# Galaxy Data Development & Management Platform — Technical Overview
## Table of Contents
---
**I. Background Introduction**
**II. Product Functional Architecture**
**III. The "Cockpit" of Data Development — Data R&D Suite**
1. System Architecture Analysis
2. Data Synchronization Technology Analysis
3. Task Migration Solutions
4. Functional Development & Migration Progress
**IV. The "Chassis" of Company Data Assets — Data Architecture Technology**
1. Onedata Data Architecture Methodology & Tool System
2. Unified ODS Data Ingestion Solution
3. Standardized Data Modeling & Automated Metrics Development
4. Implementation Progress & Outcomes
**V. The "Brake Pads" of Data Production — Data Quality Technology**
1. Galaxy Data Quality Tool System
2. Implementation Progress & Outcomes
**VI. The "Assisted Driving" in Data Development — Intelligent Data R&D**
1. Galaxy Intelligent Evolution Roadmap
2. Intelligent SQL Code Completion Solution
3. Implementation Progress & Outcomes
**VII. Future Plans**
1. Long-Term Plan 1: Intelligent ETL Agent
2. Long-Term Plan 2: Data Fabric
3. Long-Term Plan 3: Data Logicalization
---
## **I. Background Introduction**
### **Why Build Dewu’s Own Big Data Platform?**
As a data-driven internet enterprise, **efficiency, quality, and cost of data usage** directly impact Dewu’s competitiveness.
- **Compute-Storage Engine** → Determines data usage cost.
- **Data Development Platform** → Controls data delivery speed, quality, and architecture.
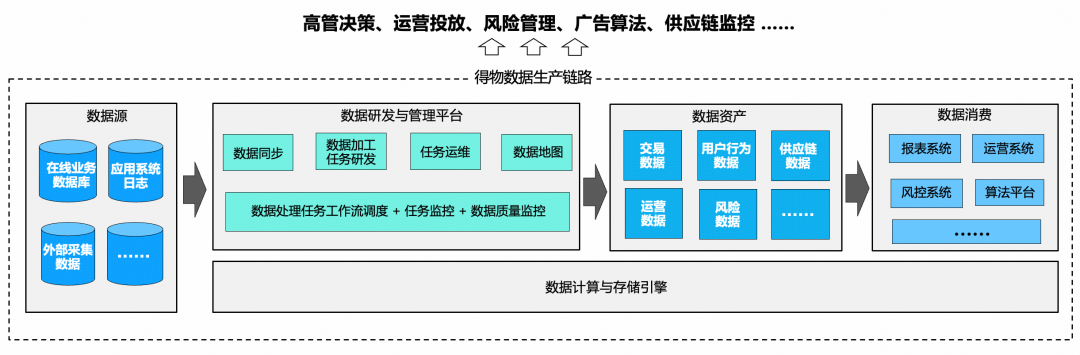
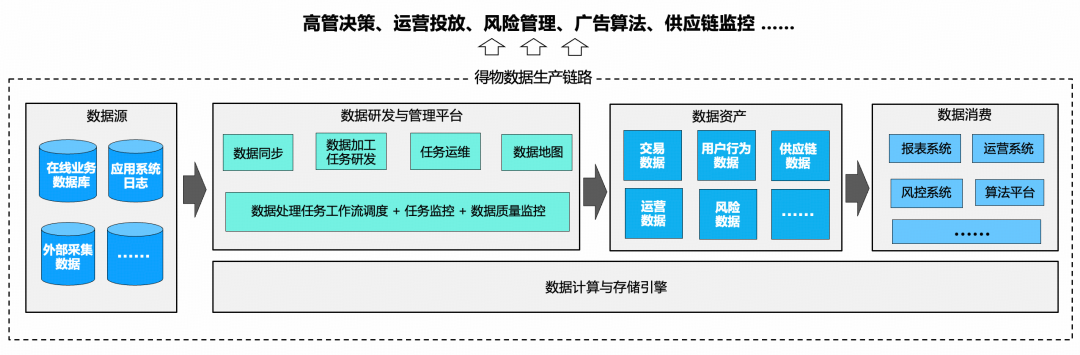
*Dewu Data Production Pipeline*
Historically, Dewu relied on **cloud-based commercial products** (“cloud platform”) which proved insufficient for long-term business needs.
In **2024**, Dewu initiated the self-build of its big data system.
The **Galaxy** platform is central to this — serving data producers in:
- Offline & real-time collection/synchronization
- Development & operations
- Processing & production
- Data asset management
- Security & compliance
Goals: Improve **architecture quality**, **data quality**, and **delivery speed**.
---
## **II. Product Functional Architecture**
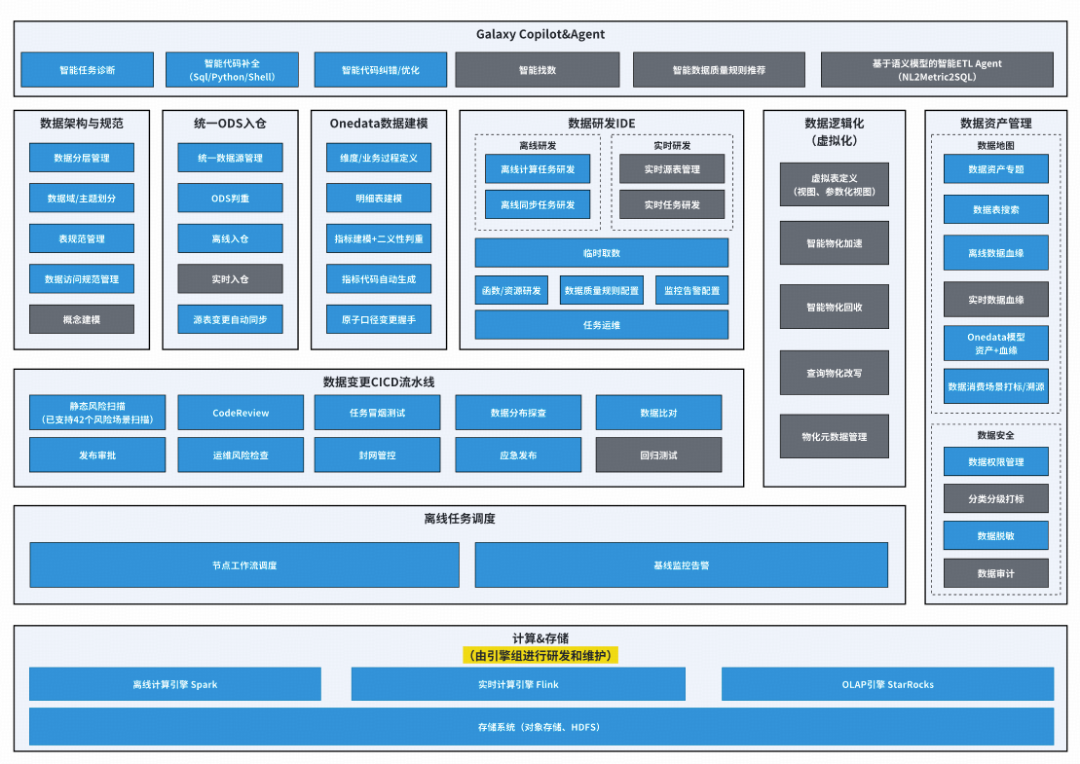
The diagram below shows implemented (**blue**) vs. planned (**grey**) features.
> **Note:** AI-driven workflows like [AiToEarn官网](https://aitoearn.ai/) demonstrate how integrated tooling boosts efficiency—by enabling AI content creation, multi-platform publishing, analytics, and monetization.
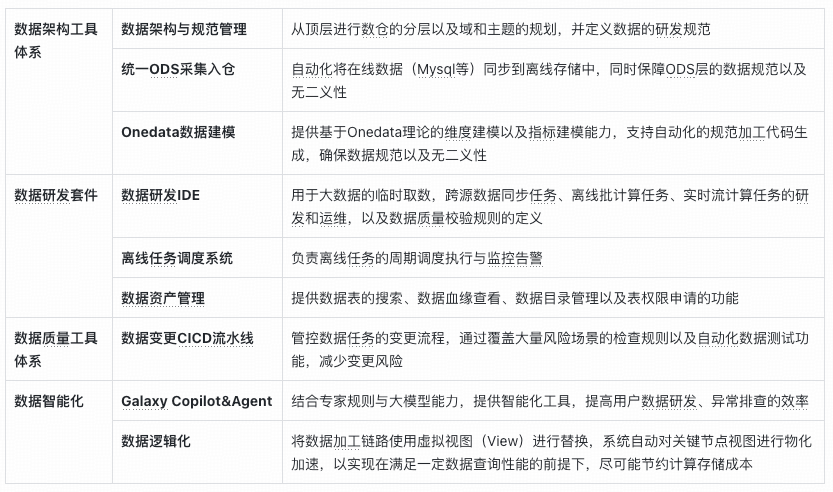
Galaxy focuses on **four core areas**:
1. **Data Development Suite** (Cockpit)
2. **Data Architecture Technology** (Chassis)
3. **Data Quality Technology** (Brake Pads)
4. **Intelligent Data Development** (Assisted Driving)
---
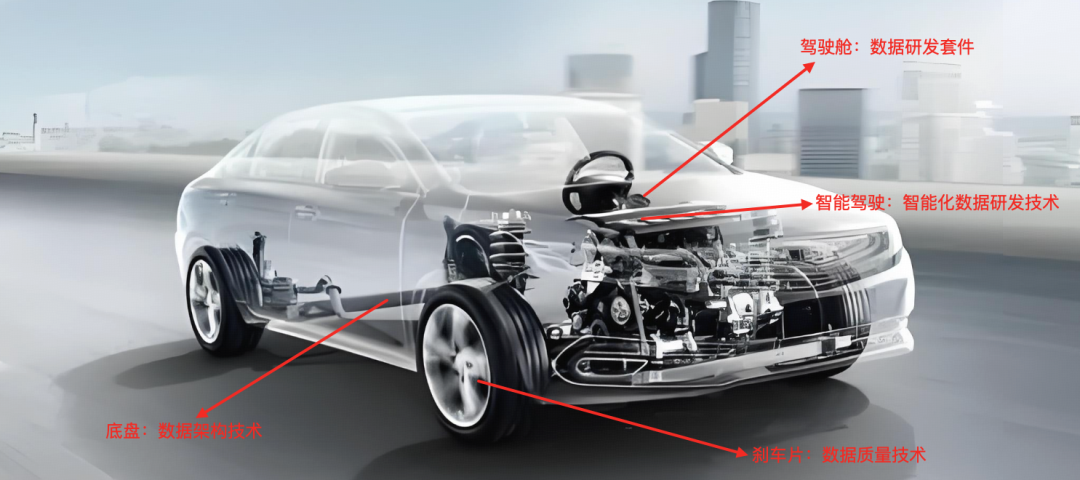
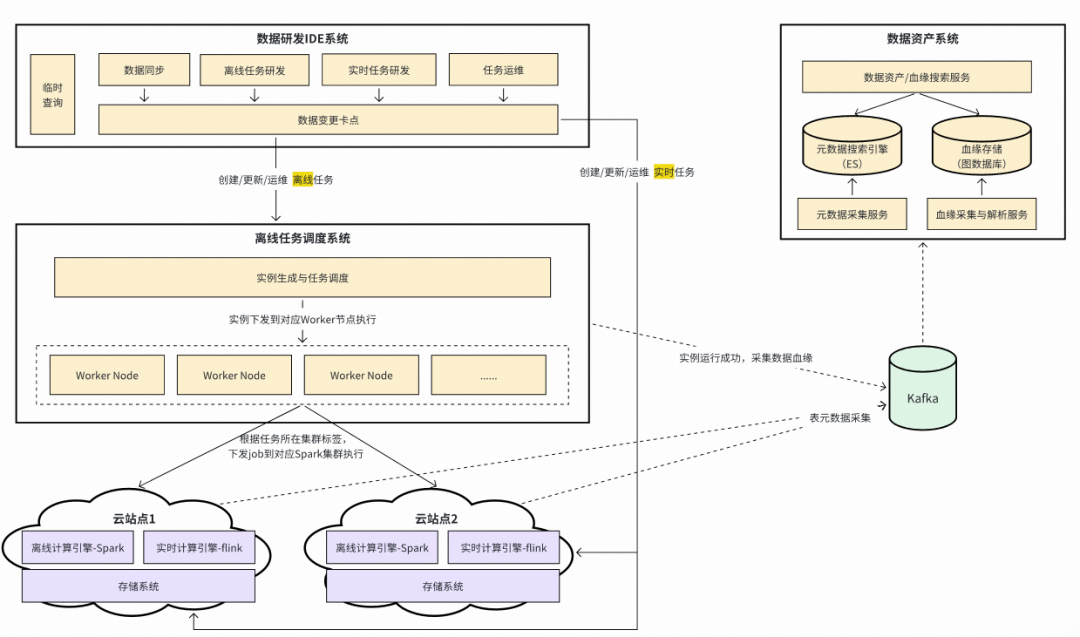
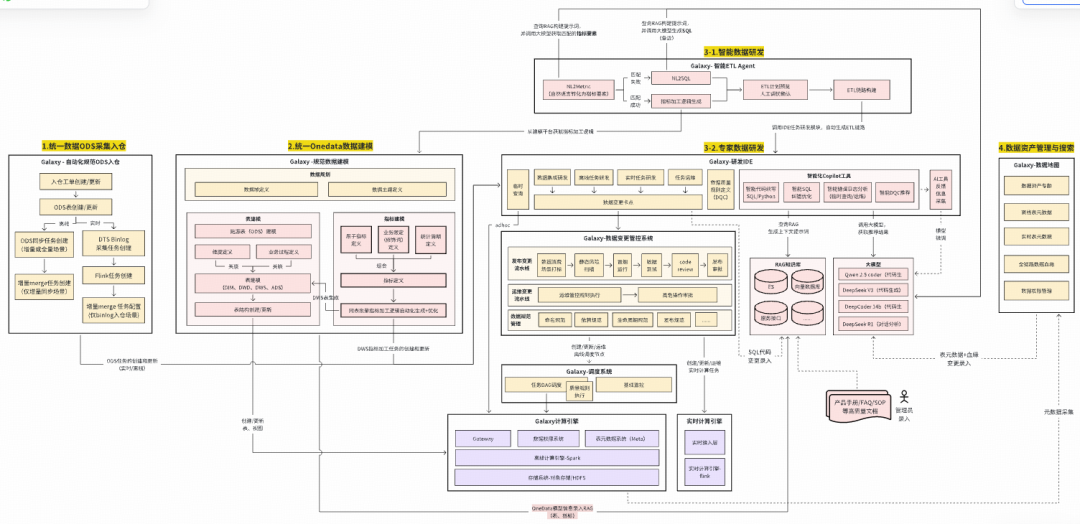
## **III. The “Cockpit” — Data Development Suite**
### **1. System Architecture**
Core components:
- **Data Development IDE**
- **Data Asset System**
- **Offline Task Scheduling System**
Purpose: Provide engineers control over data pipelines.
---
### **2. Data Synchronization**
#### Offline Synchronization:
- **Batch full/incremental** loads.
- Supported sources:
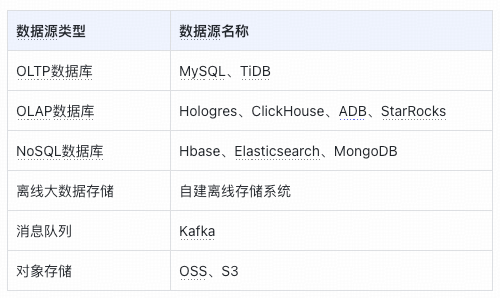
- Core tech: Spark JAR.
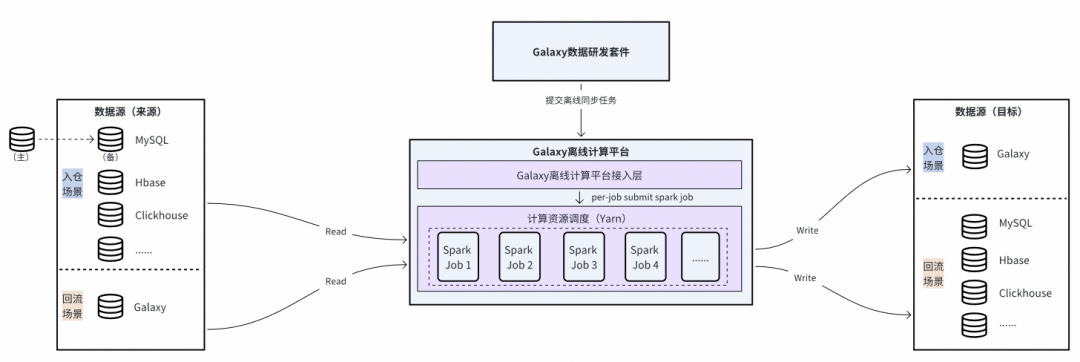
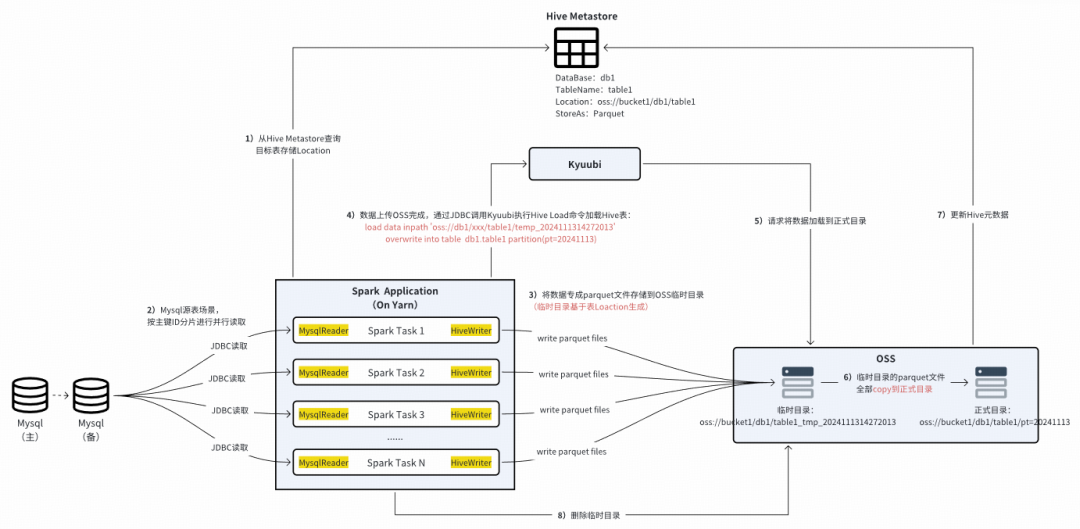
#### Real-Time Synchronization:
- Avoid DB load, long sync times, bandwidth bottlenecks.
- Supplement latency-sensitive cases.
**Option 1: Binlog-based ingestion**
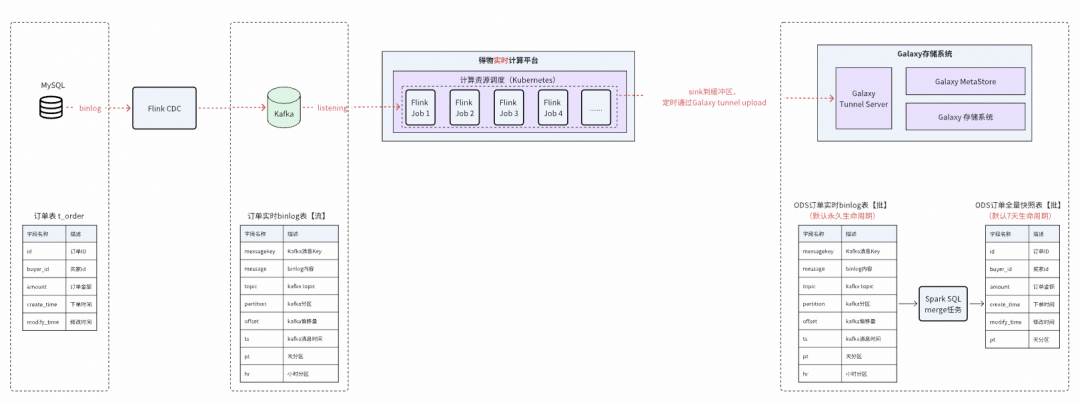
**Option 2: Real-time mirror sync via Flink CDC**

---
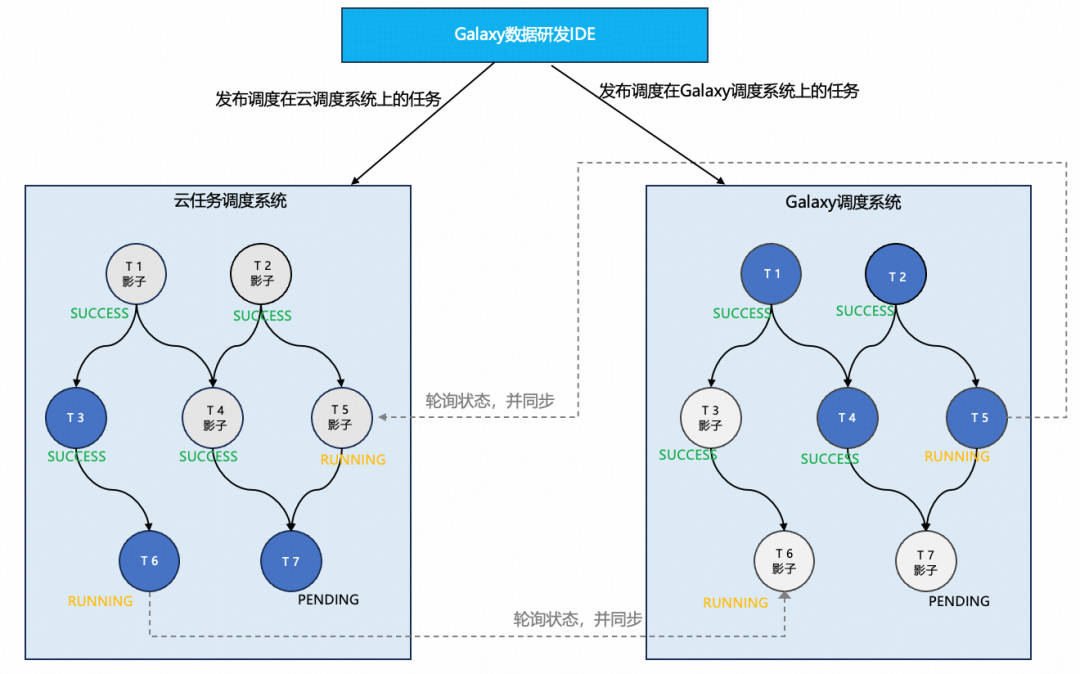
### **3. Task Migration Plan**
From cloud → Galaxy:
- Migrate **platform layer** first (low risk).
- Schedule migrations later.
- Supports both schedulers concurrently.
- **Shadow nodes** ensure transparent, reversible migration.
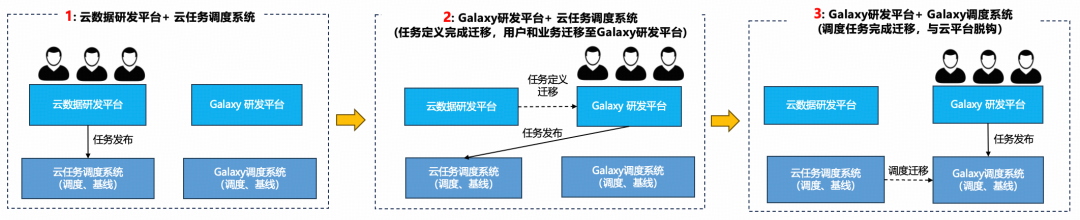
---
### **4. Functional & Migration Progress**
**Function Alignment:**
- Full feature parity with cloud platform.
- Optimized Spark queries & ingestion.
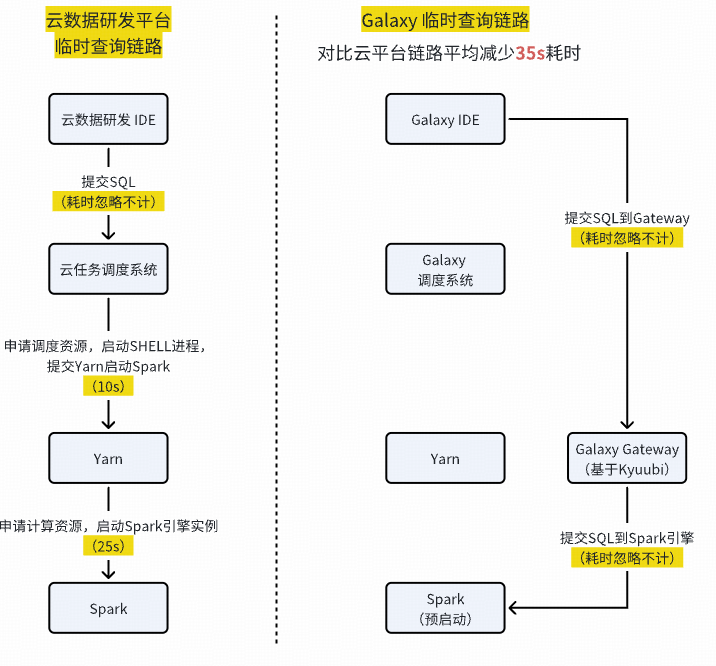
- **Query wait reduction**: 290+ person-days/month saved.
**Automation Gains:**
- Auto MySQL ingestion: +20 person-days/month saved.
**Migration Status:**
- 44% teams migrated; reduced cloud DEV compute by 400+ CU (~¥20K/month).
---
## **IV. The "Chassis" — Data Architecture Technology**
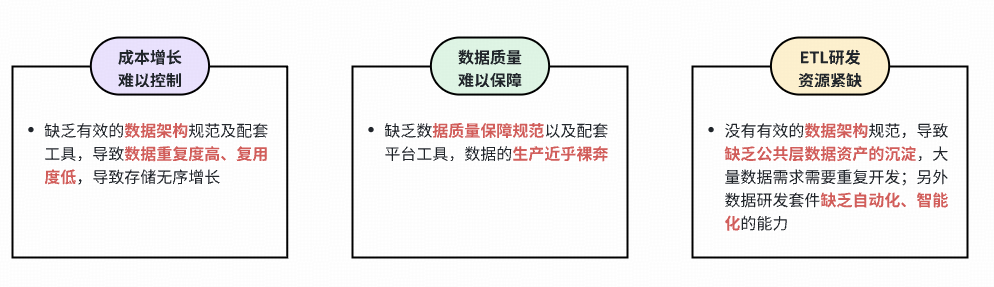
### Challenges:
- Difficult to **find/use** data.
- Duplicate & siloed datasets → ↑cost, ↓accuracy.
Example: Community domain had:
- **54%** redundant data expressions.
- **35%** duplicate metrics.
---
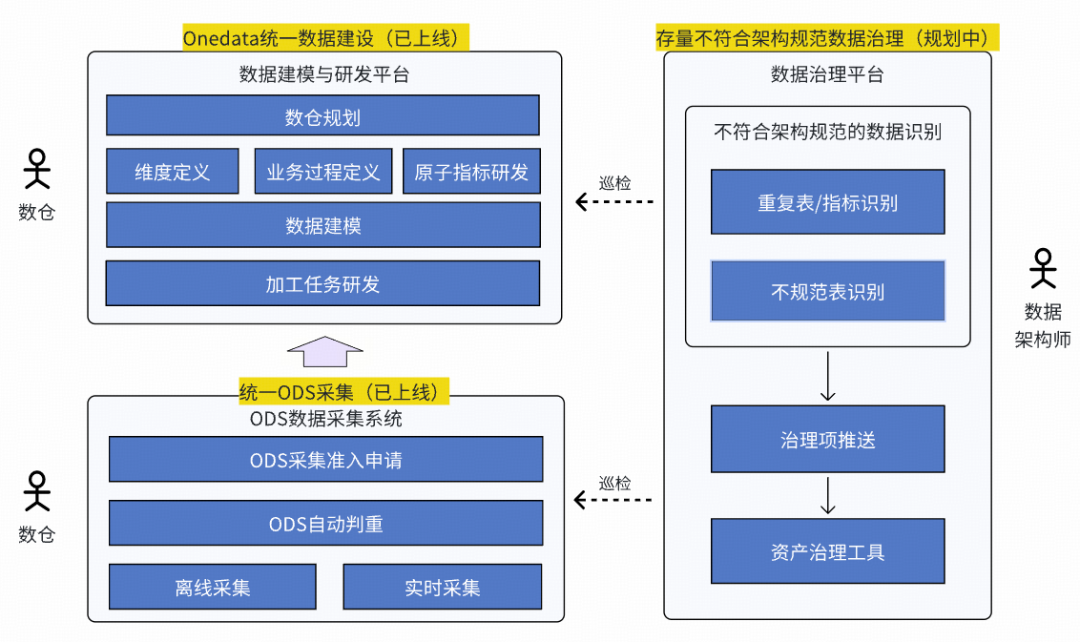
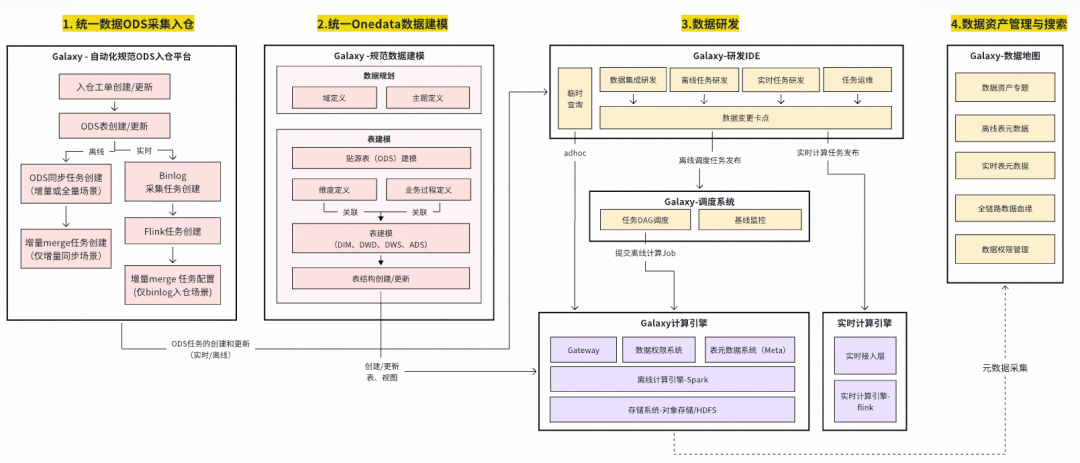
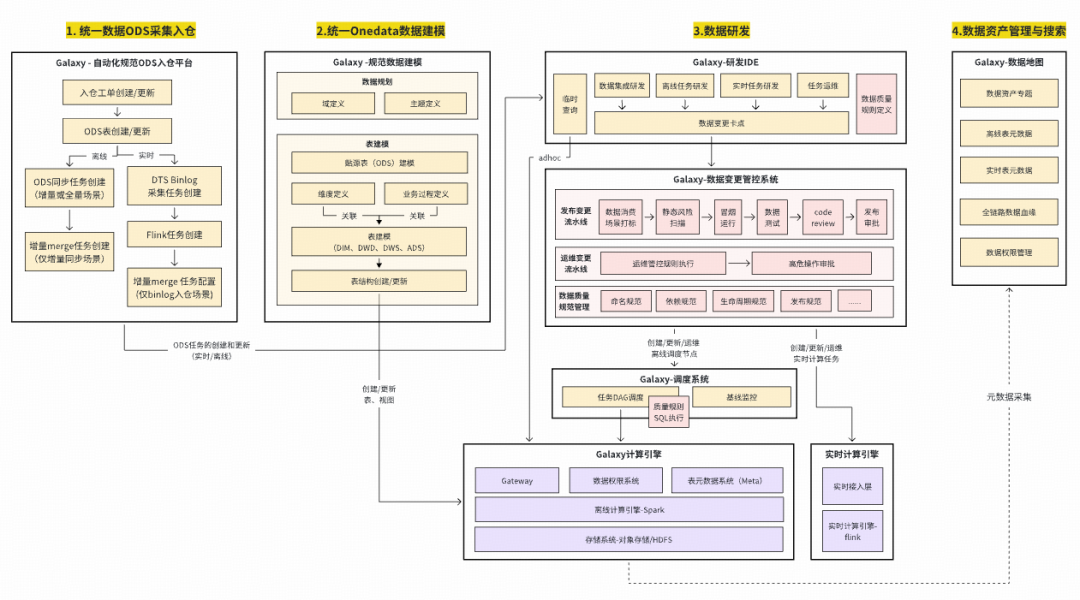
### **1. Onedata Methodology**
- Unified **standards** for ingestion & production.
- Integrated into Galaxy for ODS entry compliance and governance.
---
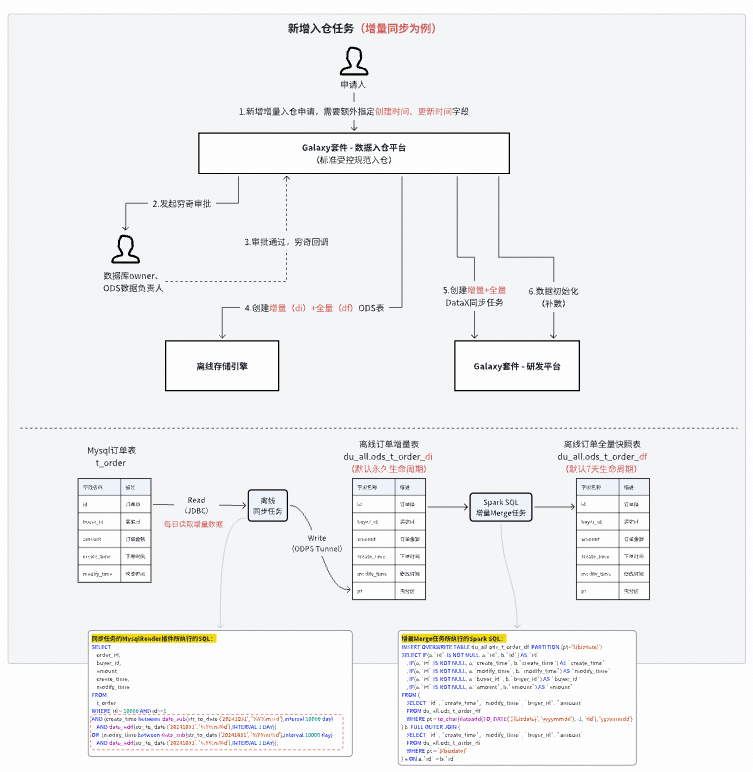
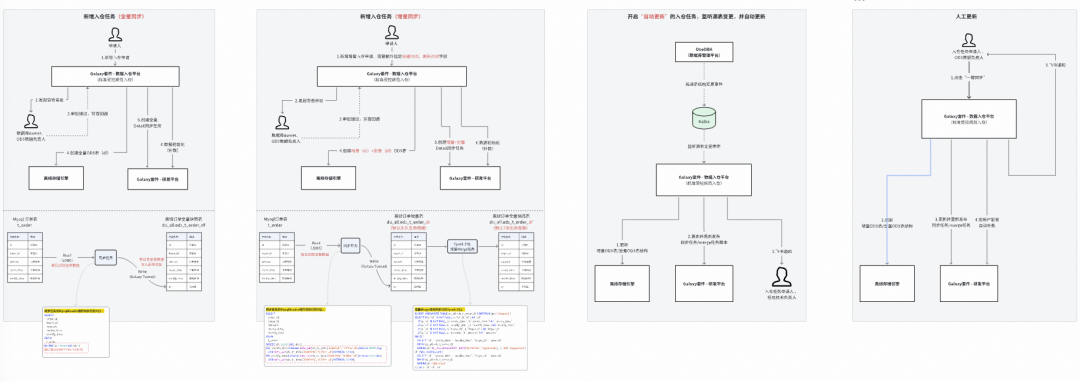
### **2. Unified ODS Ingestion**
Goals:
- Avoid duplicates.
- Enforce dual-owner approval.
- Control lifecycle.
- No manual coding.
Supports MySQL & TiDB; auto-update mode.
---
### **3. Standardized Modeling & Automated Metrics**
**Dimensional modeling** ensures:
- Consistent dimensions/metrics.
- Reuse & efficiency.
- Transparent models.
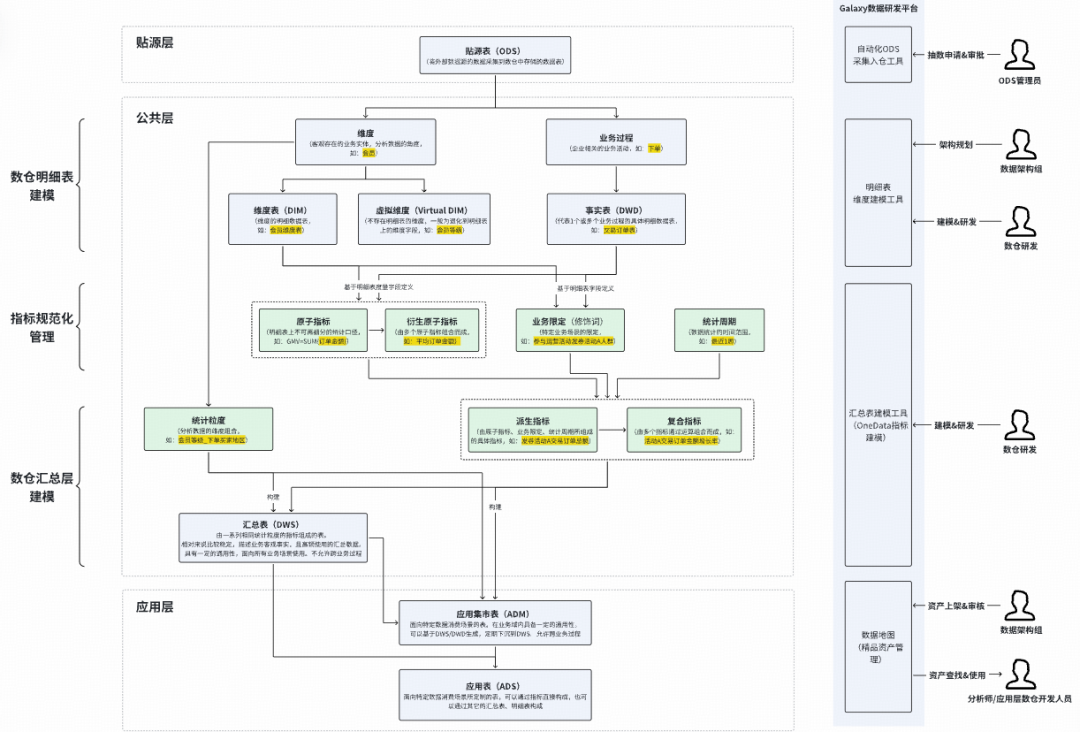
**Metric Modeling:**
Break metrics into:
- Atomic metric
- Business constraint
- Statistical period & granularity
Automated code gen from atomic definitions.
---
#### **Automated Metric Code Generation**

**Example Modeling:**
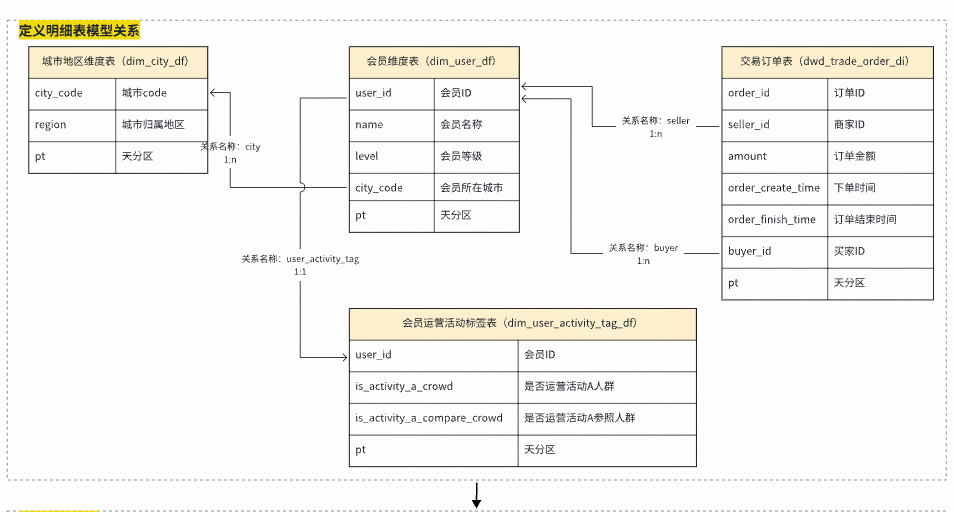
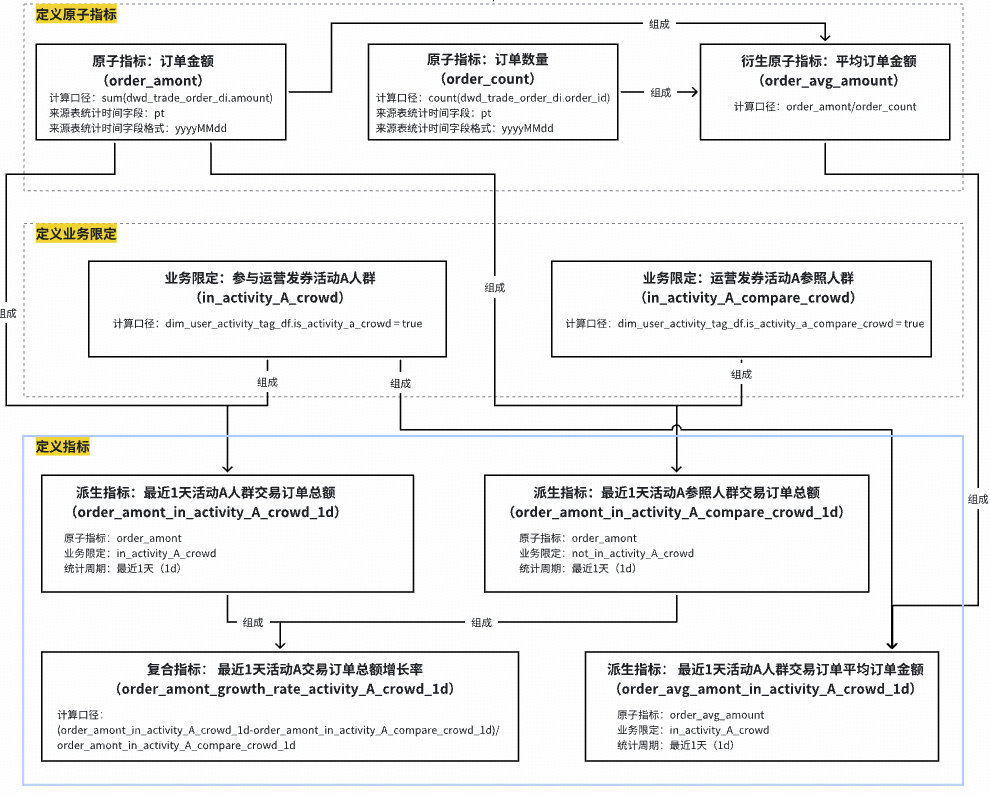
**Code Generation:**


**Optimization Rules:**
 … 
---
### **4. Implementation Outcomes**
**Automated ODS Ingestion:**
- 93.6% tasks auto-generated by Q3 2025.
- ODS lifecycle definition rate ×7.4.
- Storage growth cut from 32% → 8%.
**Onedata Modeling:**
- Merchant domain: +40% efficiency, throughput ↑ 75% → 90%.
- Community domain: 100% unambiguous metrics, 50K/month cost savings.
---
## **V. The "Brake Pads" — Data Quality Technology**
Tightly coupled to online P0 scenarios — quality failure risks are high.
---
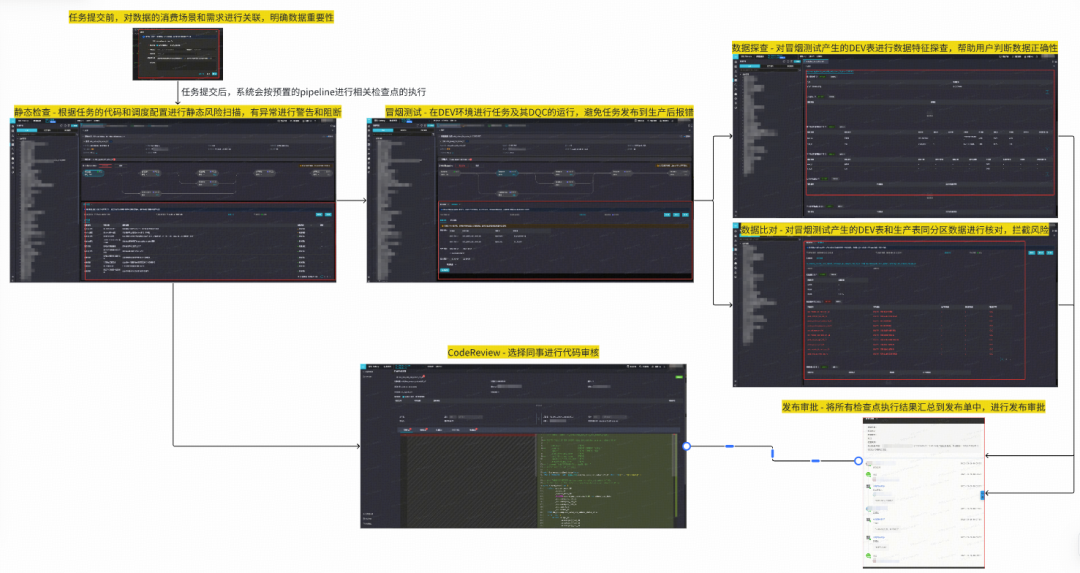
### **1. Galaxy QA Toolset**
- **Validation Rules** → prevent downstream contamination.
- **Change Control Pipeline** → scenario tagging, risk scanning, CR, testing, approval.
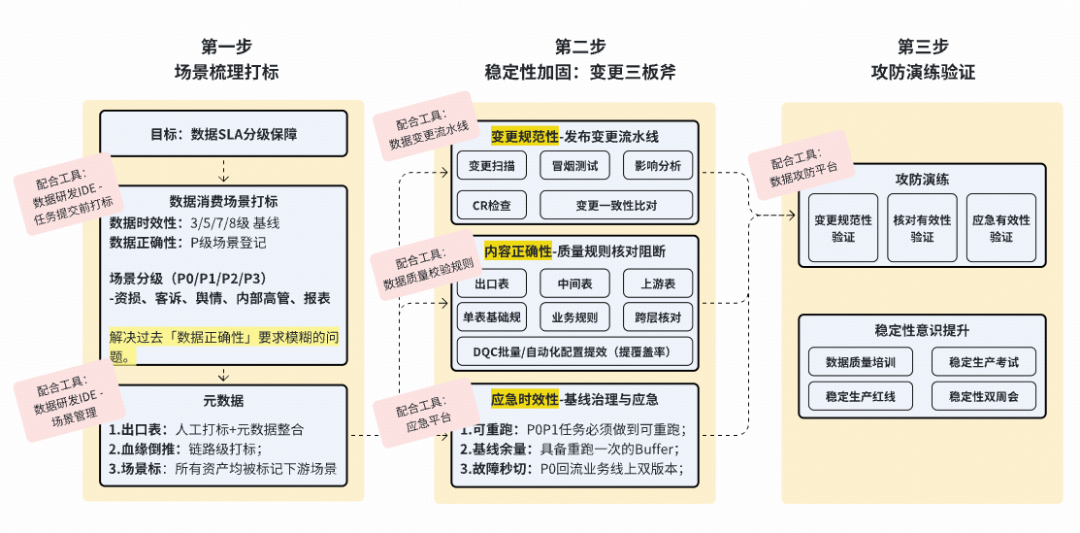
---
### **2. Progress**
**Validation Rules:**
- 15 rule types, 100% coverage.
- Added 1,200 rules Q3 2025.
- P0 tasks: 100% table & critical field coverage.
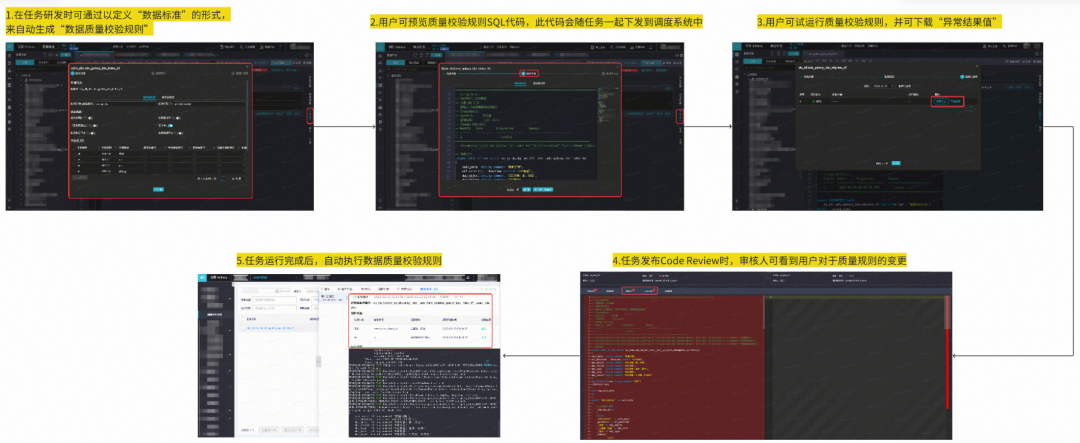
**Pipeline:**
- 98.3% tasks scenario-labeled.
- 48 risk rules; 94% coverage.
- 98% automated detection.
---
## **VI. "Assisted Driving" — Intelligent Data Development**
### **1. Roadmap**
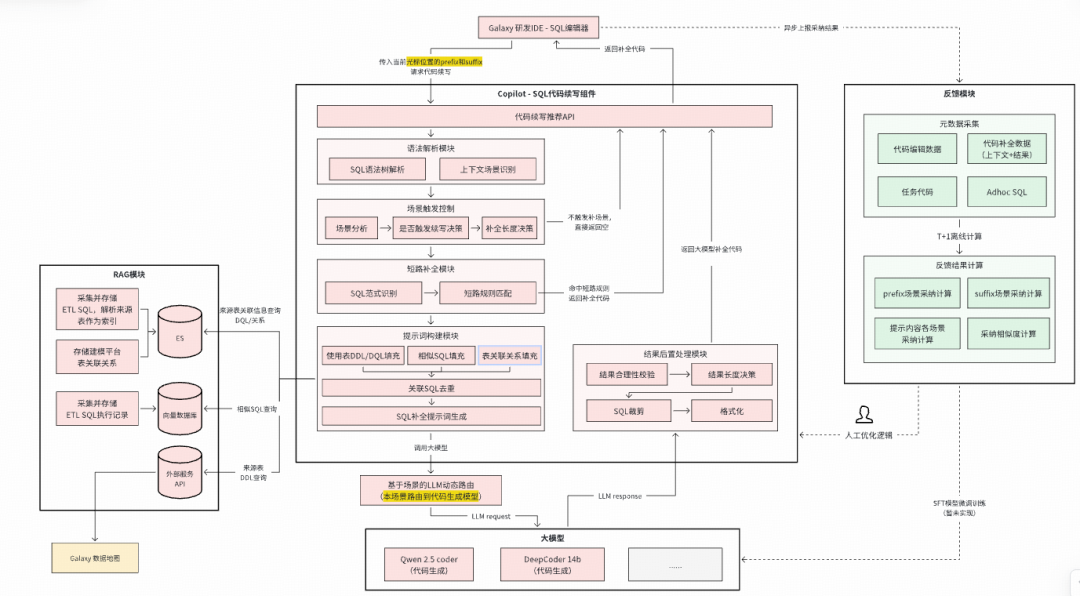
- **L1 Copilot** → SQL autocomplete, diagnosis, correction, rule recommendations.
- **L2 ETL Agent** → NL2Metric2SQL.
- **L3** → Data Logicalization.

---
### **2. Intelligent SQL Autocomplete**
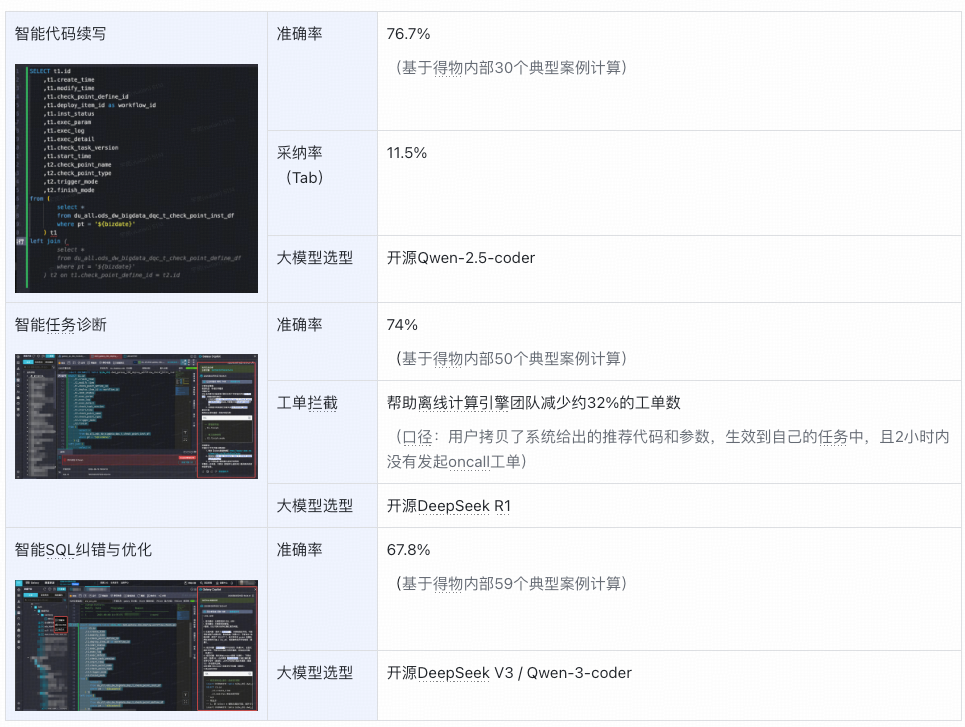
Model: **Qwen-2.5-coder**

---
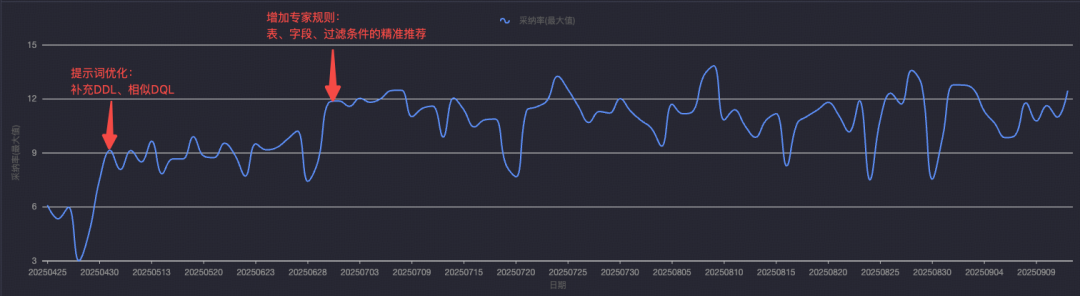
### **3. Progress**
- Features: Code continuation, Task diagnosis, SQL correction/optimization.
- 98.5% activation among high-activity users.
---
## **VII. Future Plans**
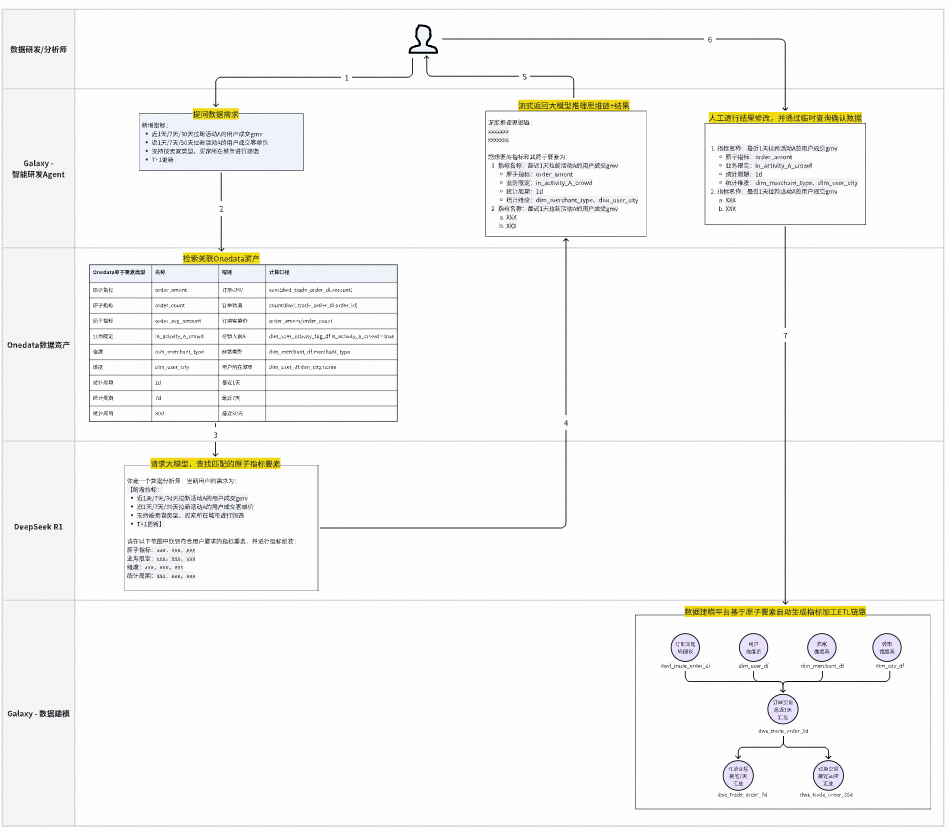
### **1. Long-Term Plan: Intelligent ETL Agent (L2)**
**Goal:** Convert NL requirements → correct ETL pipelines via Onedata model.
Workflow:
- NL parse → vector DB similarity match → atomic metric elements → SQL gen.
---
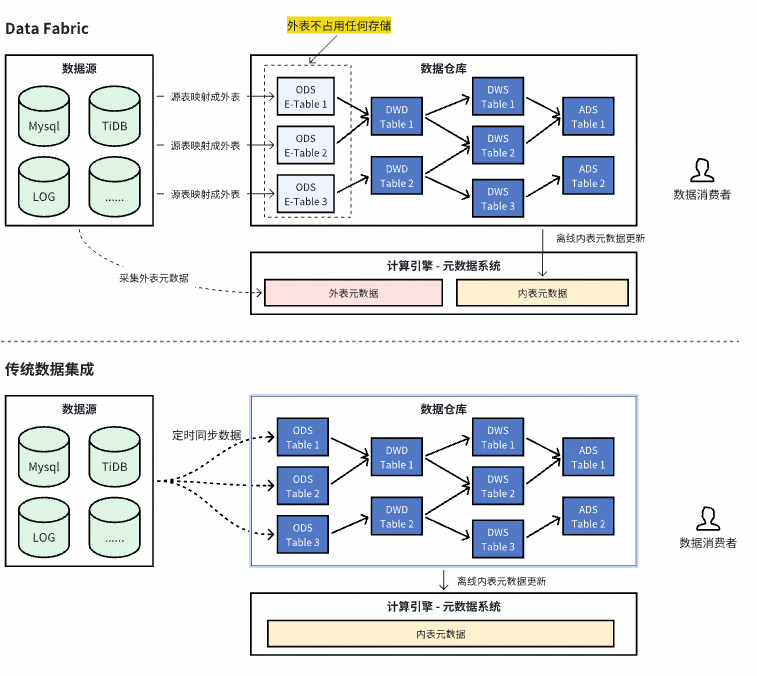
### **2. Long-Term Plan: Data Fabric**
**Concept:** “Move computation, not data.”
- Wrap sources as **external tables**.
- Unified metadata.
- Federation via Spark cross-source queries.
---
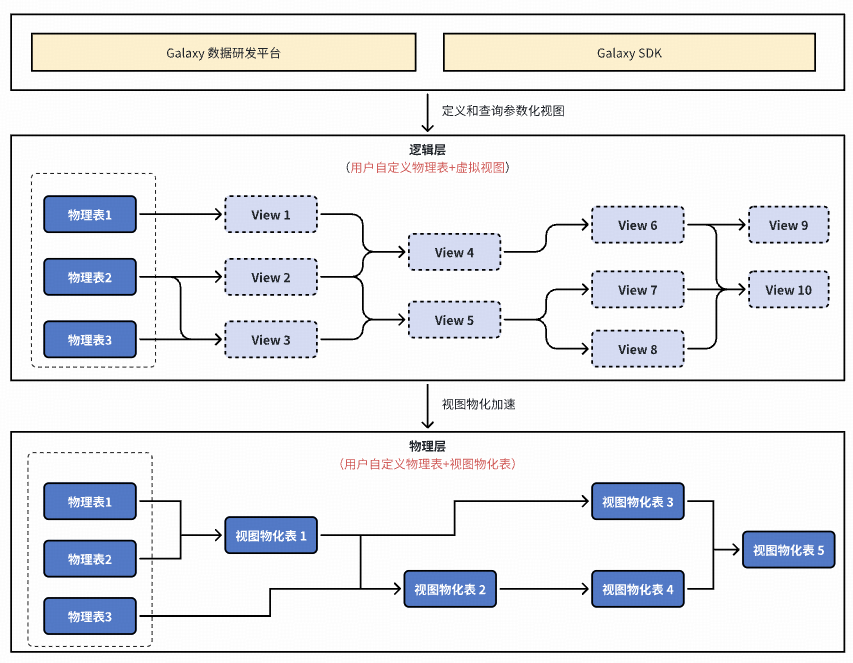
### **3. Long-Term Plan: Data Logicalization (L3)**
**Goal:** Minimize storage, optimize compute.
- Build pipelines with views.
- Use **materialized view hit detection** &
**materialization/recycling strategy**.
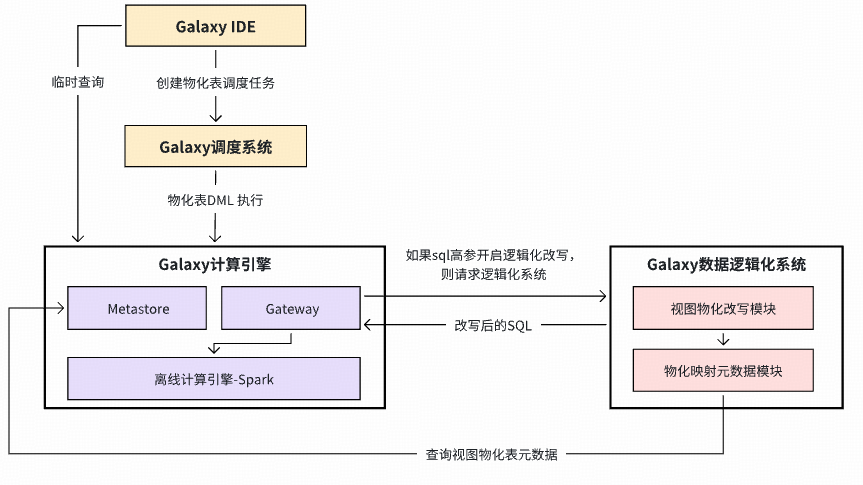
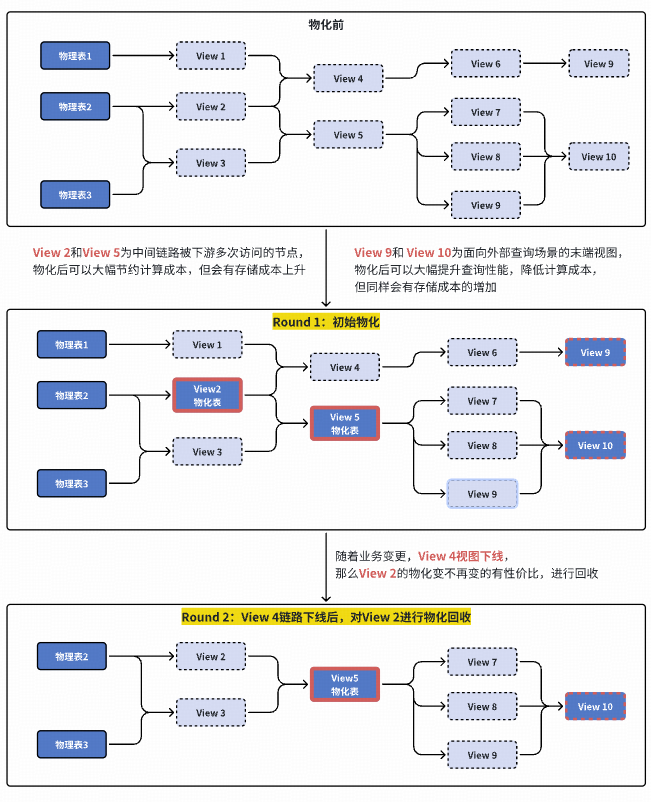
Algorithms for optimization: **Genetic**, **Simulated Annealing**.
---
By combining **Data Fabric** and **ETL Agent** with logicalization, Galaxy aims to reach **full intelligent L3 stage**—self-managed, AI-assisted data development meeting global efficiency benchmarks.