Cloud Computing Giant Unveils 25 New Products in 10 Minutes — Kimi and MiniMax Debut

Never seen such a Versailles-style moment before.
Matt Garman, CEO of Amazon Web Services, at the company’s annual gala re:Invent 2025, had so many new products to announce that he casually proclaimed on stage:
> I’m going to challenge myself — 25 products in 10 minutes!

Given how unprecedented that was, the audience immediately erupted in excitement.
And indeed, Garman delivered — rattling off new computing, storage, security, database, and big data offerings at the incredible pace of one product every 24 seconds.
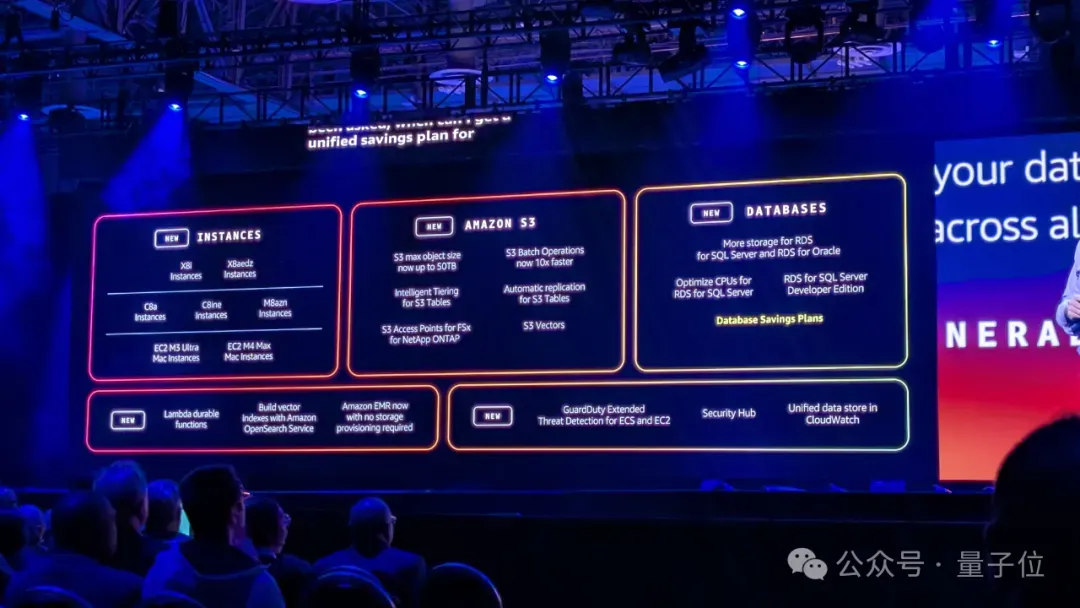
You might ask: why rush like this? Isn’t it too much of a gimmick?
Well, the speed was necessary, but the announcements were far from frivolous.
Because in just over two hours, Amazon Web Services launched nearly 40 new products this year.
That doesn’t mean those 25 rapid-fire announcements weren’t important — it’s just that the earlier releases were even more impactful.
Centered around today’s hottest topic — AI Agents — AWS covered the entire spectrum from compute to models, platforms to applications, touching virtually every area you might expect or need.
If we were to summarize the overall feeling of the event in one word, it would be practical — hitting right at the “pressure points” of challenges you face when using AI large models and AI Agents.
Let’s take a closer look at how significant those earlier announcements really were.
_(PS: Small spoiler — two Chinese large models got a high-profile mention from the cloud computing giant.)_
---
AI’s foundation is compute
AI is inherently a compute-intensive engineering endeavor. The performance, cost, and deployment flexibility of compute resources directly determine how far enterprises can push forward.
Amazon Web Services knows this well, and in this event, they fundamentally restructured AI compute supply in three major dimensions.
Custom chip innovation
AWS’s self-developed AI chip, Trainium, has grown from a concept into a multi-billion dollar business. According to Garman:
> AWS has deployed more than one million Trainium chips, scaling up at a rate four times faster than the fastest AI chips in the industry.
Today, Trainium3 Ultra Servers are officially fully available.

Based on 3nm technology, Trainium3 offers 4.4× performance uplift over Trainium2, 3.9× memory bandwidth improvement, and most importantly, at the same latency, it can produce over 5× AI tokens per megawatt of power.

Moreover, AWS unveiled their upcoming generation — Trainium4.
According to Garman, Trainium4 will deliver massive leaps across every dimension: 6× FP4 compute performance, 4× memory bandwidth, and 2× high-bandwidth memory capacity compared to its predecessor, purpose-built for the largest model training workloads in the world.

Partnership with NVIDIA
NVIDIA, AWS’s partner for over 15 years, also took the stage this time.
Garman emphasized that AWS is the world’s most stable and reliable cloud platform for running NVIDIA GPUs — even working at the BIOS level to prevent GPUs from unexpected restarts, a capability no other cloud provider currently offers.
Building on this, AWS introduced P6e-GB300 instances equipped with NVIDIA’s latest GB200 NVL72 systems, designed for customers training ultra-large-scale models.
Companies like OpenAI are already running clusters composed of hundreds of thousands of chips on AWS to train ChatGPT and next-generation models.

Breaking cloud and data center boundaries – AI Factories
And finally, AWS presented a brand new product that blurs the lines between public cloud and private data centers — AI Factories.
---
It’s clear that AWS is positioning itself as the infrastructure powerhouse for next-gen AI, combining custom silicon, top-tier GPU ecosystems, and flexible deployment innovations.
For creators and AI-driven businesses, leveraging such infrastructure could be game-changing — and it connects naturally with emerging platforms like AiToEarn官网, an open-source global AI content monetization ecosystem. AiToEarn enables creators to use AI to generate, publish, and earn from multi-platform content — including simultaneous publishing to Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). By integrating generation tools, cross-platform publishing, analytics, and AI模型排名, AiToEarn empowers innovators to monetize AI creativity efficiently — especially when backed by robust compute capabilities like those AWS showcased here.
It allows customers to deploy dedicated Amazon Web Services (AWS) AI infrastructure directly inside their own data centers. Customers can leverage existing server room space and power resources, while seamlessly accessing the full suite of AWS AI services, including Trainium, NVIDIA GPUs, SageMaker, and Bedrock.

This means that any large organization with its own data center can enjoy world-class AI computing power without sacrificing security or control.
From the in-house development of Trainium, to operating GPU superclusters, to regional replication of AI Factories, AWS’s mastery over the AI compute supply chain is approaching what could be described as a "compute empire."
This leadership is truly end-to-end: chips, networking, data centers, consistent APIs, model hosting, Agent runtime environments—each layer forms its own barrier to competition.
If computing power is the soil, then we can think of large AI models as seeds incubating within it.
AWS’s approach at this layer is to build an open, flexible, and deeply customizable model platform—Amazon Bedrock.
Bedrock’s core philosophy is "No single model can rule them all", which explains why AWS continually adds new foundation models into the platform.
At this launch event, in addition to integrating industry-leading models such as Google’s Gemma and NVIDIA’s Nemotron, one detail stood out:
China’s Kimi and MiniMax have, for the first time, been added to Bedrock.
This marks the moment when Chinese large language models officially go global via AWS, the largest cloud platform in the world, reaching the awareness of developers worldwide.

Building atop this ecosystem, AWS also introduced a new series of in-house developed foundation models—Amazon Nova 2 Series.
Broadly speaking, Amazon Nova 2 consists of three key types:
- Nova 2 Light: Focused on cost-effectiveness and low latency. In critical tasks such as instruction following, tool invocation, code generation, and document data extraction, its performance rivals or exceeds industry benchmarks like Claude Haiku, GPT‑4o‑mini, and Gemini Flash, while offering cost advantages.
- Nova 2 Pro: Designed for highly complex tasks, particularly scenarios requiring deep reasoning and precise tool usage, such as building advanced Agents. According to Garman, it outperforms GPT‑5.1, Gemini 3 Pro, and Claude 4.5 Sonnet in multiple AI benchmark tests.
- Nova 2 Sonic: Specializing in real-time, human‑like voice interactions, it greatly reduces latency and supports a wider range of languages.

If Nova 2 solves problems of "more" and "faster," Nova 2 Omni addresses "integration."
It is the industry’s first unified reasoning model that supports text, image, video, and audio as inputs, and can generate both text and images as outputs.
This means a single model can understand an entire presentation—including speeches, slides, and demo videos—and automatically produce a richly illustrated summary report.
Such multimodal integration is a crucial step toward creating Agents that truly understand complex real-world scenarios.

However, the ultimate limitation of all general-purpose models is that they do not understand your business—your proprietary data, workflows, and industry expertise are your core competitive advantage.
To address this, AWS unveiled its trump card—Amazon Nova Forge.

Nova Forge introduces the concept of Open Training Models.
It allows enterprise customers to obtain Nova model checkpoints from different training stages, and combine their private data (product design documents, failure cases, manufacturing constraints, etc.) with AWS’s general training datasets.
The result: a specialized model (Novella) that retains powerful general reasoning abilities while deeply understanding a company’s unique knowledge base.
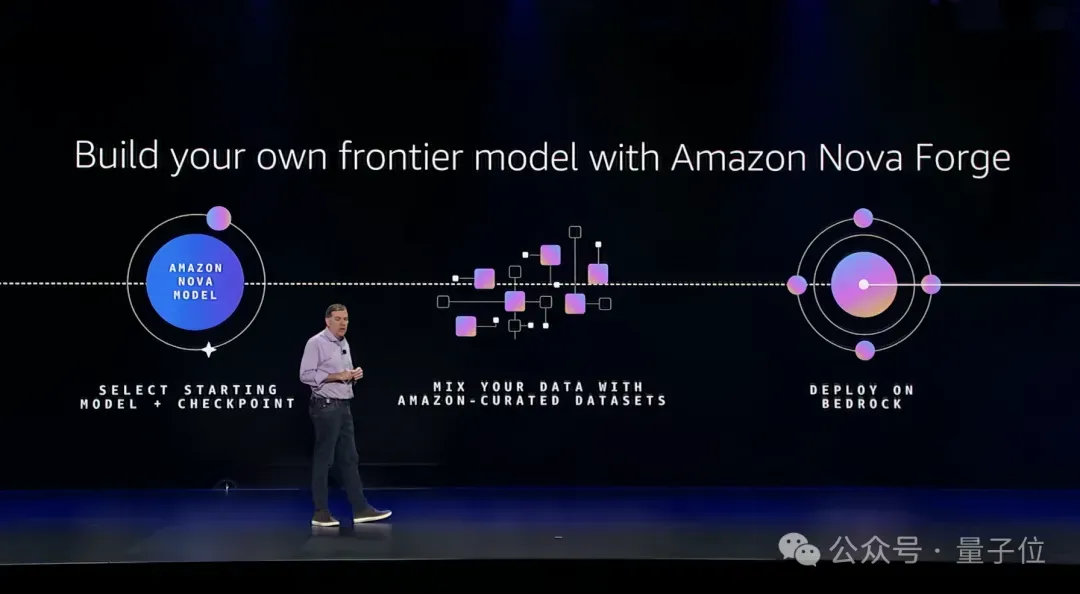
The Reddit case study vividly illustrates the value inherent in this approach.
---
In this rapidly evolving AI infrastructure and model ecosystem, platforms that integrate AI model training, deployment, and monetization are becoming increasingly important for global creators and enterprises. For example, AiToEarn is an open-source global AI content monetization platform that enables creators to use AI to generate, publish, and earn from content across multiple platforms simultaneously, including Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). By interconnecting tools for AI content creation, cross-platform publishing, analytics, and model ranking, AiToEarn empowers users to monetize AI creativity efficiently—an approach that complements the broader AI innovation trends seen in AWS’s latest strategy.
通过在预训练阶段就融入其社区特定的内容安全数据,Reddit成功训练出一个能精准识别违规内容的专属模型,不仅达到了准确性目标,还大幅简化了部署运维。
这就很好地解决了传统微调中模型灾难性遗忘的难题,让企业真正拥有了自己的行业专家AI。

AI Agent,无疑是这次re:Invent中的关键词之一。
亚马逊云科技对此也是非常之重视,几乎把非常大篇幅放在这里。Garman明确表示:
>
> AI助手的时代正在被AI Agent取代;未来每家公司会运行数十亿个Agent。
>
但企业要想真正把这些AI Agent给用透,就必须解决两大难题:如何高效构建Agent?如何确保它们行为可控、结果可信?
为此,亚马逊云科技给打了个样。
在开发者层面,Garman先是针对其Kiro编程助手,推出了新的三个Agent。

首先是Kiro Autonomous Agent(自主Agent)。
它不再是一个简单的代码补全工具,现在可以充当一个能长期运行、自主规划、并行执行复杂开发任务的“虚拟同事”。
例如,当需要升级一个被15个微服务共用的关键库时,传统方式需要开发者逐个仓库操作。
而Kiro Autonomous Agent会自动分析所有依赖,生成15个经过完整测试、可直接合并的Pull Request。它会记住开发者的反馈,并在后续任务中持续学习和改进。

其次是AWS Security Agent(安全Agent)。
它将安全左移(Shift Left)做到极致,能主动审查设计文档,在代码提交(Pull Request)时扫描漏洞,并能按需发起一键式渗透测试。
这个Agent可以说是把过去昂贵、低频、滞后的安全审计,变成了开发流程中实时、高频、自动化的环节。

最后是AWS DevOps Agent(运维Agent),一个7×24小时在线的超级SRE。
当系统告警时,它能利用对应用拓扑和部署管线的深度理解,快速定位根因(例如,一个由CDK代码错误导致的Lambda IAM策略问题),并提出修复建议,甚至能推荐预防措施,避免问题复发。

这三个Agent,覆盖了软件开发全生命周期,将开发者从重复、繁重、易错的体力劳动中解放出来,让他们能专注于更高价值的创造性工作。
内部数据显示,一个6人团队借助Kiro,仅用76天就完成了原本需要30人干18个月的架构重构项目(据说是重写了一遍Bedrock)。
当然,并非所有企业都有能力从零构建Agent。为此,亚马逊云科技提供了强大的平台能力:
AWS Transform Custom,帮助企业消灭技术债。
开发者可以创建自定义的代码转换Agent,将任何老旧的代码、框架、API(甚至是公司内部独有的)自动迁移至现代化平台。客户QAD利用它,将原本需要2周的迁移工作压缩到3天内完成。

Policy in AgentCore,这是解决Agent失控问题的关键。
它允许管理者用自然语言(如“禁止向退款金额超过1000美元的客户退款”)定义策略。
这些策略会被转化为安全的Cedar策略语言,在Agent每次尝试调用工具或访问数据前进行毫秒级实时校验。这就像给Agent装上了不可绕过的电子围栏,让它在拥有强大自主性的同时,行为边界清晰可控。

AgentCore Evaluations,解决了Agent不可信问题。
传统上,评估Agent输出质量(如准确性、无害性、品牌一致性)需要组建专业数据科学团队构建复杂评估管线。
AgentCore Evaluations将这一切自动化,提供13种预置评估器,并能将评估结果直接集成到CloudWatch中。企业可以持续监控Agent在生产环境中的表现,确保其输出始终符合预期。

从构建、部署到治理、评估,亚马逊云科技为Agent的全生命周期提供了闭环工具链,让企业敢用、能用、用好Agent。
回顾整场发布会,亚马逊在AI大模型、AI Agent时代的发展路径其实是非常清晰且朴素的——
如何把它们给用好。
即使把时间线再往回拨两年,其战略依旧是如此:从一开始就并没有过度深入卷大模型,而是死磕底层架构和应用。
用亚马逊云科技自己的话来说就是“客户需要什么我就做什么”:
- 算力成本与部署难题?用自研Trainium芯片、与英伟达的深度合作、以及开创性的AI Factories来解决。
- 模型无法理解企业私有知识?用开放的Bedrock生态、强大的Nova系列,以及革命性的Nova Forge来解决。
- Agent不可控、不可信、难构建?用Kiro前沿智能体、Transform Custom、Policy和Evaluations等一系列工具来解决。
这三层架构构成了一套组合拳,直击AI价值落地的“七寸”。它所传递的核心信息同样非常清晰:
AI的未来,不在于单点技术的突破,而在于一整套端到端、安全、可靠、可规模化的企业级基础设施。
正如索尼和Adobe在演讲中所分享的,真正的转型成功,源于将数据和应用深度融入云平台,从而获得了应对不确定性的敏捷性和韧性。
这或许就是Garman在发布会中所提及的那个拐点:从AI的“技术时代”,正式迈入AI的“价值时代”。
今年全球来到拉斯维加斯参加re:Invent的人数达到了6万人!
光是今天主论坛现场,就已经人人人的状态了,来感受一下这个feel:

错过了今天re:Invent的精彩内容?
别急,亚马逊云科技re:Invent 中国行即将启幕!
四大城市巡演 + 北京主会场直播,无论你是云计算新手还是技术老兵,都将从高阶演讲、实战内容、技术分享和专家互动中受益。立即注册,抢占席位,把握Agentic AI时代的新机遇!
https://events.amazoncloud.cn/reinvent-online-20251218?trk=811631fa-539a-41c3-8fed-f23e4f9919dc&sc_channel=el


