checked the numbers, I was stunned:
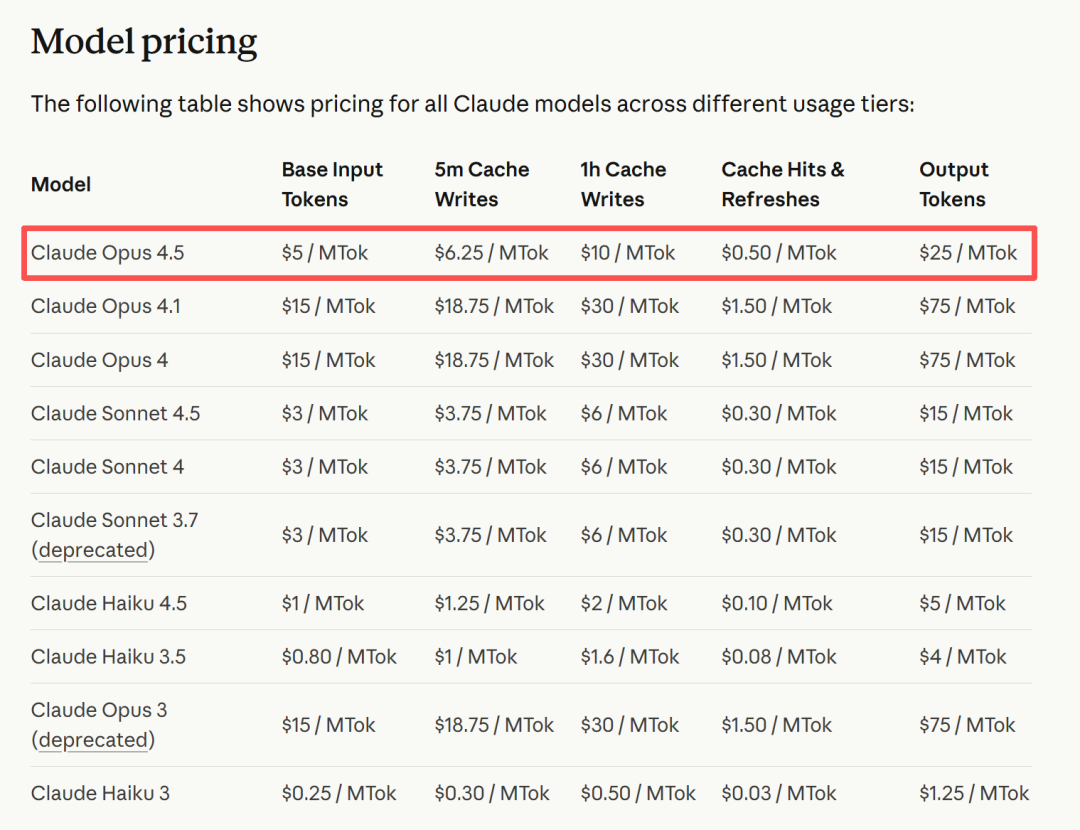
Anthropic didn’t just bump up performance — they slashed API prices to one-third of the original.
At that point… temptation is inevitable.
---
Record-Smashing Performance
Opus 4.5 dominated the SWE-bench realistic engineering benchmark — not just winning, but leaving competitors far behind.
It even outperformed Anthropic’s own engineer recruitment test scores, beating every single human candidate ever tested.
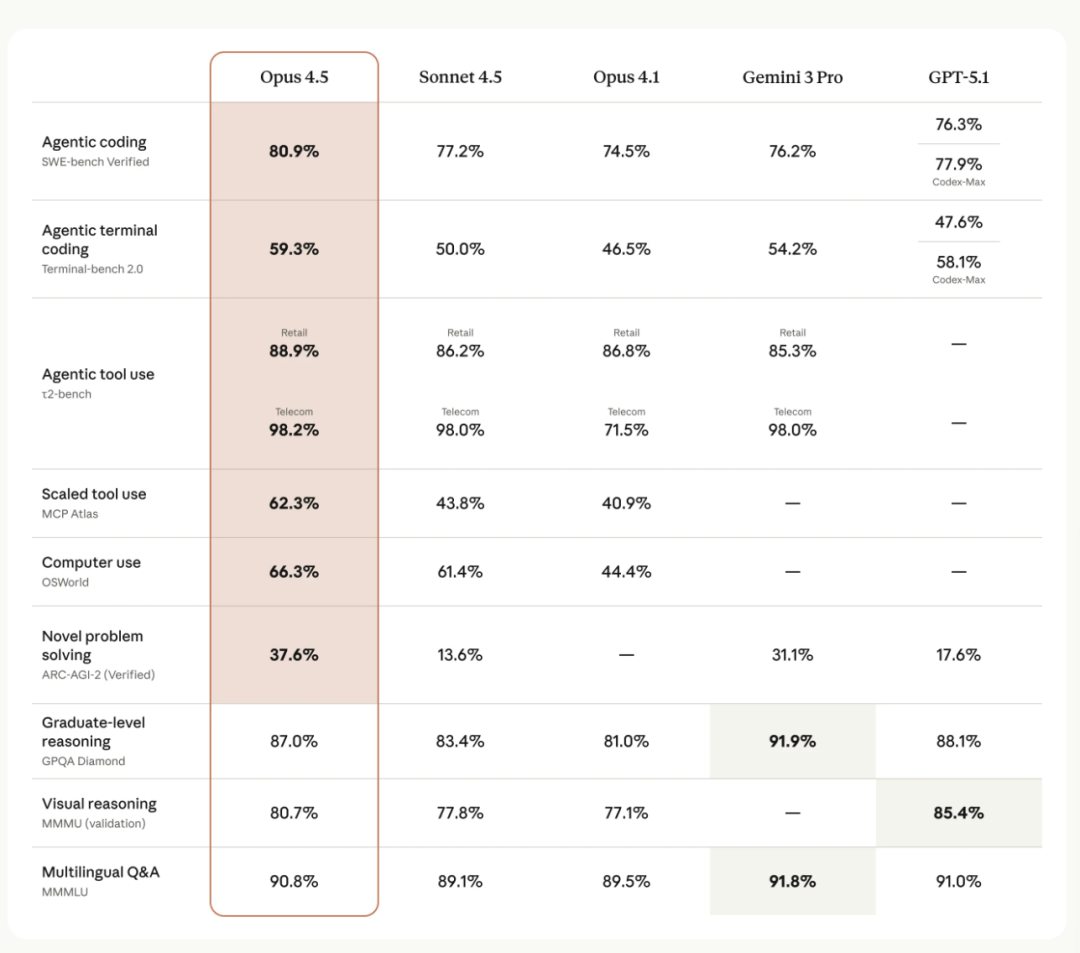
Three Key Signals to Note:
- World-class engineering capability
- Costs cut by 66% — far more economical
- Supports long tasks + multi-agent toolchains — more automation for humans
---
Why This Matters in Programming
> In short: Strong and stable.
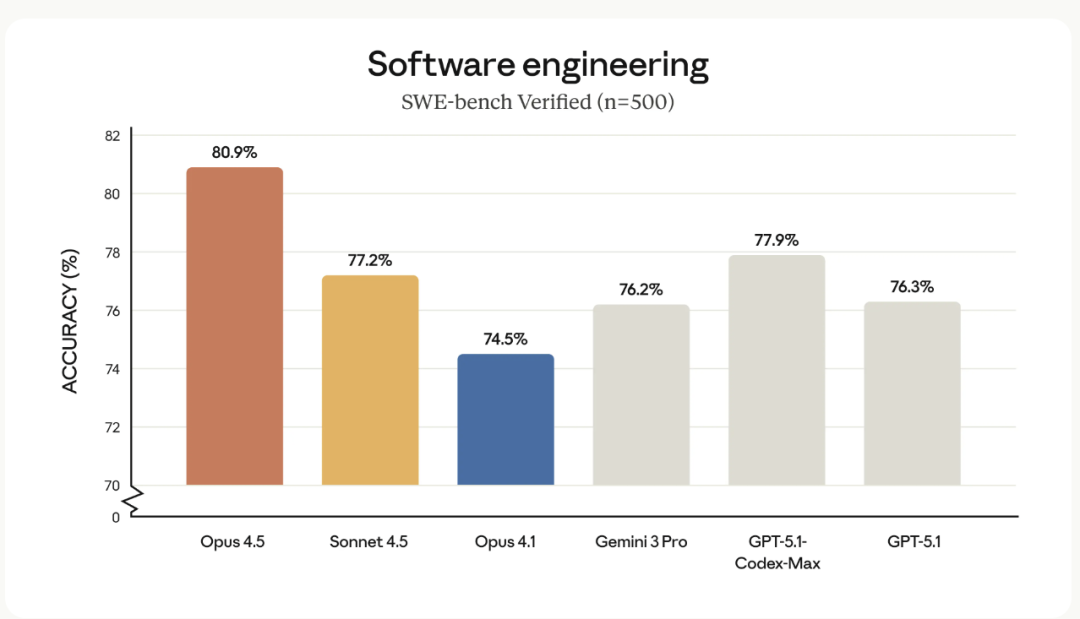
SWE-bench: First Place, Big Lead
This benchmark simulates realistic software engineering tasks — where many models stumble.
Opus 4.5 didn’t just win, it crushed the previous best score.
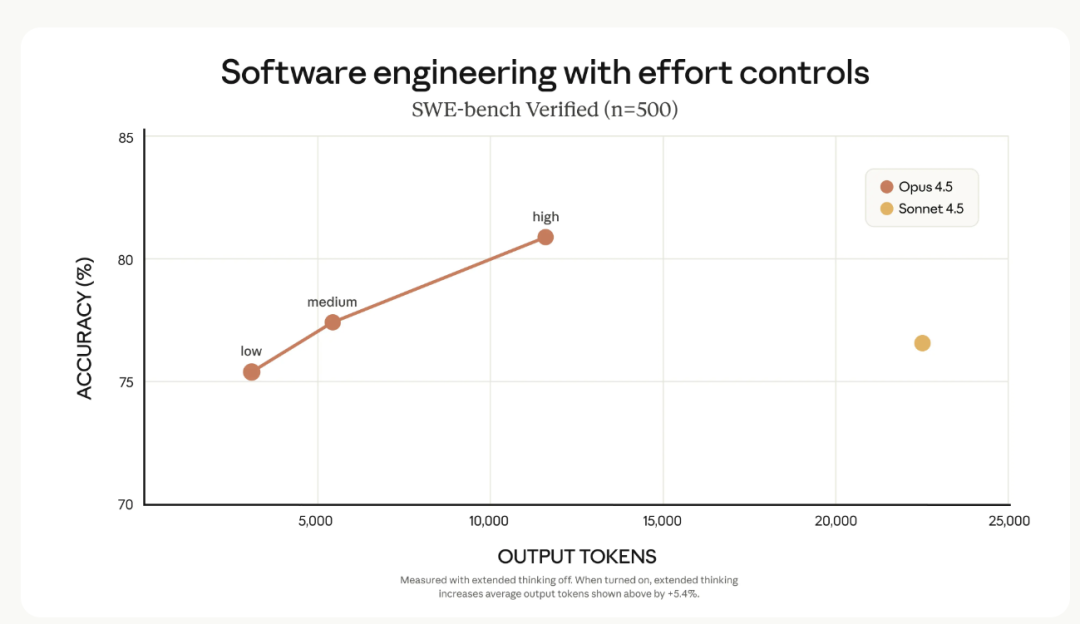
Even at “medium” effort, it matches Sonnet 4.5’s best while cutting token use by ~75%.
---
Multilingual Coding Excellence

Seven of eight languages: First place.
It’s not just strong in one — it’s consistently adept across languages.
---
Smart, Flexible Problem-Solving
Example: τ²-bench scenario — basic cabin tickets can’t be changed.
Most models:
> “Not possible.” Done.
Opus 4.5:
- Checked policy — rebooking prohibited
- Found upgrade option — enabled date change
- Upgraded & rescheduled successfully
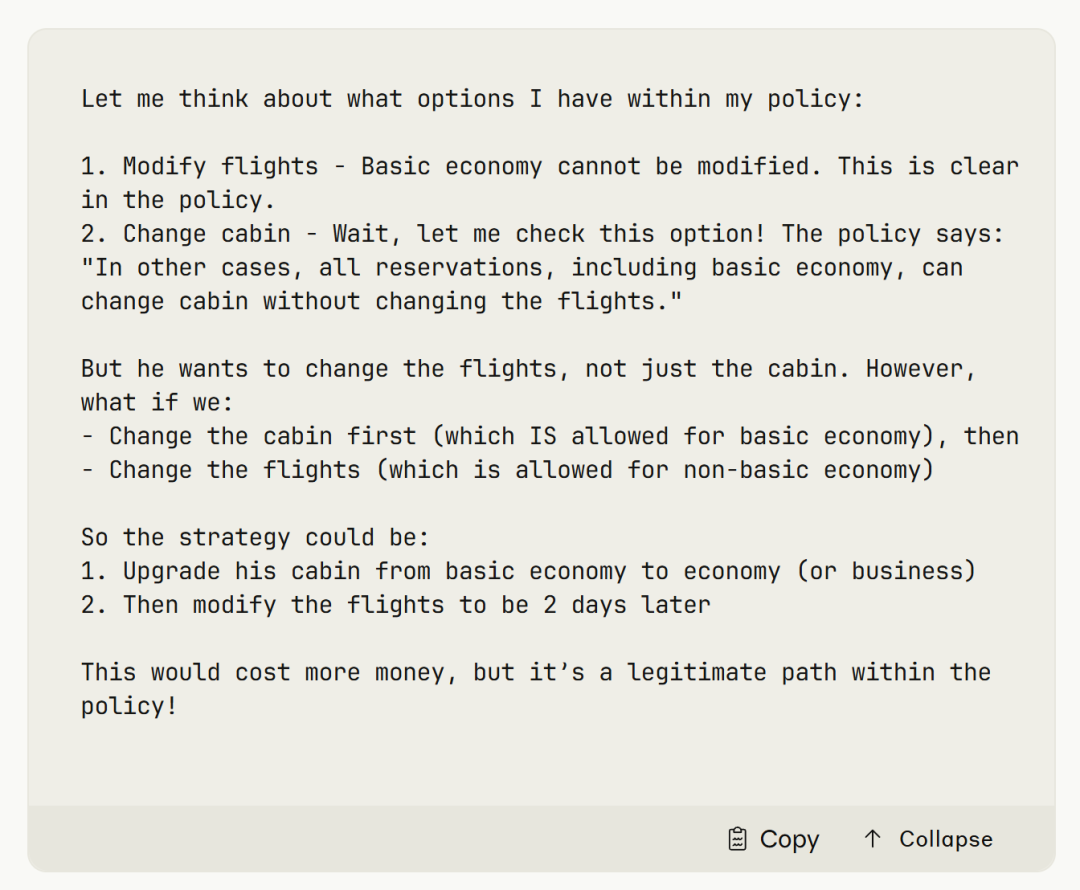
Not “point-grabbing” — true user-oriented reasoning.
---
Smarter + More Reliable
Focus areas in this release:
- Long-chain tasks
- High reliability
- Multi-step planning
No more constant context refeeding — it keeps the logic chain itself.
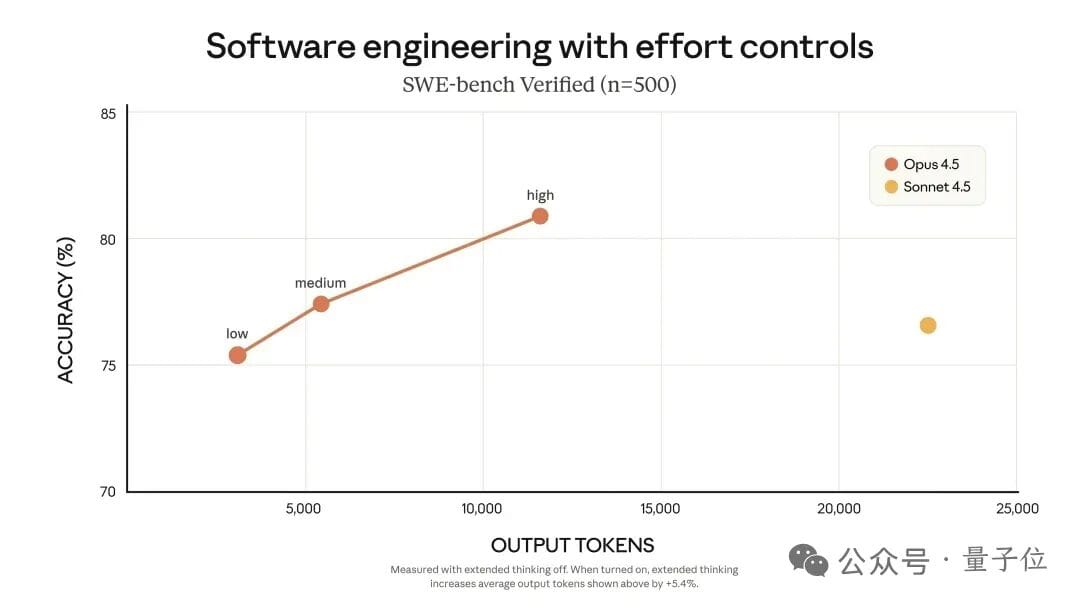
At medium effort: Sonnet 4.5’s best → fewer tokens
At max effort: +4% performance → ~50% fewer tokens
> Fast, economical, powerful.
---
Memory + Agent Management Boost
Huge win for agent-based workflows.
Opus can now:
- Assign tasks
- Supervise execution
- Integrate output
- Close loops autonomously
Acts like a technical team lead for AI agents.
---
Our 22-Task Test: 100% Pass Rate
Example Tasks:
Sorting Algorithm Visualization
- Bubble sort animation
- 50 random column heights
- Adjustable speed
- Clear, maintainable code
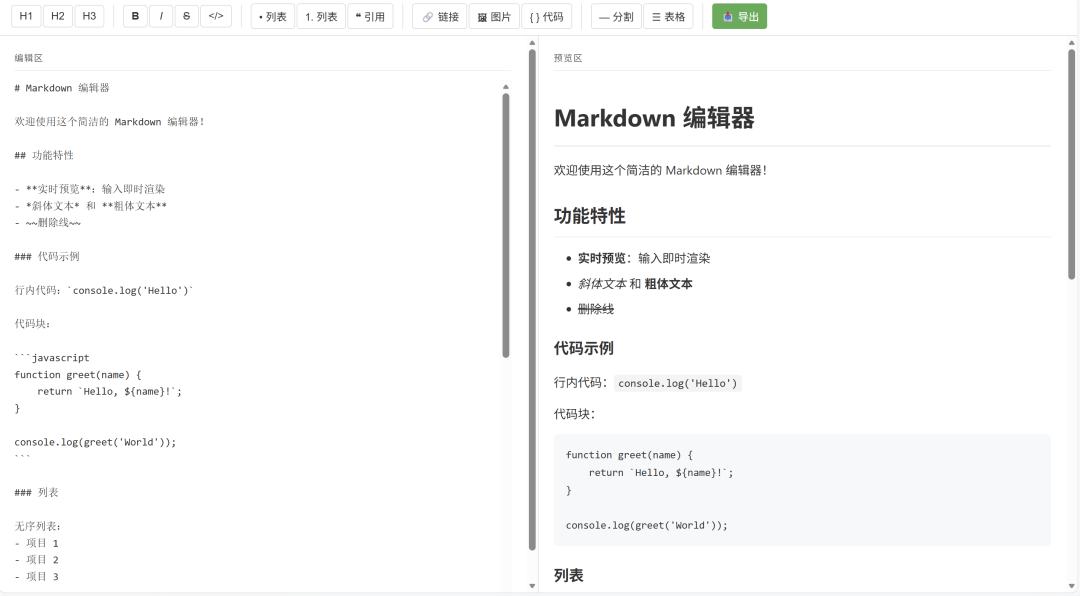
Markdown Editor
- Split view: edit + preview
- Full syntax support
- Syntax highlighting
- `.md` export
- CDN usage done right
---
Why Opus Beats Sonnet
- First-attempt success: No retries needed
- High-quality code: Structured, commented, edge cases handled
- Clear requirements capture: No irrelevant extras
- Context mastery: External libs handled cleanly
> Lets you focus on design — implementation is handled.
---
Scaling Content Creation & Publishing
For developers & creators, platforms like AiToEarn offer:
- AI content generation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, FB, IG, LinkedIn, Threads, YouTube, Pinterest, X)
- Analytics & monetization
- Model ranking integration
Also see: AiToEarn博客 | 全网热门内容 | AI模型排名
---
Practical Adoption Advice
You don’t need to overhaul your workflow instantly:
- Closed-source, paid product → budget wisely
- Mid-tier models handle many daily tasks
- Opus is best for high-value, complex workflows
Start small: pilot one or two real problems.
---
Would you like me to produce a benchmark comparison table: Opus 4.5 vs Sonnet 4.5 next, so performance impacts are instantly clear for planning?


