**2025-11-03 12:01 Beijing**
# Building a Million-Scale Medical Reasoning Dataset to Empower Small Models to Surpass Large Models

---
## **Introduction**
Reasoning Language Models (RLMs) have shown excellent results in mathematics and programming.
However, in **medical** domains—where accuracy depends heavily on expert knowledge—questions remain:
> **Can complex multi-step reasoning enhance models' medical QA performance?**
Constructing high-quality medical reasoning datasets is challenging due to:
- **Data scarcity**
Existing medical chain-of-thought datasets are small and lack scalable high-quality pipelines.
- **Single-source limitation**
Overreliance on outputs from one model underutilizes diverse reasoning strategies across models.
- **High costs**
Large-scale, high-quality dataset creation demands both heavy computation and human validation.
- **Lack of method comparison**
Few studies compare “detailed diagnostic reasoning” vs “direct conclusions” as training strategies.
The goal: **Infuse authoritative medical knowledge, expand knowledge boundaries, and generate rigorous multi-step reasoning paths**.
---
## **ReasonMed Framework**
### **Core Advantages**
1. **Integration of Multi-Source Knowledge**
~195,000 medical QA items from four benchmarks: **MedQA, MMLU, PubMedQA, MedMCQA**.
2. **Multi-Model Data Construction**
Different proprietary models generate & cross-verify reasoning paths for broader coverage and consistency.
3. **Multi-Agent Verification & Optimization**
Tiered “Easy–Medium–Difficult” pipelines with multi-agent checks for logical, factual, and clinical accuracy.
4. **Reasoning Path Injection & Refinement**
Full multi-step CoT paths plus concise answers for dual supervision.
> **ReasonMed370K**: Million-scale, high-quality reasoning dataset open-sourced by Alibaba DAMO Academy.
Small models trained on it outperform larger ones—e.g., **PubMedQA**: 82.0% vs **LLaMA3.1-70B** at 77.4%.

**Resources**:
- **Paper:** [https://arxiv.org/abs/2506.09513](https://arxiv.org/abs/2506.09513)
- **Dataset:** [https://huggingface.co/datasets/lingshu-medical-mllm/ReasonMed](https://huggingface.co/datasets/lingshu-medical-mllm/ReasonMed)
---
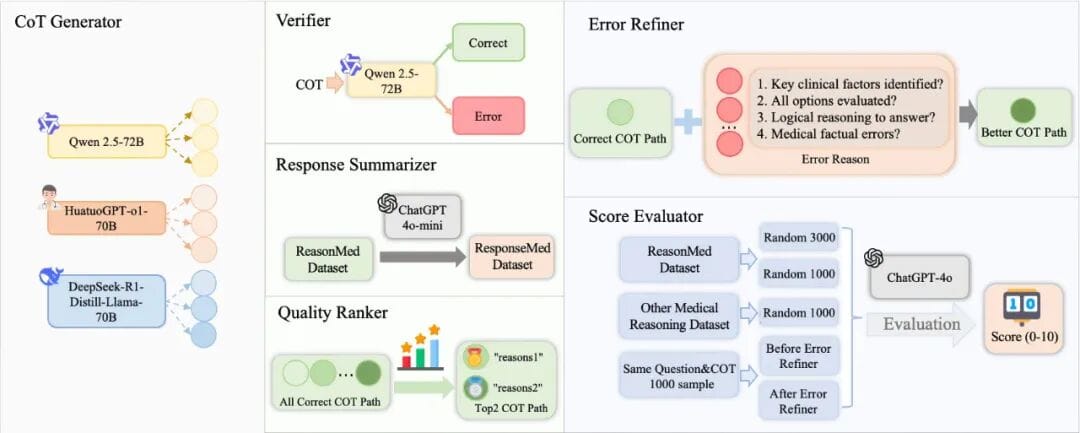
## **ReasonMed: Multi-Agent Collaboration Pipeline**
**Repo:** [https://github.com/alibaba-damo-academy/ReasonMed](https://github.com/alibaba-damo-academy/ReasonMed)
### **Main Agents**
- **CoT Generator**
Uses Qwen2.5-72B, HuatuoGPT-o1-70B, DeepSeek-R1-Distill-LLaMA-70B to diversify reasoning via multi-temperature prompts.
- **Verifier**
Checks correctness, clinical key points, logical consistency, and factual reliability.
- **Response Summarizer**
Produces concise clinical-styled conclusions.
- **Quality Ranker**
Selects top-2 best reasoning paths after verification.
- **Error Refiner**
Corrects errors in difficult samples using stronger models.
- **Score Evaluator**
Measures quality improvement after refinements.
> Workflow: **Generate → Verify → Rank → Refine → Evaluate**
---
## **Data Generation Process**
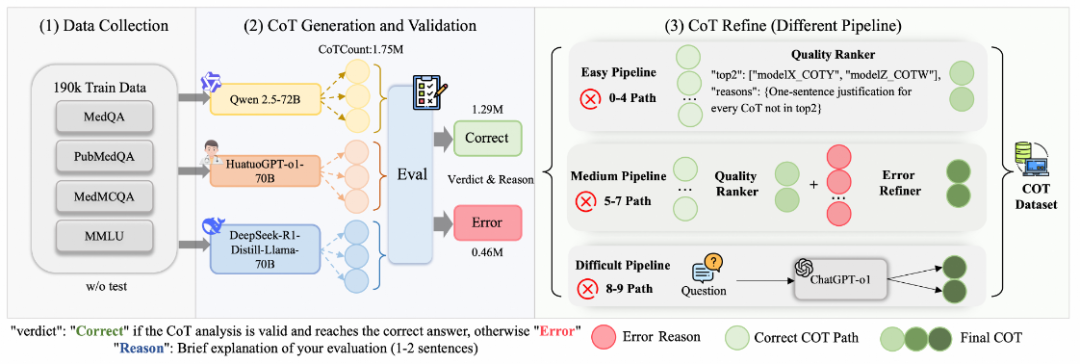
### **Step 1: Data Collection**
- Aggregate 195K questions from **MedQA, MedMCQA, PubMedQA, MMLU**.
- Covers anatomy, clinical medicine, genetics, etc.
### **Step 2: Multi-Agent CoT Generation & Validation**
- **9 reasoning chains per question** at varied temperatures.
- Verifier produces structured evaluations (pass/fail + reasons).
### **Step 3: Layered Optimization**
- **Pipelines:**
- *Easy*: Select top-2 reasoning chains directly.
- *Medium*: Error Refiner improves partially incorrect CoTs.
- *Difficult*: Strong models regenerate entire reasoning.
---
## **Multi-Tier Reasoning Pipeline**
- **Easy (0–4 errors)** → Quality Ranker output.
- **Medium (5–7 errors)** → Targeted Error Refiner corrections.
- **Difficult (8–9 errors)** → Full regeneration with GPT-o1.
**Results**:
- High precision maintained.
- **Cost down ~73%** while keeping quality.
---
## **Quality Evaluation**
Dimensions scored **0–10**:
- Logical coherence
- Factual fidelity
- Option analysis completeness
Final: **ReasonMed370K** = **370K samples** vs other datasets — **significantly higher scores**.

---
## **Data Variants**
- **CoTMed370K** – Detailed reasoning steps only.
- **ResponseMed370K** – Concise conclusion answers only.
- **ReasonMed370K** – Both reasoning chains + conclusions.

---
## **Model Performance**
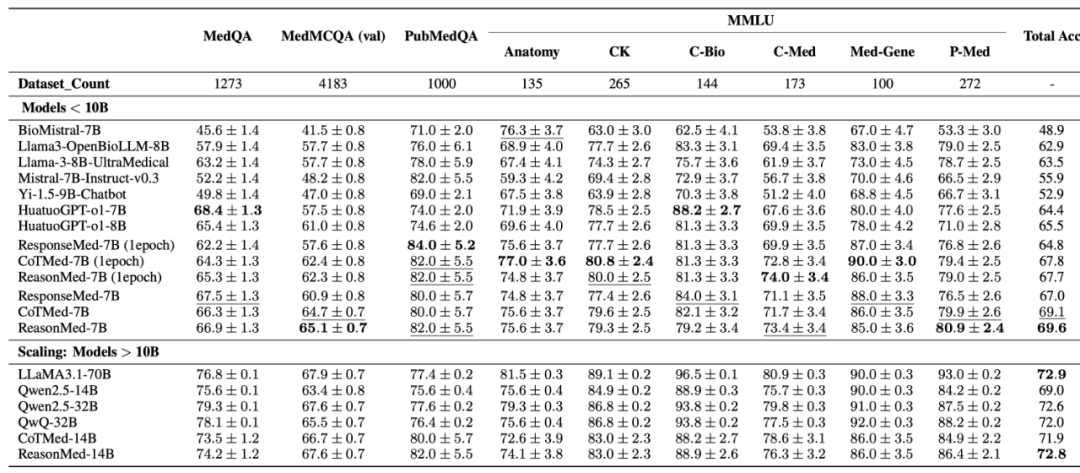
- **ReasonMed-7B / 14B** outperform larger models.
- PubMedQA: 82.0% (**7B**) > 77.4% (**LLaMA3.1-70B**).
- 14B variant matches or beats Qwen2.5-32B and rivals LLaMA3.1-70B.
---
## **Training Strategy Analysis**
### Fusion Strategy Works Best
- **CoTMed-7B** → Full reasoning paths: 69.1%
- **ResponseMed-7B** → Summaries only: 67.0%
- **ReasonMed-7B** → Fusion: **69.6%**
**Conclusion:** Combining reasoning + summaries yields best balance.
---
## **Cost-Efficiency via Hierarchical Processing**
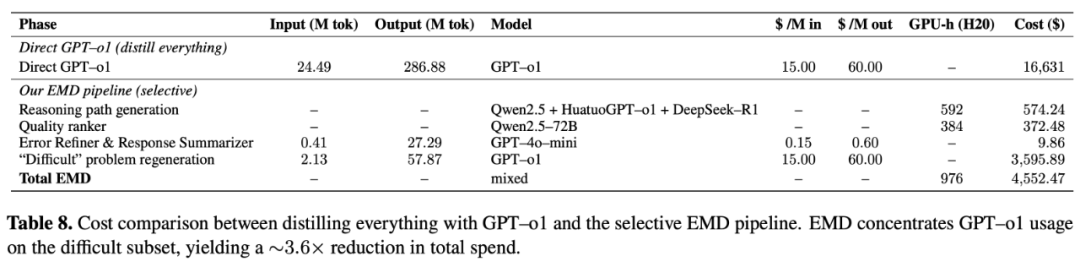
Without hierarchy: $16,631
With hierarchy: **$4,552** (~70% savings).
Only 2.56% hardest cases use strongest models.
---
## **Significance & Outlook**
- **Largest high-quality open-source medical reasoning dataset**.
- Validates benefit of *explicit reasoning paths*.
- Promotes **small model + high-quality data** approach.
- Adaptable across domains like life sciences, materials science.
- Potential for multimodal expansion (imaging, medical tools).
---
## **Community Impact**

- Hugging Face “Paper of the Day”.
- Shared by HF CEO on X.
- Active industry discussion.
---
### Complementary Platforms
[AiToEarn官网](https://aitoearn.ai/) & ecosystem:
Supports AI content creation, cross-platform publishing (Douyin, Bilibili, X), analytics, and monetization.

---
### Contact
Please request authorization before republishing.
Email: **liyazhou@jiqizhixin.com**
[Original](2650999559) | [Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=208de1c1&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzA3MzI4MjgzMw%3D%3D%26mid%3D2650999559%26idx%3D3%26sn%3D221f5b922954c29320960b0d14187b3a)
---