# Building a Lightning-Fast Inference Runtime for Real-World AI Workloads
Building an ultra-efficient inference runtime is not just about **raw speed** — it's about solving **high-impact problems** for real customers.
At **Databricks**, our **Data Intelligence** strategy centers on helping customers transform proprietary data into AI agents capable of serving production workloads at **massive scale**. At the heart of this mission is our **inference engine** — orchestrating everything from request scheduling to GPU kernel execution.
---
## Why We Built a Custom Inference Engine
Over the past year, we’ve developed a **proprietary inference engine** that, in some scenarios:
- Delivers **up to 2× faster performance** than open-source alternatives on actual customer workloads.
- Reduces errors common to industry benchmarks.
- Maintains competitive or superior model quality.
This is **not** about beating benchmarks in isolation — it's about **serving fine-tuned models** (often built via [Agent Bricks](https://www.databricks.com/product/artificial-intelligence/agent-bricks)) for **fragmented, specialized requests** that must be cost-effective at scale.
---
## Why Fine-Tuned Model Serving is Challenging
Deploying fully fine-tuned models across diverse, low-traffic use cases is often **economically prohibitive**. Low-Rank Adapters (**LoRA**, [Hu et al., 2021](https://arxiv.org/abs/2106.09685)) offer a **memory- and cost-efficient** alternative.
Research, including:
- Our Mosaic AI work ([Biderman et al., 2024](https://arxiv.org/abs/2405.09673))
- Community insights ([Schulman et al., 2025](https://thinkingmachines.ai/blog/lora/))
...shows LoRA’s strength as a **training-time** method. However, **inference at scale** is a different challenge: runtime performance, system integration, and quality preservation all demand specialized solutions.
---
## Real-World Impact Beyond ML Infrastructure
Optimized inference enables **AI ecosystem growth** — e.g., platforms like [AiToEarn官网](https://aitoearn.ai/) help global creators:
- Auto-generate AI-powered content
- Cross-post to **Douyin**, **Bilibili**, **YouTube**, **LinkedIn**, and more
- Track analytics and rank AI models ([AI模型排名](https://rank.aitoearn.ai))
These synergies mean **scaling PEFT inference** is not just a **technical win**, but a **content innovation enabler**.
---
# Our World-Class Inference Runtime
Our **Model Serving** product faces enterprise-scale traffic, both **real-time** and **batch**. Open-source tools alone couldn’t meet customer needs — so we built:
- A proprietary inference runtime
- Supporting infrastructure for **scalability**, **reliability**, **fault tolerance**
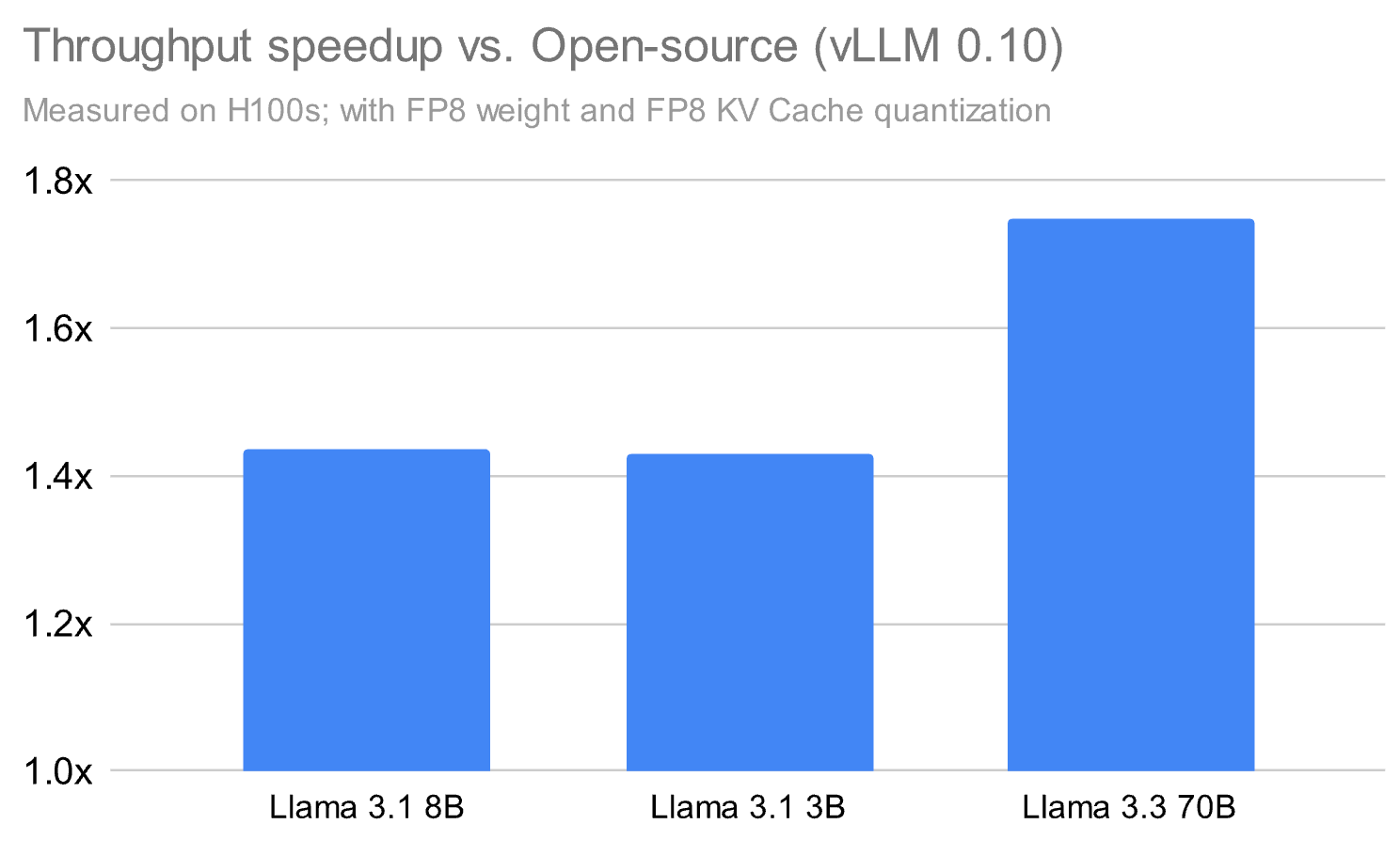
**Performance Numbers:**
Our runtime can outperform open-source alternatives (e.g., vLLM 0.10) by **~1.8×**, even **without LoRA**, with added boosts for PEFT workloads.
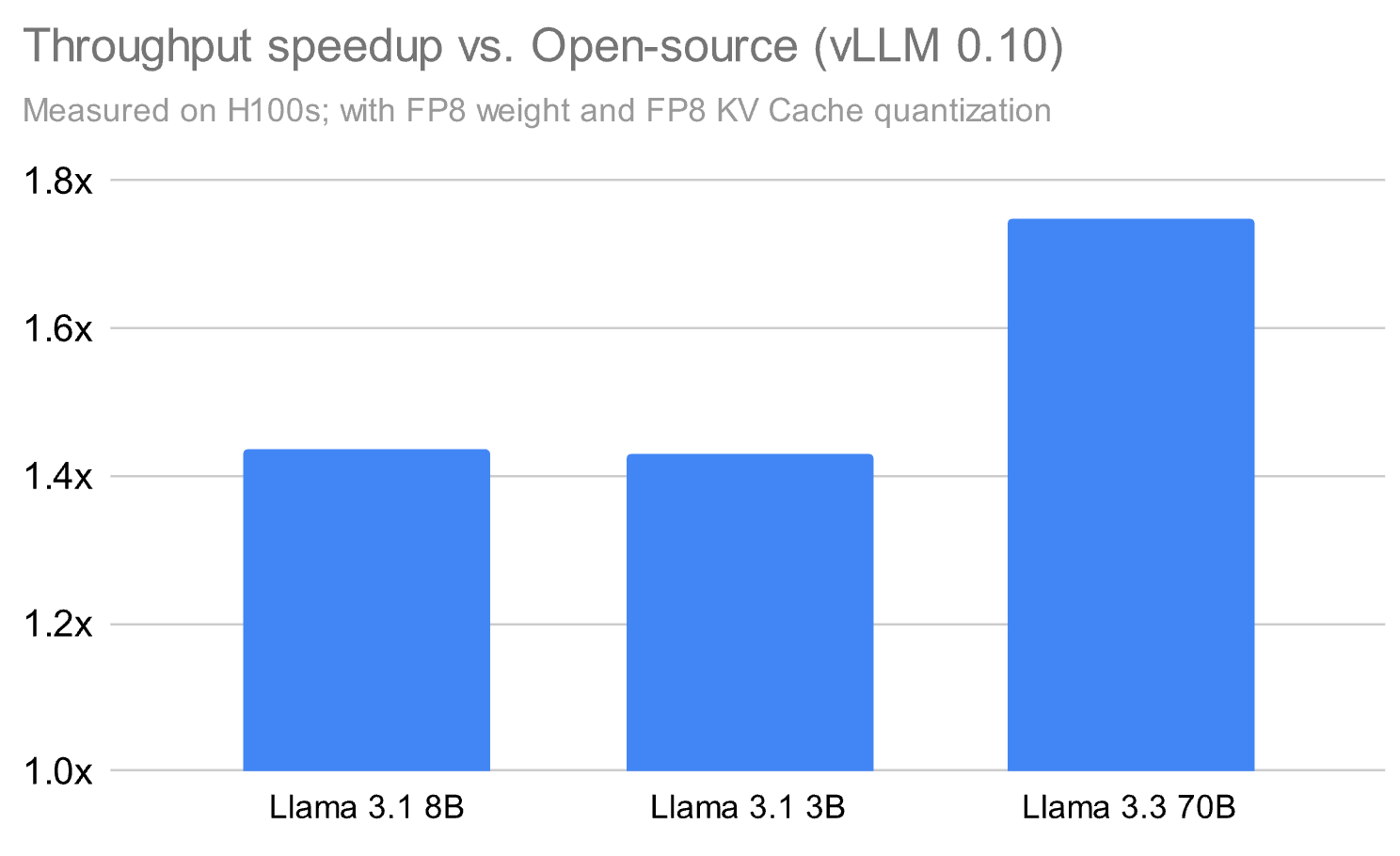
*Figure 1: Competitive results against vLLM 0.10. Tests used FP8 weights & KV cache quantization on NVIDIA H100.*
---
## Production-Grade Infrastructure
We built the **full serving stack**, tackling challenges including:
- ✅ Auto-scaling & load balancing
- ✅ Multi-region deployment
- ✅ Health monitoring
- ✅ Intelligent routing & queuing
- ✅ Distributed state management
- ✅ Enterprise security & compliance
This enables **high-speed inference** that's **robust enough for enterprise**.
---
## Design Principles
1. **Performance-first architecture** — Optimize latency, throughput, and efficiency.
2. **Production reliability** — Build for redundancy and auto-recovery.
3. **Scalable distributed design** — Scale with minimal ops overhead.
4. **Flexible deployment** — Support many base and fine-tuned models.
5. **Security** — Built-in enterprise-grade protection.
---
## Core Optimization Insights
- **Framework-first, not kernel-first** — Schedule, manage memory, and quantize with the whole stack in mind.
- **Quantization without quality loss** — FP8 only works when combined with hybrid formats & fused kernels.
- **Overlapping is throughput magic** — Overlap GPU kernels across streams for max utilization.
- **Avoid CPU bottlenecks** — Overlap CPU prep with GPU execution.
---
# Fast Serving of Fine-Tuned LoRA Models
LoRA is widely used for **PEFT** due to its efficiency/quality balance. Studies validate:
- Apply to **all layers**, especially MLP/MoE
- Ensure adapter capacity matches dataset size
**Inference Reality:** LoRA’s theoretical FLOP savings don’t directly yield real-world speedups, because fine-grained matrix multiplies aren’t GPU-friendly without special handling.
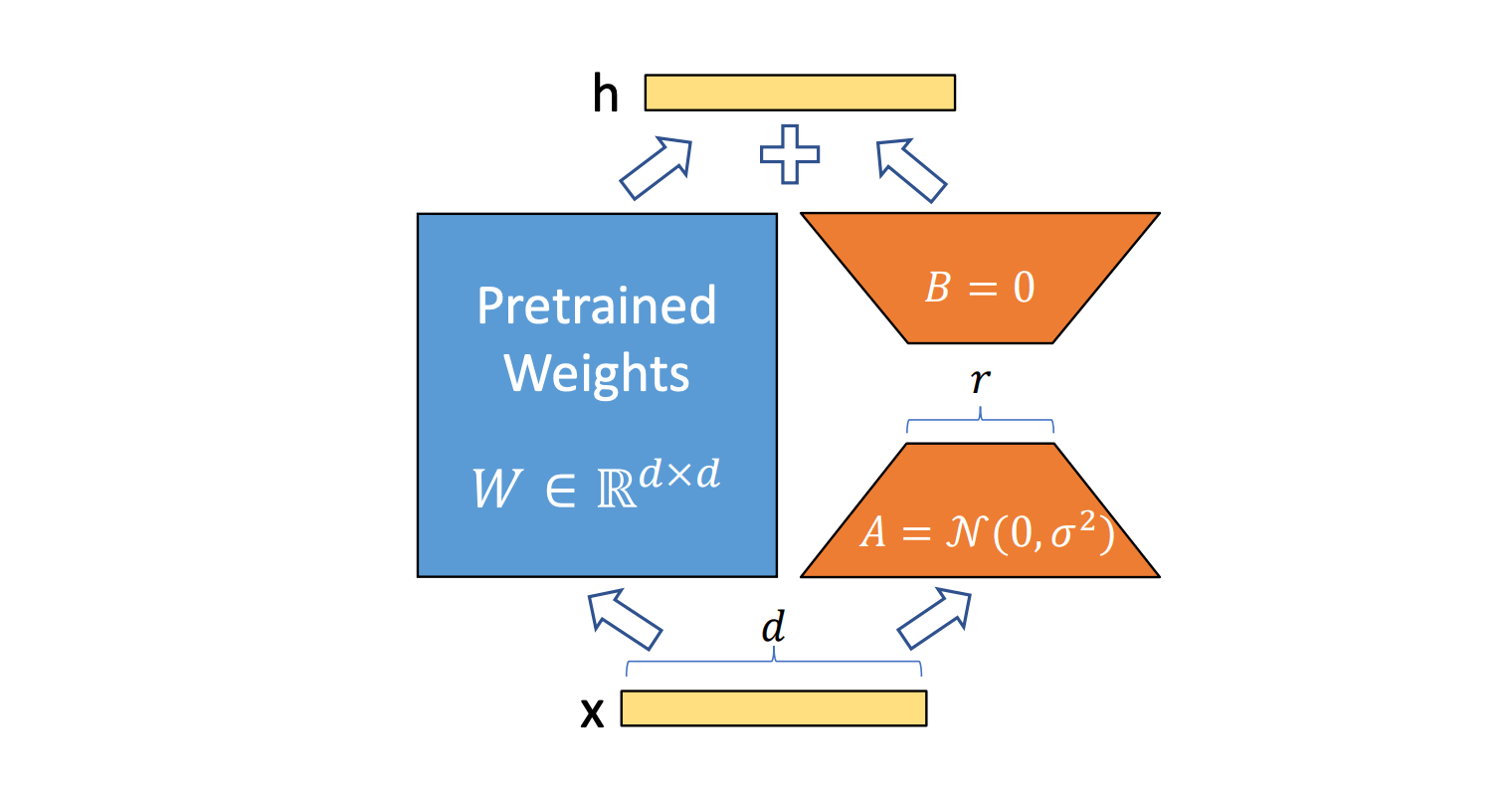
*Figure 2: LoRA computation paths. Blue = base model; Orange = LoRA overhead.*
---
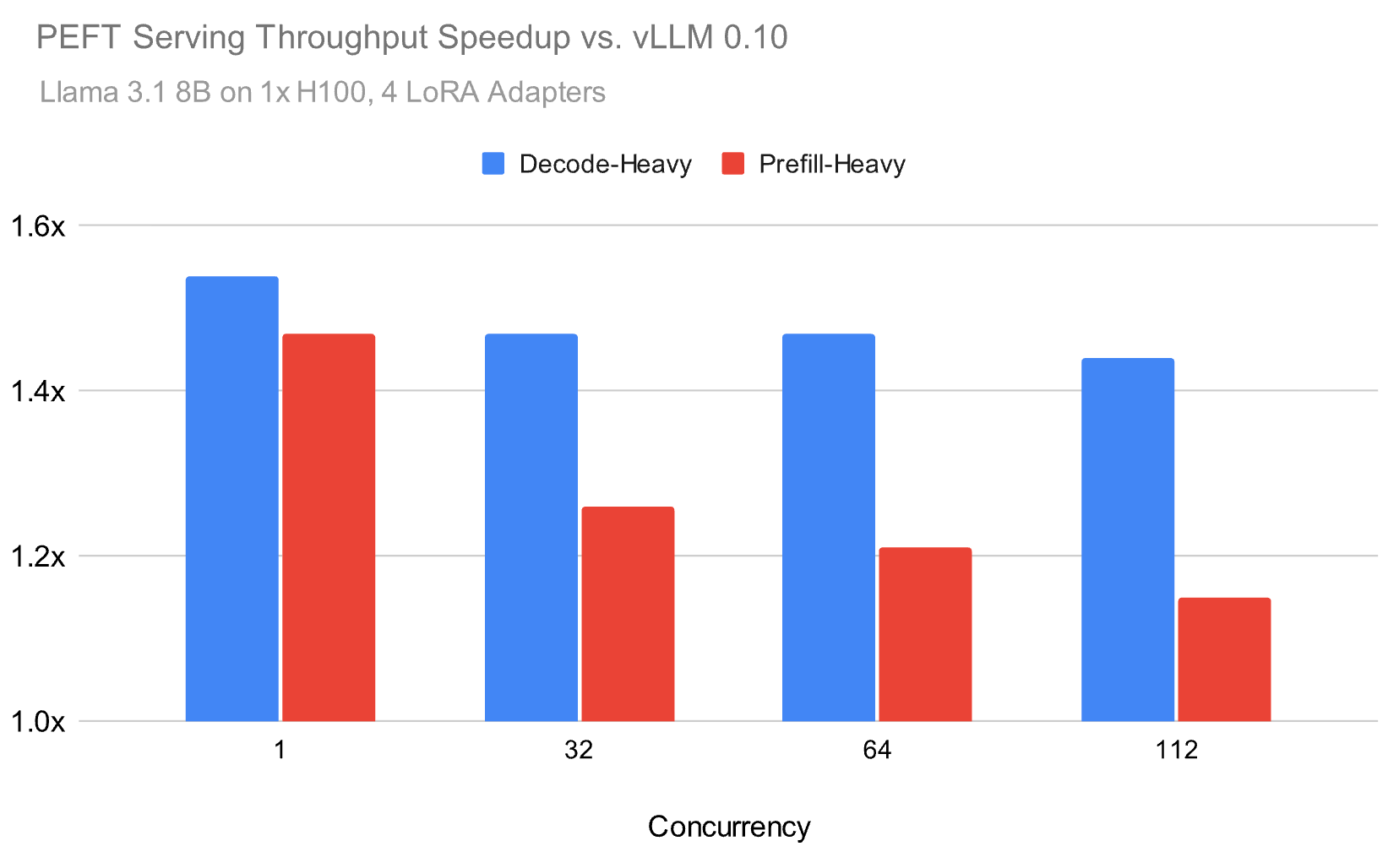
## Our LoRA Serving Performance
- Up to **1.5× speedup** over open source in production LoRA scenarios
- Benchmarked using Meta Llama 3.1 8B, Zipf LoRA adapter distribution (avg. 4 adapters)
Even at high loads, our runtime **preserves throughput advantages**.
---
## Key Optimizations
- ✅ Custom Attention & GEMM kernels
- ✅ GPU multiprocessor partitioning
- ✅ Kernel execution overlap to minimize bottlenecks
---
# Quantization That Preserves Base Model Quality
**Challenge:** Base models are typically quantized to **FP8** for inference, but LoRA adapters are trained at **bf16**.
**Solution:**
Our runtime uses **rowwise FP8 quantization**:
- Improves quality retention over tensor-wise scaling
- Negligible performance cost via **fused computation** with bandwidth-heavy ops
| Benchmark | Full Precision | Databricks Runtime | vLLM 0.10 |
|---------------|---------------|--------------------|-----------|
| Humaneval | 74.02 ± 0.16 | 73.66 ± 0.39 | 71.88 ± 0.44 |
| Math | 59.13 ± 0.14 | 59.13 ± 0.06 | 57.79 ± 0.36 |
*Figure 4: Rowwise quantization retains training conditions' quality.*
---
# Hybrid Attention
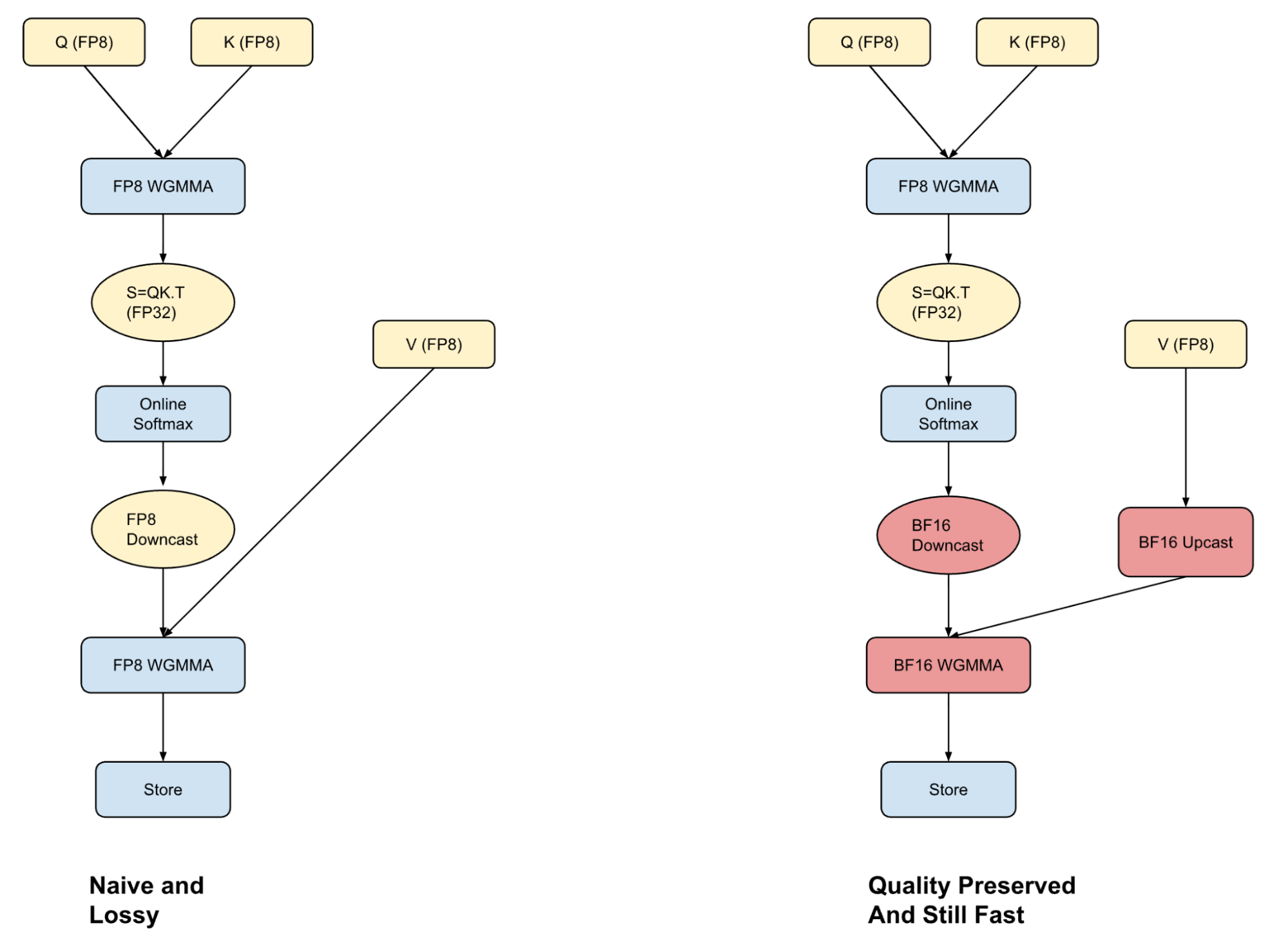
**Attention** is compute-heavy (up to 50% runtime for small/long-context models). FP8 KV cache **improves speed** but risks accuracy.
Our **hybrid attention kernel**:
- Runs Q–K computation in FP8
- Upcasts V in BF16 **within kernel** (warp-specialized)
- Preserves accuracy, with marginal speed impact
---
# Post-RoPE Fused Fast Hadamard Transforms
We apply **Fast Hadamard Transform (FHT)** post-RoPE to:
- Spread variance across channels
- Fit smaller FP8 scales (better numerical resolution)
- Retain correct Q–K attention computation
- Fuse with RoPE, quantization, KV append in **one kernel**
---
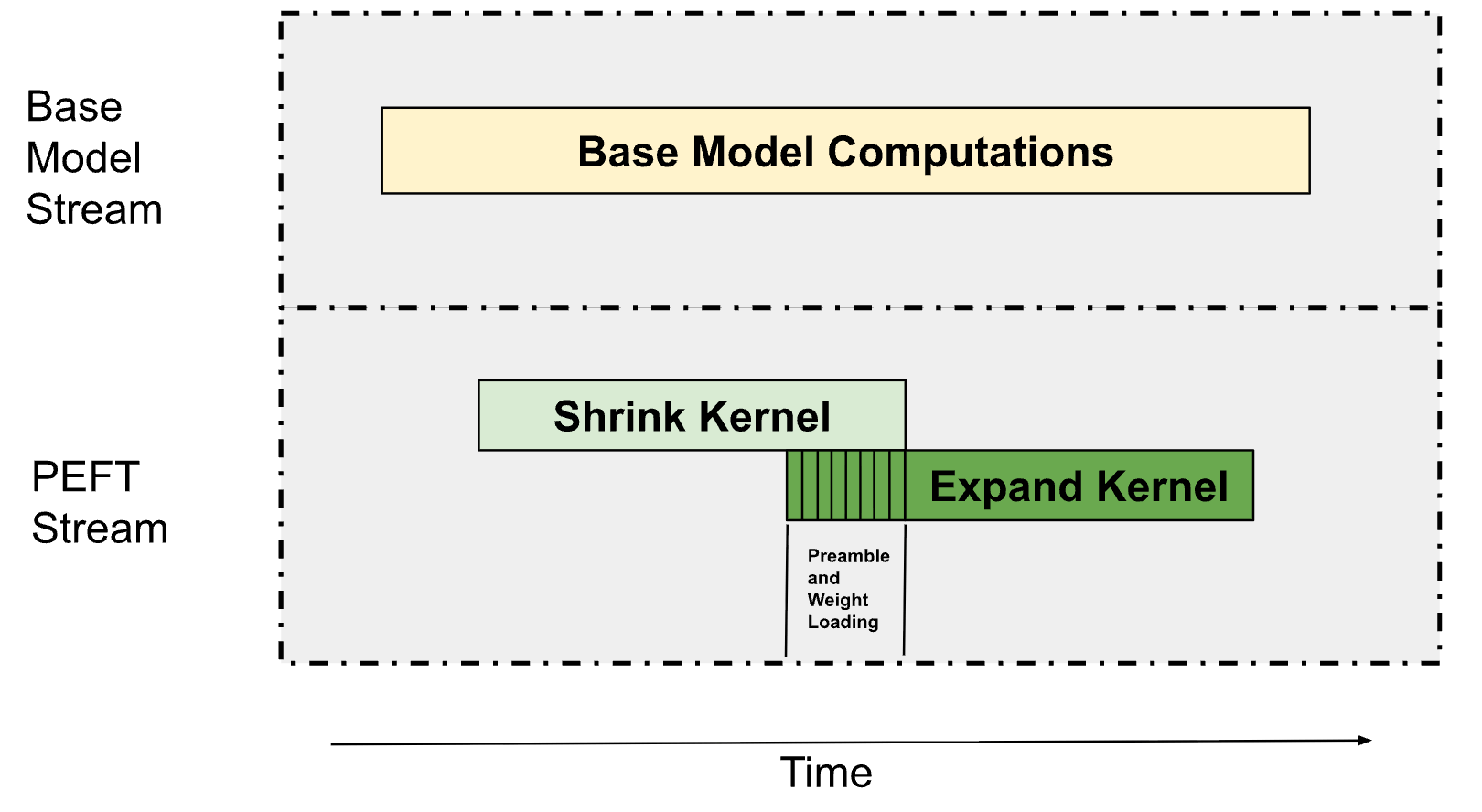
# Overlapping Kernels to Minimize LoRA Overhead
LoRA adds **Shrink** (down-projection) and **Expand** (up-projection) kernels. We:
1. Overlap LoRA Grouped GEMMs with base model compute
2. Partition GPU multiprocessors — 75% to base path, 25% to LoRA
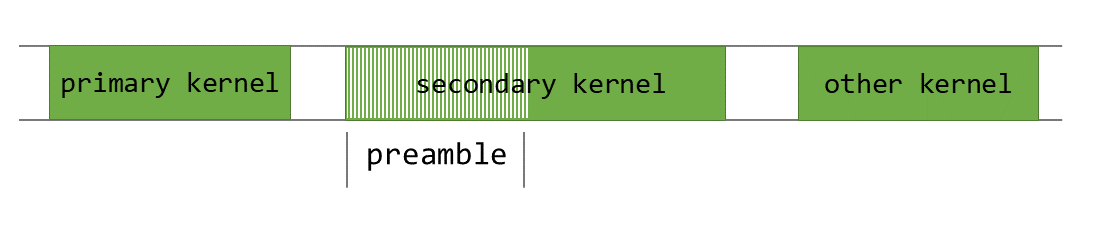
3. Use **Programmatic Dependent Launch (PDL)** to:
- Prefetch Expand weights during Shrink
- Throttle Shrink's resource usage to allow Expand to start sooner
---
# Conclusion
Our **framework-first approach** combines:
- Precise quantization formats
- Kernel fusion
- SM-level concurrent scheduling
- CPU–GPU execution overlap
This ensures **LoRA serving at enterprise scale** without sacrificing accuracy.
**Next steps:** Explore megakernels, more intelligent scheduling.
---
**Want to try it?**
Run your own LLM inference workloads on [Databricks Model Serving](https://docs.databricks.com/aws/en/machine-learning/model-serving/).
**For AI creators**: Platforms like [AiToEarn](https://aitoearn.ai/) combine high-performance inference with **multi-platform publishing & monetization**, empowering teams and individuals to extend both **technical performance** and **creative reach**.
---
# Understanding the Fundamentals of Neural Networks
Neural networks are **learning systems** modeled after the human brain, able to recognize patterns through **layered neurons**.
## Basic Structure
- **Input Layer** — Accepts raw data
- **Hidden Layers** — Extract & refine features
- **Output Layer** — Produces predictions
Connections have **weights** updated during training.
---
## How They Learn: Backpropagation
1. **Forward Pass** — Predict outputs
2. **Loss Calculation** — Compare to truth with a loss function
3. **Backward Pass** — Update weights using gradients (e.g., SGD)
---
## Common Activation Functions
- Sigmoid
- Tanh
- ReLU
- Leaky ReLU
---
## Applications
- Image & speech recognition
- NLP
- Recommendations
- Autonomous driving
---
## Challenges
- Overfitting
- Large data requirements
- High compute cost
---
**Distribution Tip:** AI educators & creators can **amplify reach** using platforms like [AiToEarn](https://aitoearn.ai/) to **publish neural network content** across Douyin, YouTube, LinkedIn, and more, while tracking [AI model rankings](https://rank.aitoearn.ai).
---
## Final Thought
Neural networks are central to modern AI. Mastering their principles enables innovations across industries, and coupling them with **optimized inference** and **global content deployment** can multiply both technical and creative impact.