Current LLMs Waste 96% GPU — Inference Systems May Need a Rethink! NVIDIA’s Chinese Team Achieves Nearly 6× Token Speed with Free Token Slots, No Closed-Source Dependency

# 🚀 Another Masterpiece from a Chinese AI Team



**Edited by | Yun Zhao**
---
## Introduction
If you’ve ever worked on Large Language Models (LLMs), you know the pain:
**Inference is too slow.** Sometimes it takes *2–3 seconds to generate just a single token*.
Even worse, the GPU sits mostly idle while you wait — yet no matter what tricks you try, CUDA cores barely engage.
> **Root cause:** It’s neither your hardware nor just your code — the bottleneck lies in the architecture of *autoregressive language models* and the way GPUs operate.
---
## The “Memory Wall” Problem
### Why More Compute Won’t Help
Autoregressive models generate only **one token at a time**.
Although language is sequential, GPU inference processes each token with these steps:
1. Load model weights from VRAM (gigabytes of data).
2. Load Key–Value (KV) cache from VRAM.
3. Compute the next token’s probability (microseconds).
4. Write new KV cache.
5. Repeat for every token.
**Core issue:**
The *calculation time* is tiny — **memory bandwidth** is the true bottleneck. Constant VRAM reads/writes keep GPUs waiting for data instead of computing.
This is **memory-bound performance**, meaning simply adding compute power won’t significantly improve speed.
---
## Industry’s Common Fix: Speculative Decoding
A smaller **draft model** proposes multiple candidate tokens in one step, and the main model then verifies them.
**Limitations:**
- Draft models are weaker → **low acceptance rates**.
- Still **sequential** processing.
- Requires **two separate models** to maintain.
---
## A Better Alternative: Free Token Slots
There’s a lesser-known GPU inference opportunity: **Free Token Slots**.
If VRAM bandwidth is the limiting factor, you can decode multiple tokens in parallel **within the same forward pass** without major latency increase.
> Loading weights & KV cache for a single token is wasteful — reuse the loaded data to output more tokens.
**Idea:** Once the data is in memory, why not predict *10 tokens* instead of 1? This can increase throughput by ~10× with negligible extra compute cost.
---
## NVIDIA’s TiDAR Innovation
NVIDIA’s recent paper, *“TiDAR: Think in Diffusion, Talk in Autoregression”*, introduces **TiDAR** — led by a team with many Chinese authors.

### Key finding:
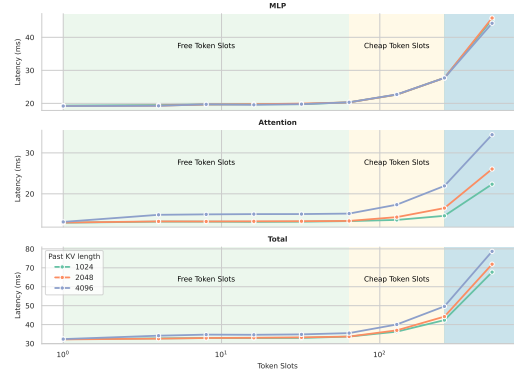
On H100 GPUs using Qwen3-32B:
- With **batch = 1**, **context = 4096 tokens**, decoding multiple tokens barely impacts latency until around **100+ tokens**.
- Below this threshold lies the **Free Token Slot zone**.
---
## Why Diffusion-Based LLMs Tempt Developers
**Diffusion LLMs** predict multiple tokens in one pass — perfect for free token slots.
However, output **quality drops** due to disrupted causal structures.
---
## Quality vs Parallelism — The Trade-off
**Autoregressive chain rule:**p(x₁, x₂, …, xₙ) = p(x₁) × p(x₂|x₁) × p(x₃|x₁, x₂) × …
Each token depends on all preceding tokens.
**Diffusion parallel decoding:**p(x₁, x₂, …, xₙ) ≈ p(x₁) × p(x₂) × p(x₃) × …
Tokens are **independent**, breaking sequence coherence.
Example: Dream-7B’s GSM8K accuracy drops **10%** when predicting 2 tokens per step.
---
## TiDAR = Diffusion Speed + Autoregressive Quality
### Core concept:
> **Think in diffusion, Talk in autoregression.**
> Generate in parallel, but verify sequentially — all in **one forward pass**.
---
### TiDAR Process Overview
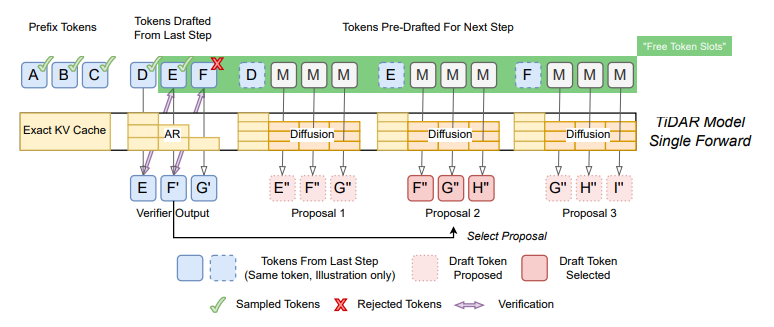
Categories in each step:
1. **Prefix tokens** — already accepted; causal attention; cached.
2. **Draft tokens** — from previous step; verified autoregressively; accepted ones join prefix.
3. **Pre-draft tokens** — predicted for next step with bidirectional attention; multiple sets tested during verification.
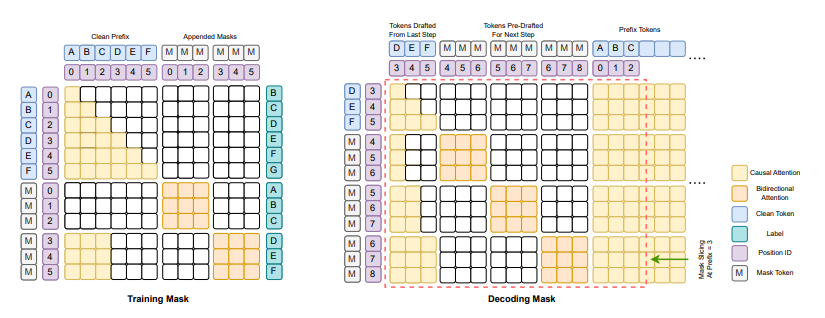
Structured attention masks make **drafting + verification happen simultaneously**.
---
### Why It Works
- **Strong drafts** — same model as verifier → no weaker draft model.
- **Parallel generation** — uses free token slots effectively.
- **High quality** — AR verification preserves chain-factorized joint distributions.
- **Single forward pass** — avoids double inference.
---
## TiDAR Training Strategy
**Attention mask:**
- **Causal** for prefix.
- **Bidirectional** for draft block.
**Benefits:**
- Dense loss signals across all tokens.
- Balanced AR/Diff training without random masking.
- Perfect training–inference consistency.
---
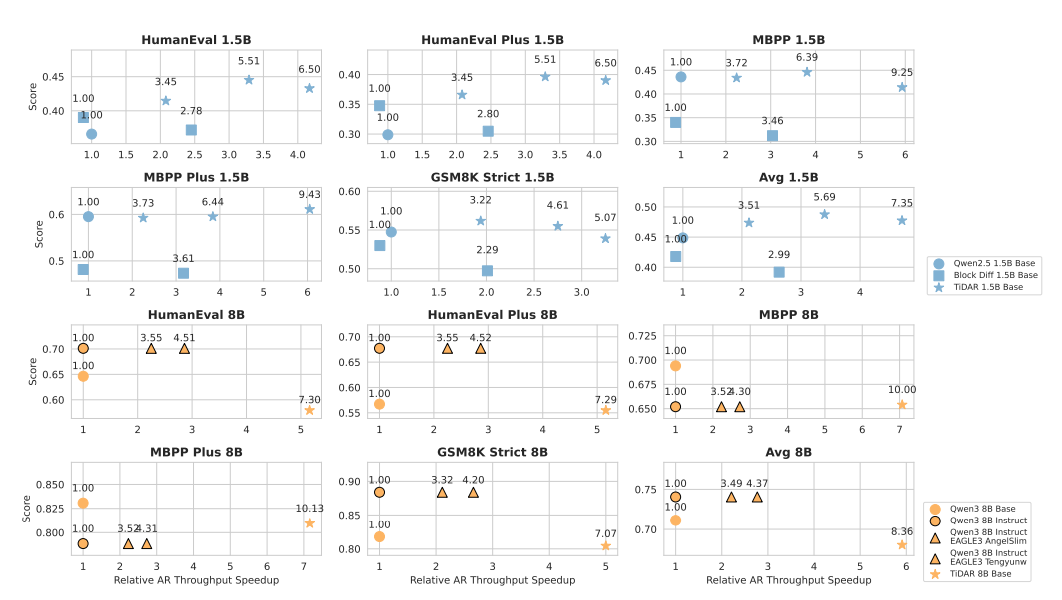
## Performance Gains: Up to ~6× Faster
**Results:**
- TiDAR 1.5B → 4.71× faster than Qwen2.5 1.5B (same quality).
- TiDAR 8B → 5.91× faster than Qwen3 8B (quality nearly unchanged).
Tokens per single forward: **5–9** instead of just 1.
**Benchmarks:**
---
## System-Level Impacts
### 1. Better Memory Flow
TiDAR: Single model, single weights, precise KV cache management → **no constant recomputing** or data shuffling.
### 2. Faster Operator Execution
Uses **structured masks + Flex Attention** — precompute mask once, then slice per step.
### 3. Easier Deployment
One model; no sync issues; cleaner architecture → perfect for cloud services.
### 4. Higher Hardware Utilization
Fill GPU’s free slots → 5–6× throughput boost → latency down to ~200 ms.
### 5. Batching Considerations
Best for batch=1 scenarios (chatbots, code assist). Still competitive for large-batch cases.
---
## Cost Reduction Potential
Throughput ↑ by 5× → possible **80% infrastructure cost cut**.
Ideal for latency-critical tasks like:
- Real-time analytics
- Code completion
- Conversational AI
---
## Limitations
1. **Long-context training cost** — sequence length doubled.
2. **Batch-size sensitivity** — massive gains for batch=1; smaller gains as batch ↑.
3. **Hardware variability** — free token slot limits depend on GPU architecture.
---
## Conclusion
TiDAR proves you can break the **memory bandwidth bottleneck** without bigger GPUs — by rethinking attention structure and generation strategy.
If validated by community, this **Chinese-led innovation** may reshape how LLM inference systems are built, offering massive speed boosts without sacrificing quality.
---
**Paper:** [https://arxiv.org/pdf/2511.08923](https://arxiv.org/pdf/2511.08923)
**Reference:** [https://medium.com/gitconnected/why-your-llm-is-wasting-96-of-your-gpu-f46482d844d1](https://medium.com/gitconnected/why-your-llm-is-wasting-96-of-your-gpu-f46482d844d1)
---

