# Disaggregated Schedule Fabric (DSF) — Meta’s Next-Generation AI Network Fabric
**Disaggregated Schedule Fabric (DSF)** is Meta’s advanced network fabric technology for AI training, designed to overcome the constraints of traditional Clos-based architectures. It enables **scalable, low-latency, lossless AI networks** by disaggregating hardware components and optimizing traffic management for large GPU clusters.
This document outlines:
- **Challenges** in traditional IP fabrics for AI workloads
- **Innovations** in DSF design
- **Scalable deployment models** from single zones to mega clusters
- **Future directions** including new interconnect technologies
---
## Why DSF?
The rapid growth of **GenAI applications** demands **high-performance AI networks** that can handle massive AI model training workloads. DSF supports this by:
- Replacing monolithic chassis switches with modular units
- Implementing **VOQ-based architectures**
- Using open standards like [OCP-SAI](https://github.com/opencomputeproject/SAI) and [FBOSS](https://engineering.fb.com/2018/09/04/data-infrastructure/research-in-brief-building-switch-software-at-scale-and-in-the-open/)
- Delivering **better load balancing** and **congestion management** for intra-/inter-cluster traffic
---
## 1. Challenges With Traditional IP Fabrics
AI training jobs using RDMA over UDP exposed **three key issues**:
### 1.1 Elephant Flows
- Long-duration, high-volume traffic congests specific links.
- Causes head-of-line blocking.
### 1.2 Low Entropy
- Few IP flows in collective GPU operations.
- Inefficient hashing → hotspot congestion.
### 1.3 Suboptimal Fabric Utilization
- Uneven bandwidth usage across links.
- Forces **overprovisioning** to maintain performance.
---
## 2. Attempted Solutions & Limitations
1. **BGP-Based Pinning**
- Pins traffic to specific uplinks.
- Improves low entropy scenarios.
- Breaks down in failure cases → relies on ECMP fallback.
2. **Load-Aware ECMP**
- Tries to balance fat flows.
- Requires complex tuning.
- Introduces **out-of-order packets** — problematic for RDMA.
3. **Centralized Traffic-Engineering**
- Pre-computes flow patterns per model.
- Scales poorly with network growth.
- Slow reaction to failures.
---
## 3. DSF Overview
### 3.1 Core Idea
Separates **Ethernet domain** from **Fabric domain**:
- **Ethernet domain** — normal server networking
- **Fabric domain** — packet cell spraying and hardware reassembly
### 3.2 Components
- **Interface Nodes (INs)** = Rack Disaggregated Switches (RDSWs)
- **Fabric Nodes (FNs)** = Fabric Disaggregated Switches (FDSWs)
Together, they form a **virtual chassis** that appears as a single switch to the outside network.
---
## 4. Traffic Management
- **Packet spraying** across all paths
- **Credit-based congestion control**
- **VOQ scheduling** for lossless delivery
- **In-order delivery** guaranteed within the fabric
---
## 5. DSF Deployment Models
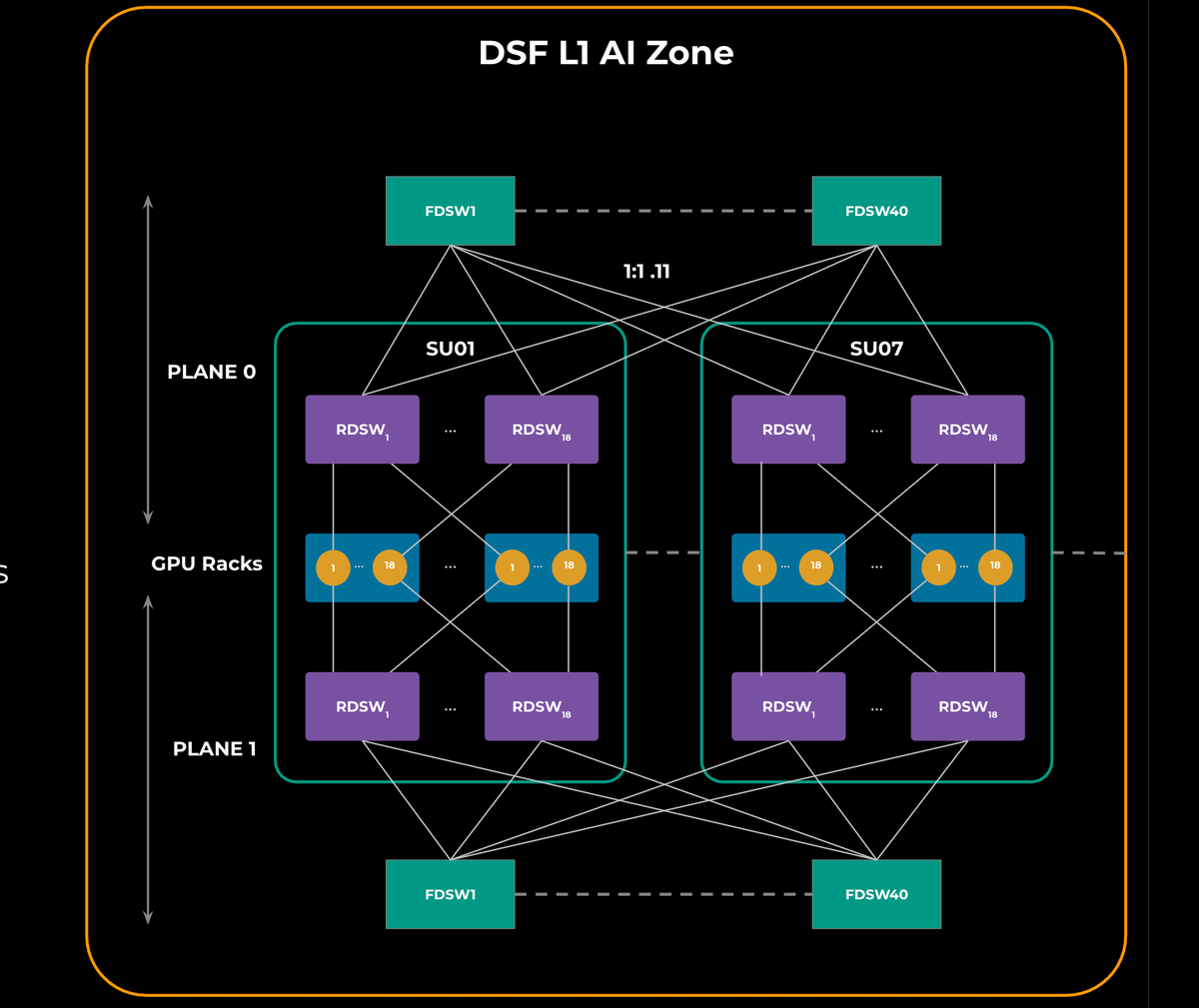
### 5.1 Single AI Zone (L1 Zone)
- Multiple scaling units (GPU racks + RDSWs)
- RDSWs connected to FDSWs
- Two identical network planes for fault tolerance
**Figure 1:**
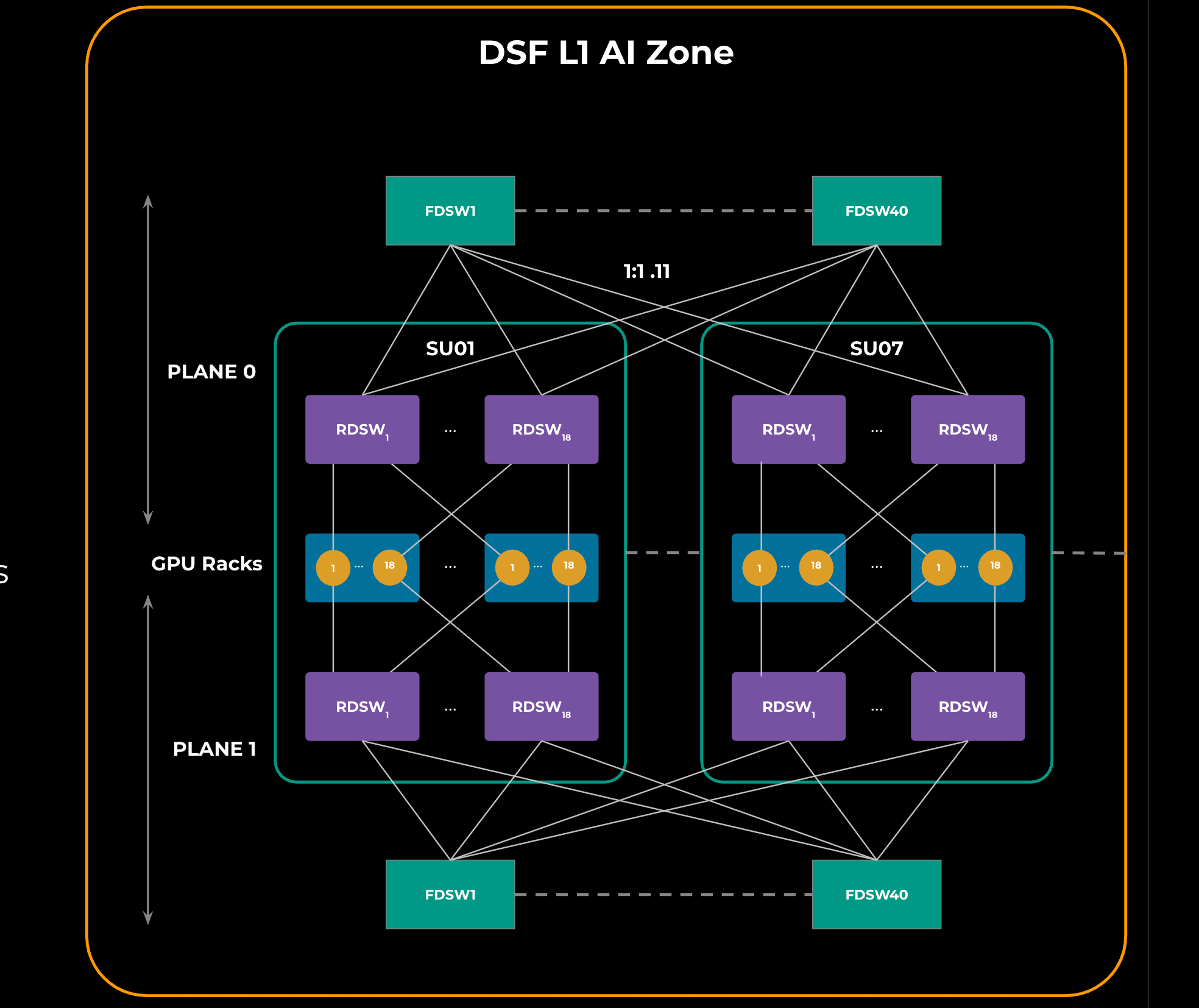
---
### 5.2 Dual-Stage Fabric (L2 Zone)
- 4× L1 zones interconnected via **Spine DSF Switches (SDSWs)**
- Non-blocking topology for 18,000 GPUs @ 800G
**Figure 2:**
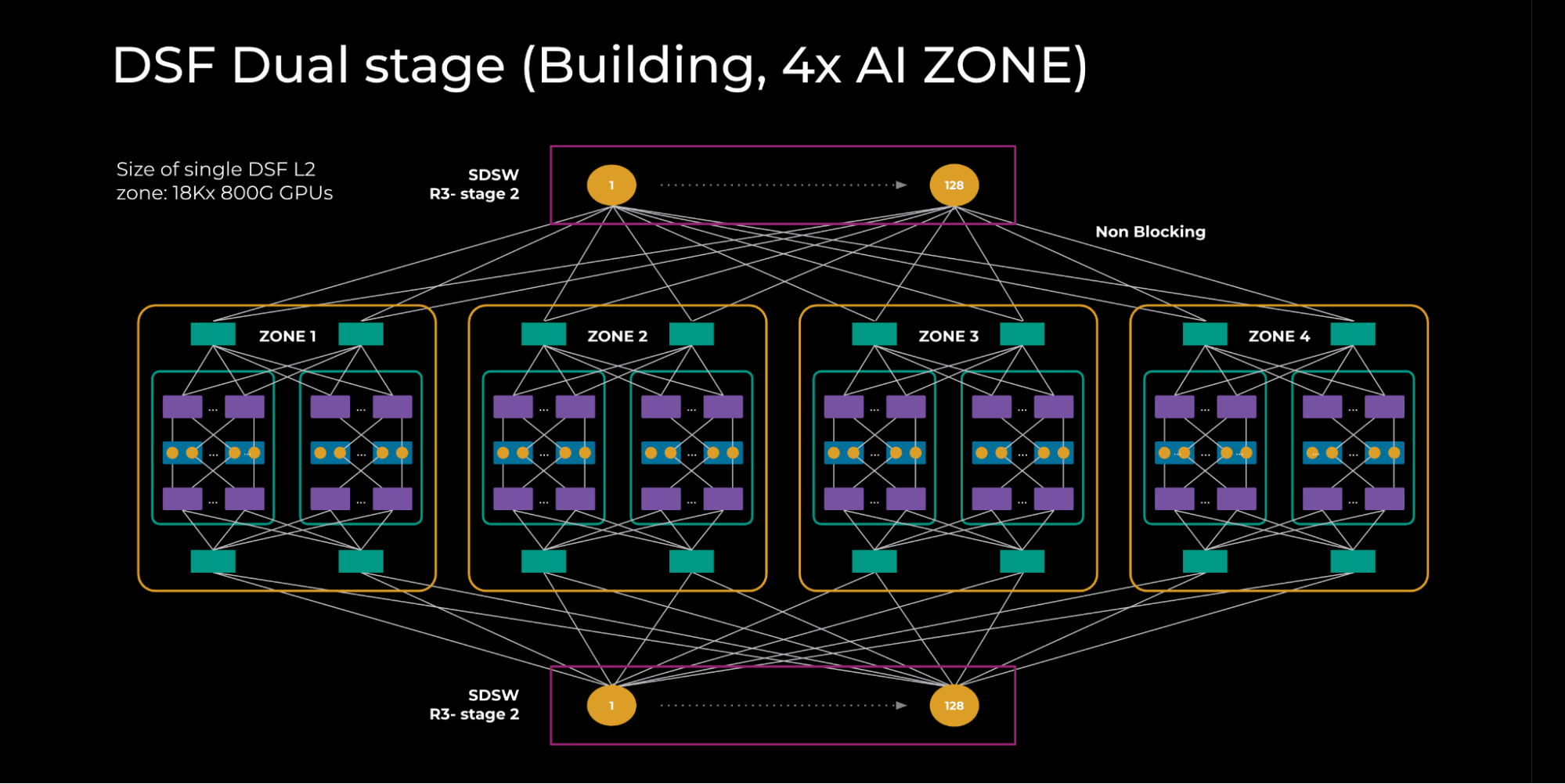
---
### 5.3 DSF Region
- 5× L2 zones interconnected via **L3 super-spine**
- Edge PoD architecture with EDSWs → L3 super-spine links
**Figure 3:**
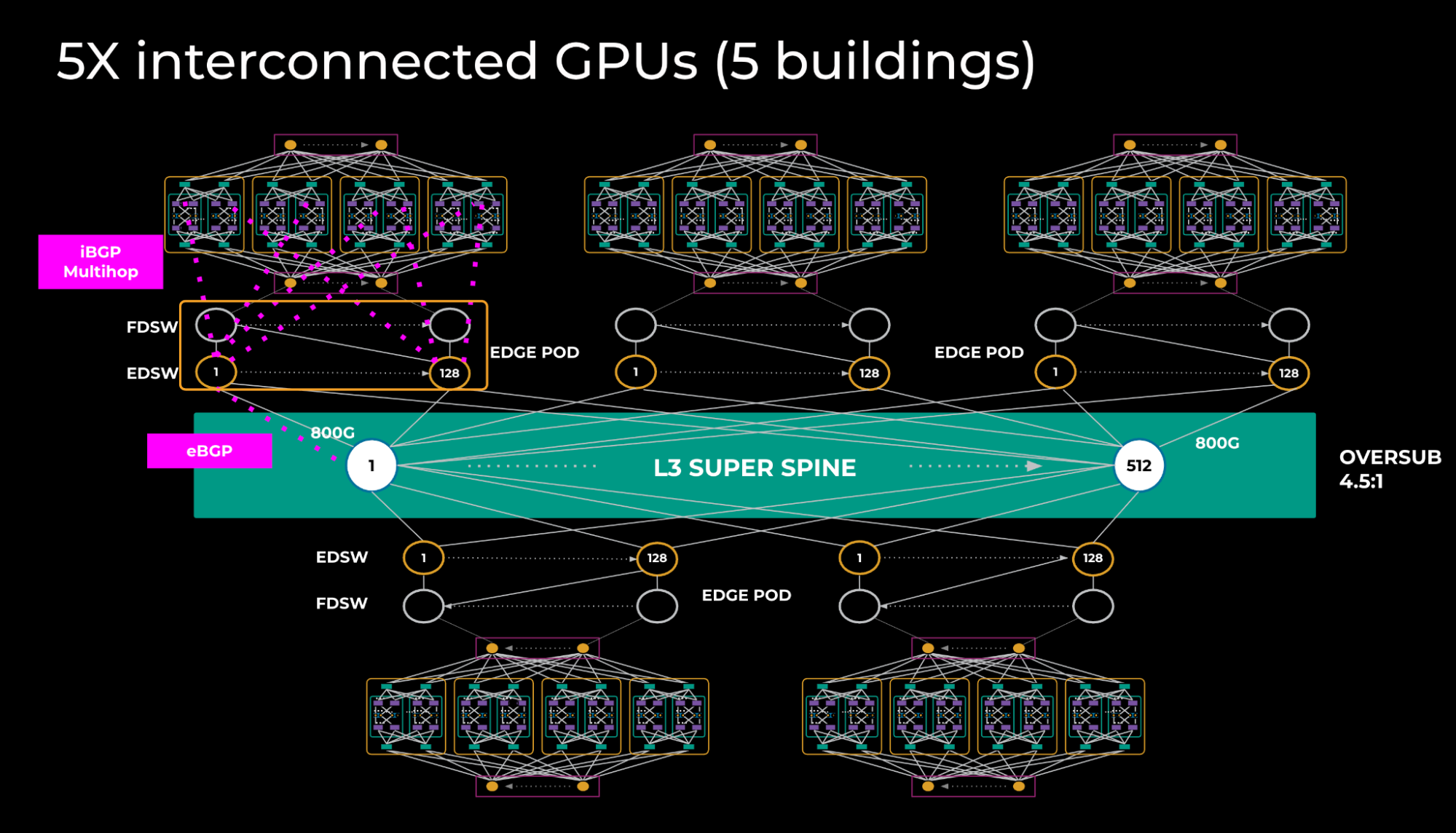
---
## 6. Input Balanced Mode
**Purpose:** Maintain input ≤ output capacity even under remote link failures.
### Failure Handling:
1. **RDSW ↔ FDSW Failure**
2. **FDSW ↔ SDSW Failure**
3. **Combined Failures**
Randomized link selection stops advertising reachability to avoid oversubscription.
---
**Figures 4–17:**
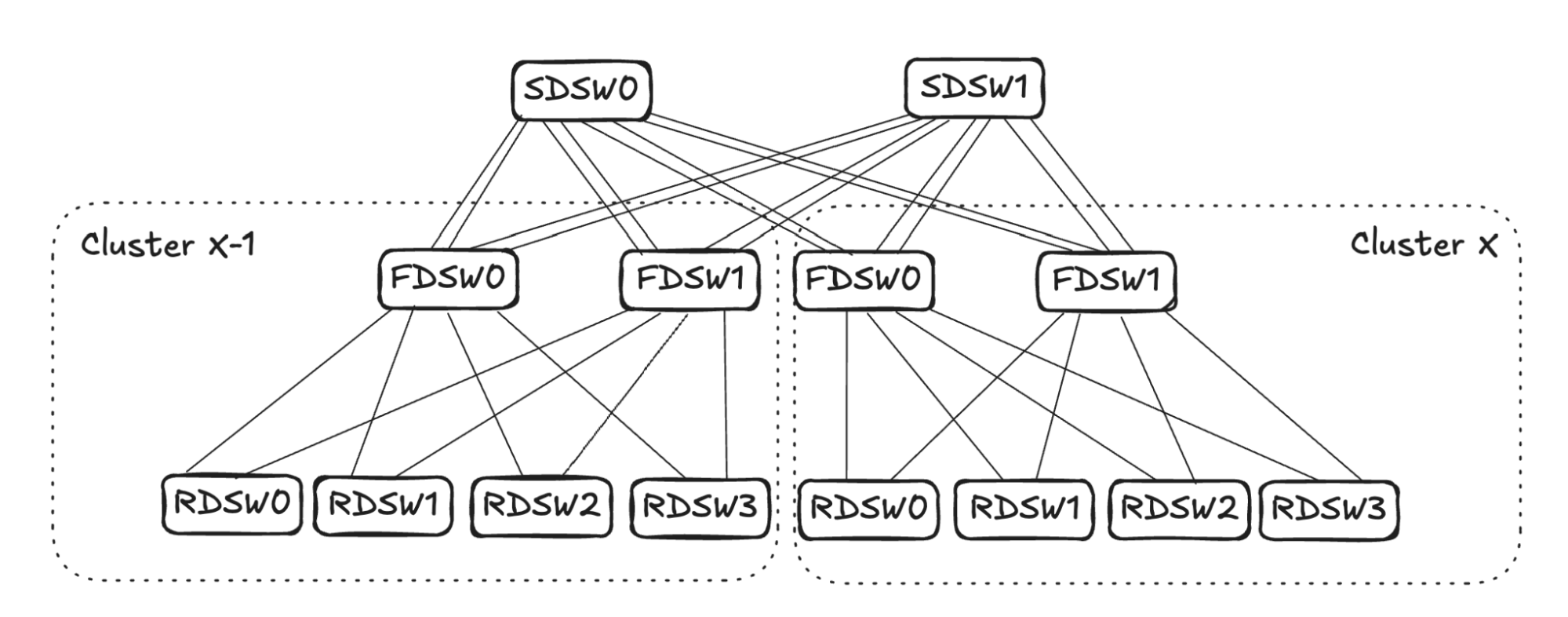
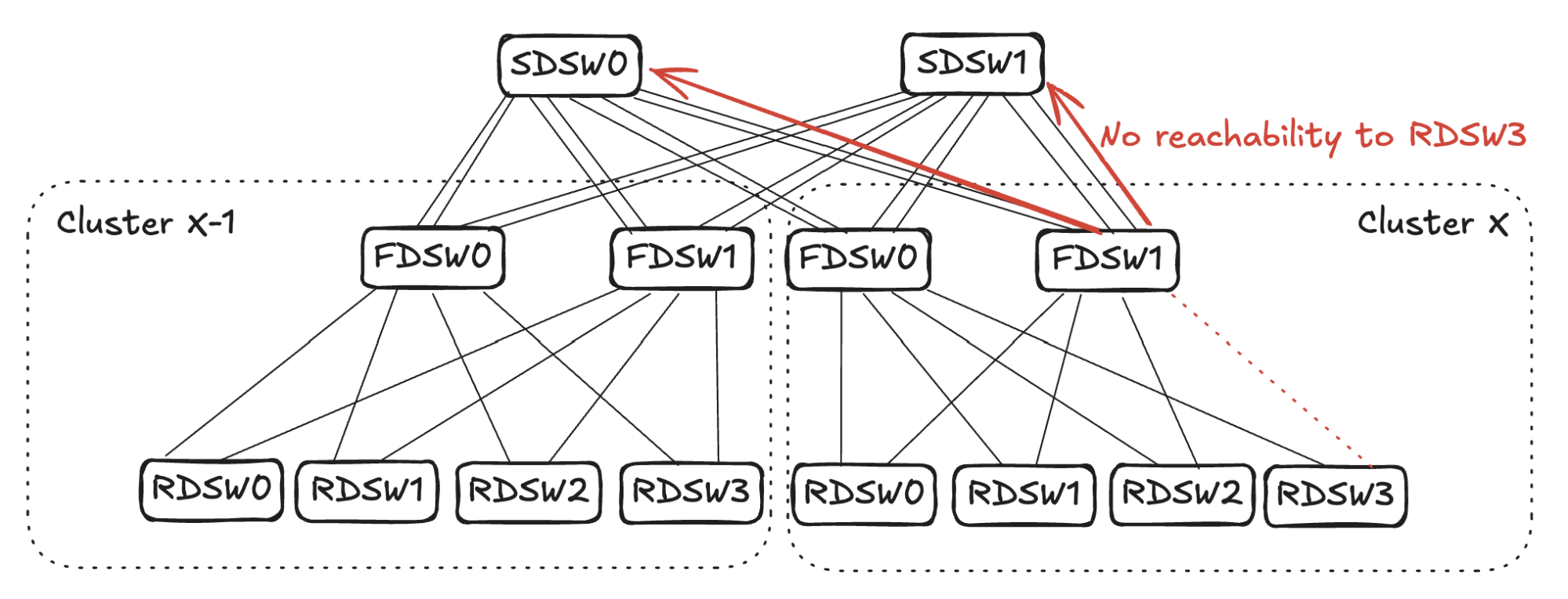
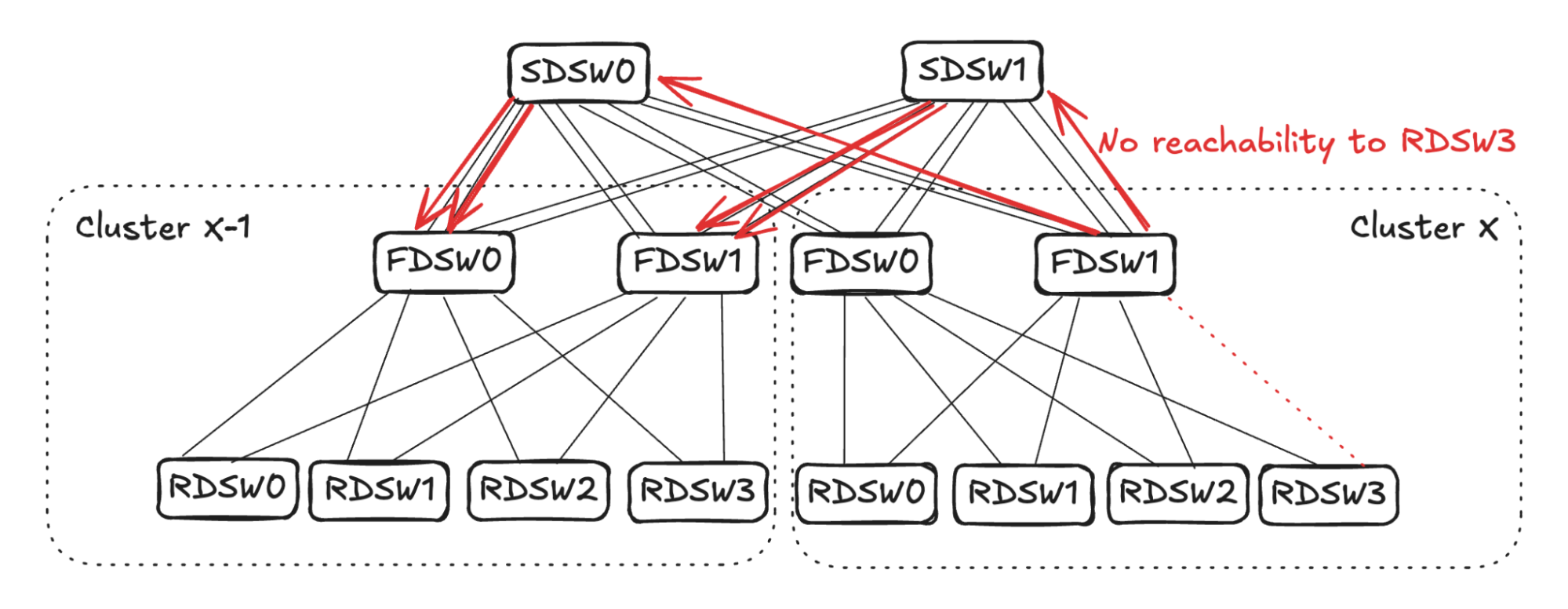
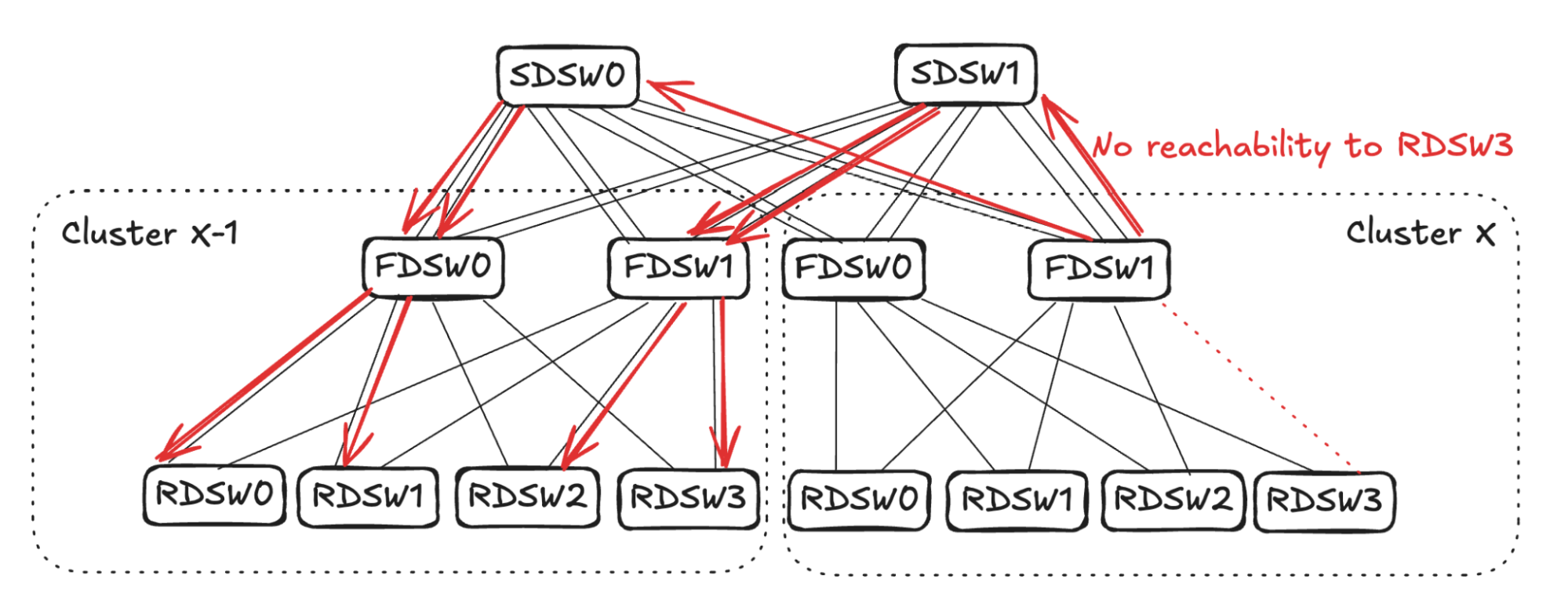
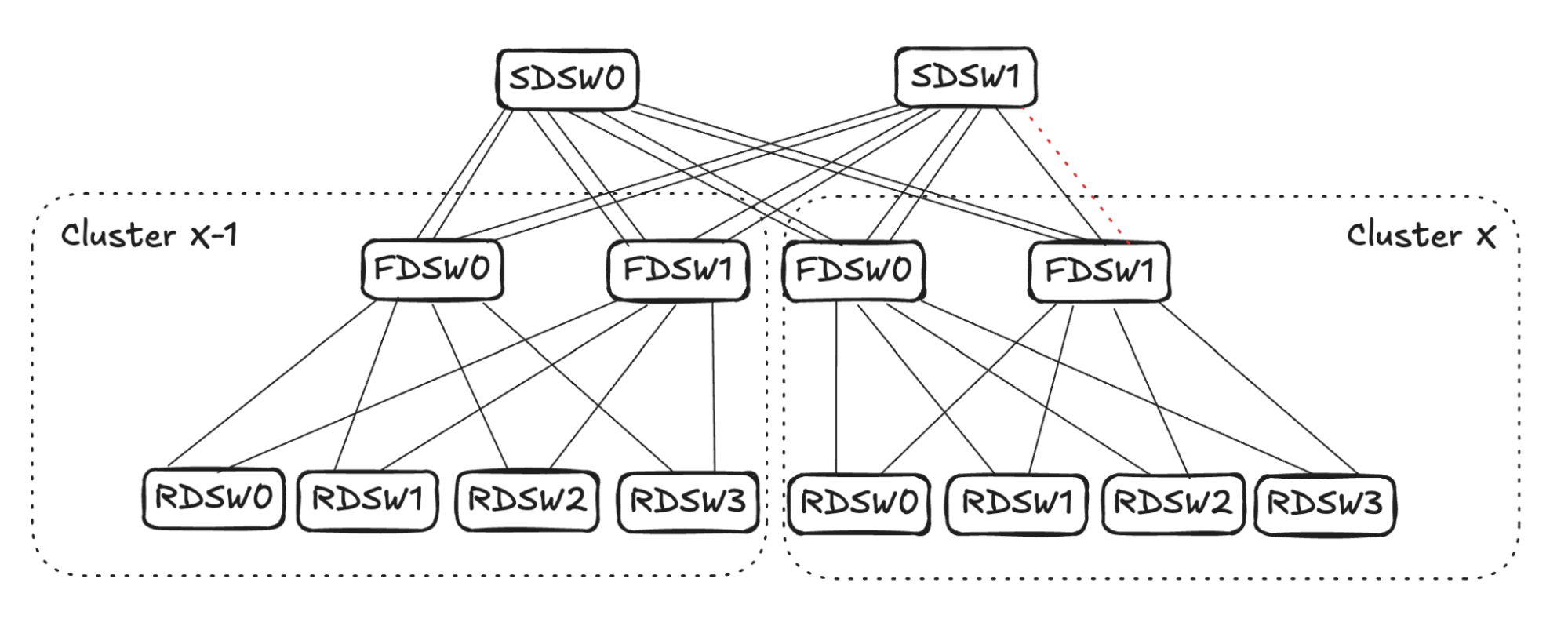
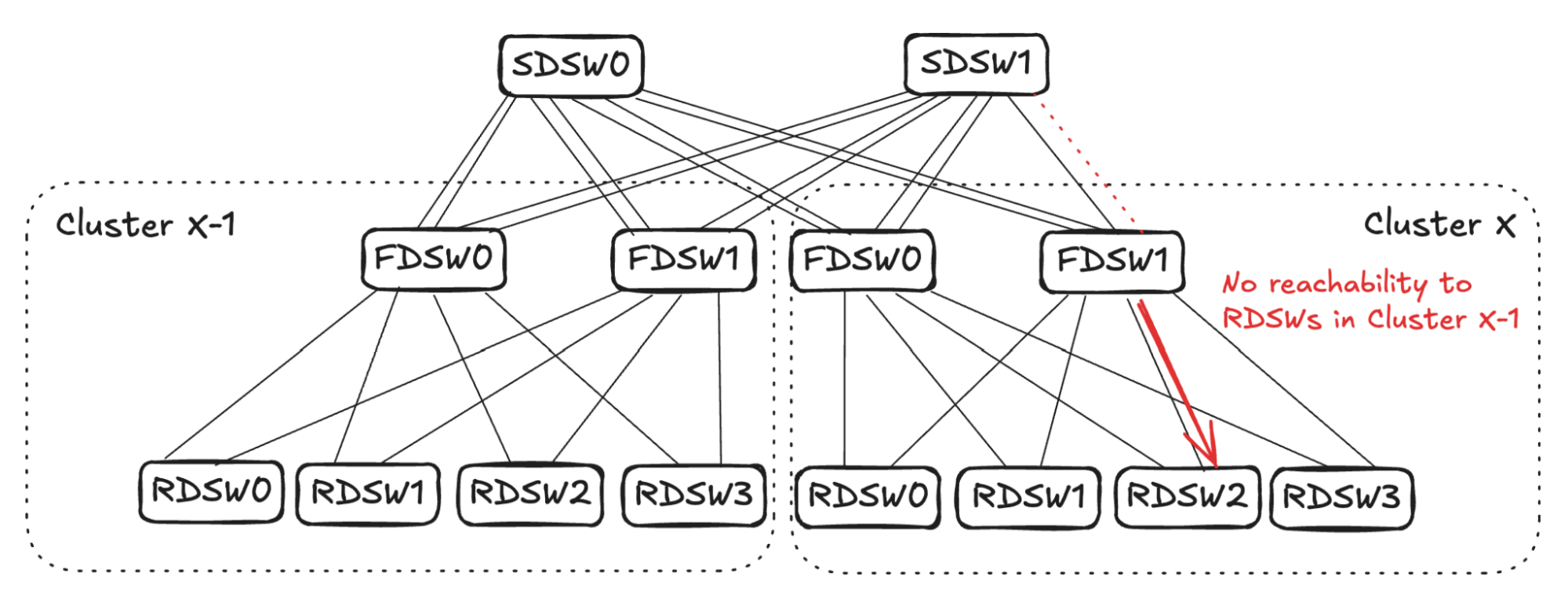
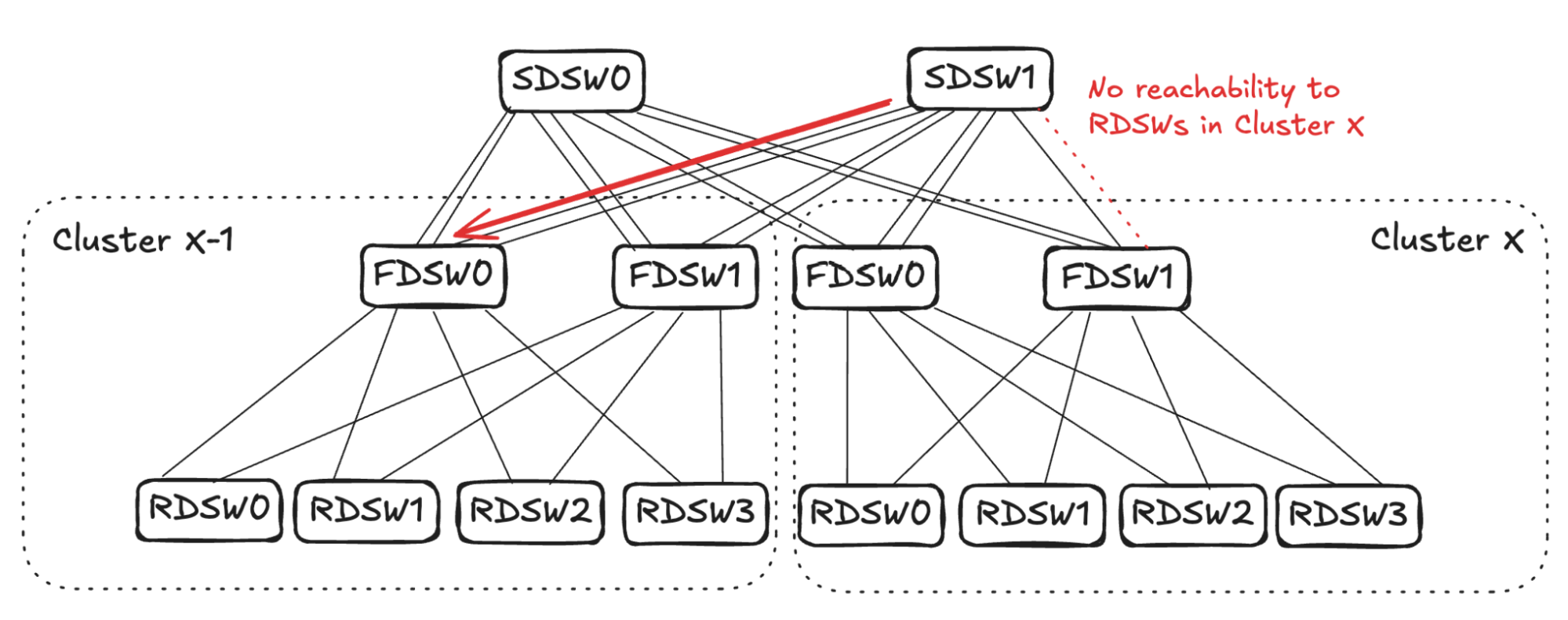
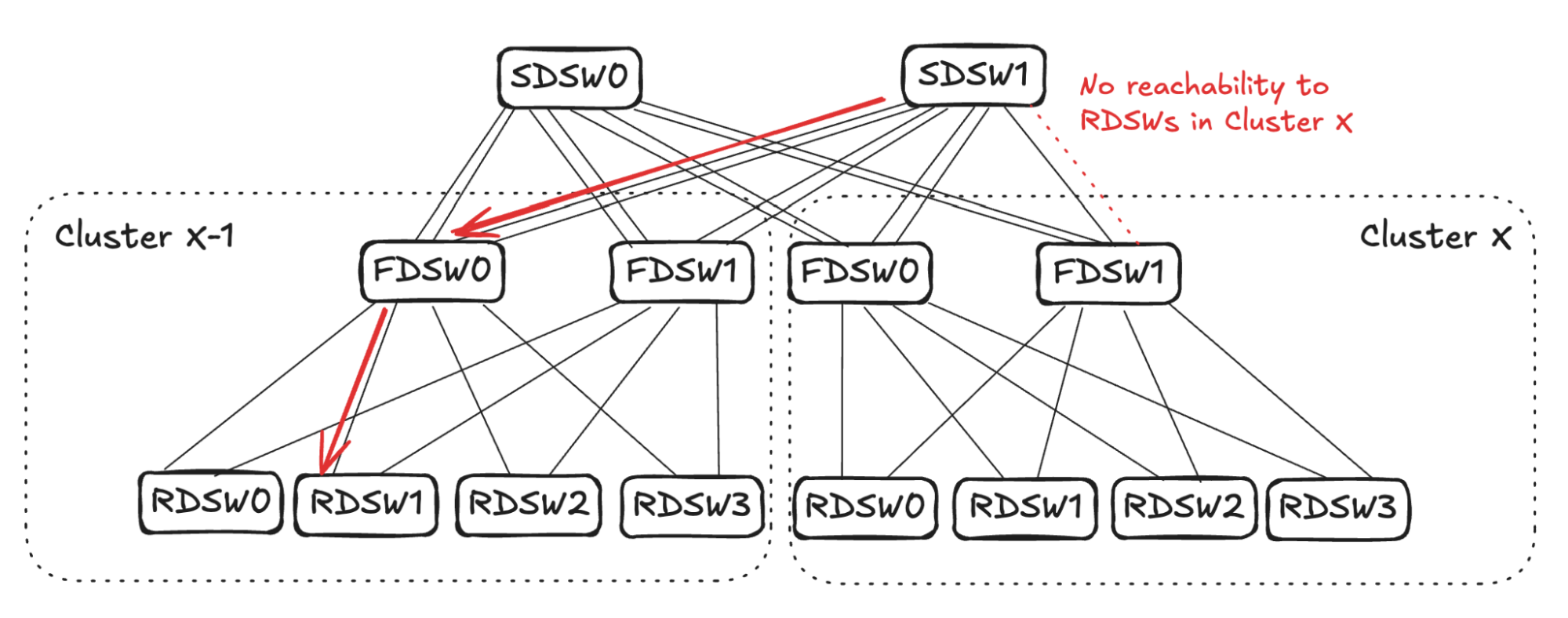
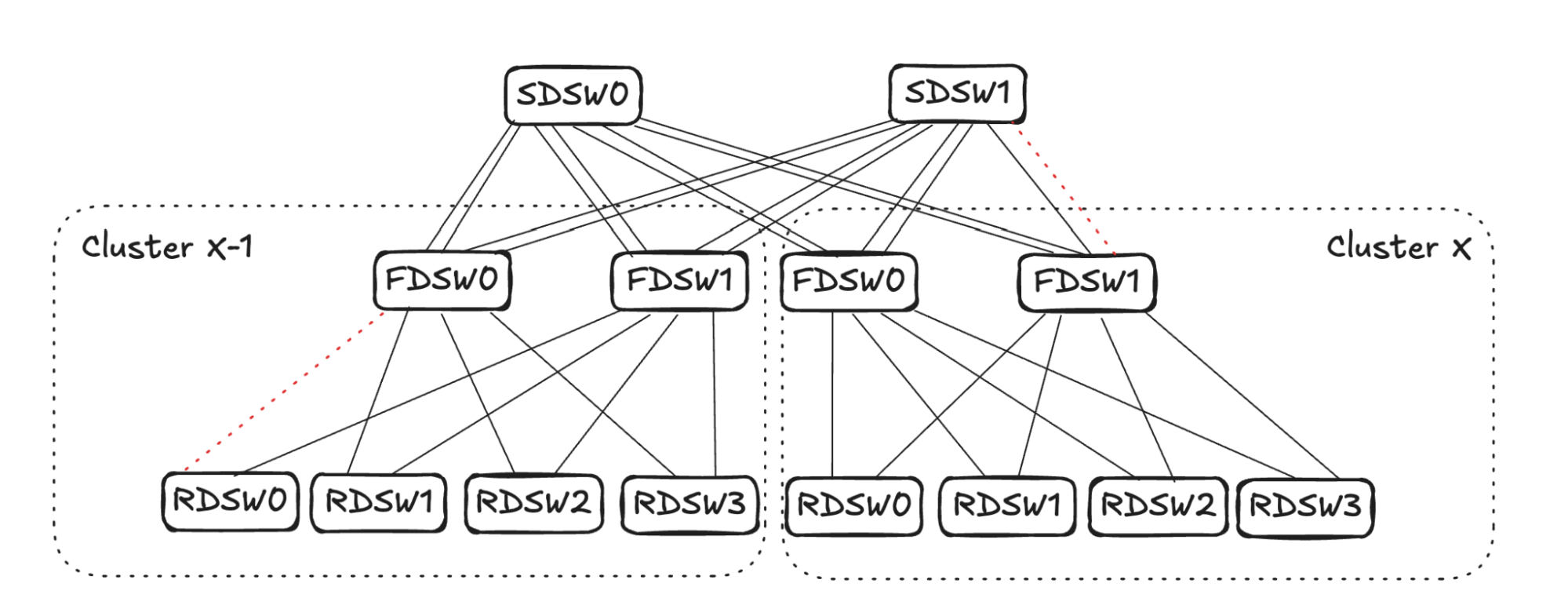
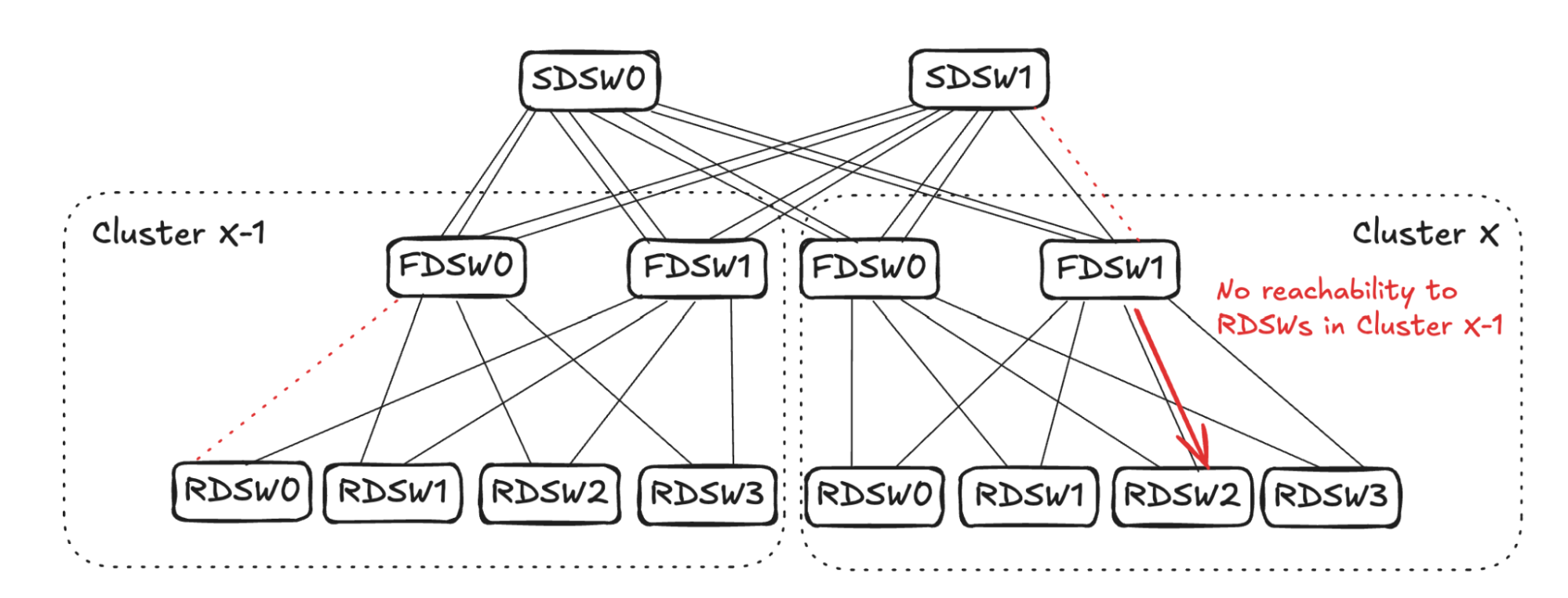
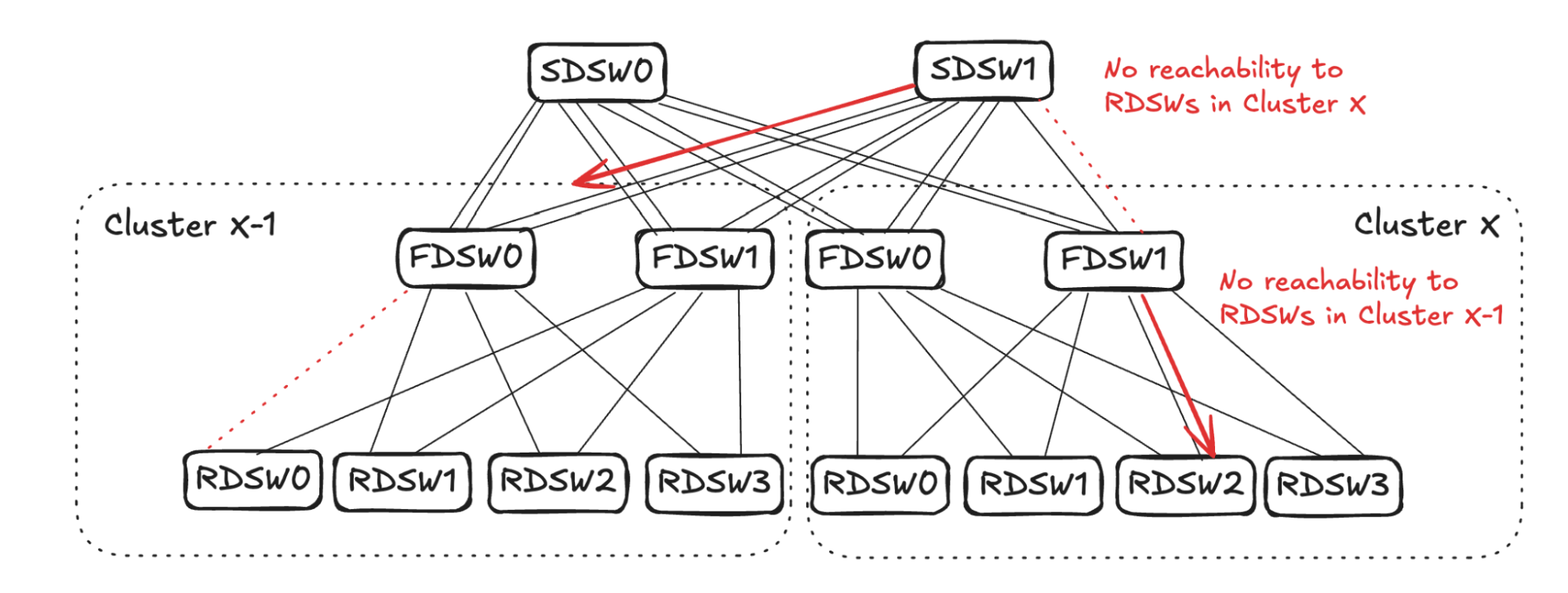
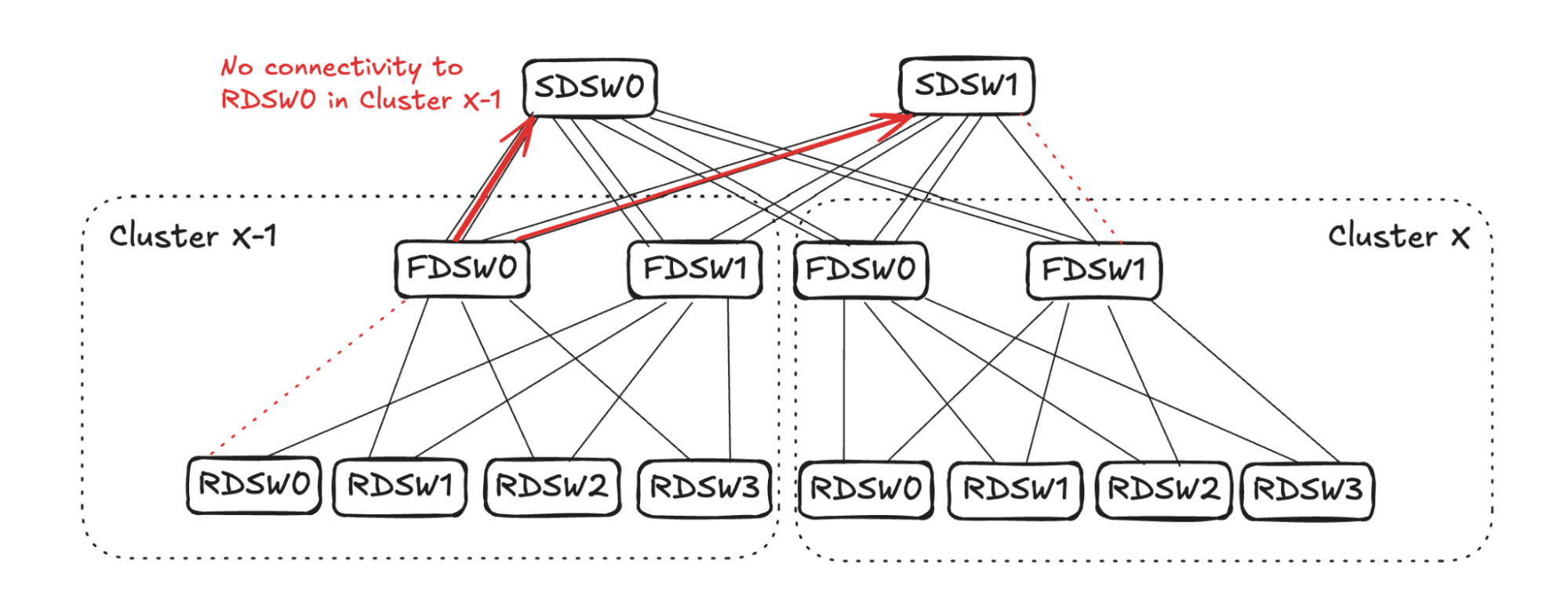
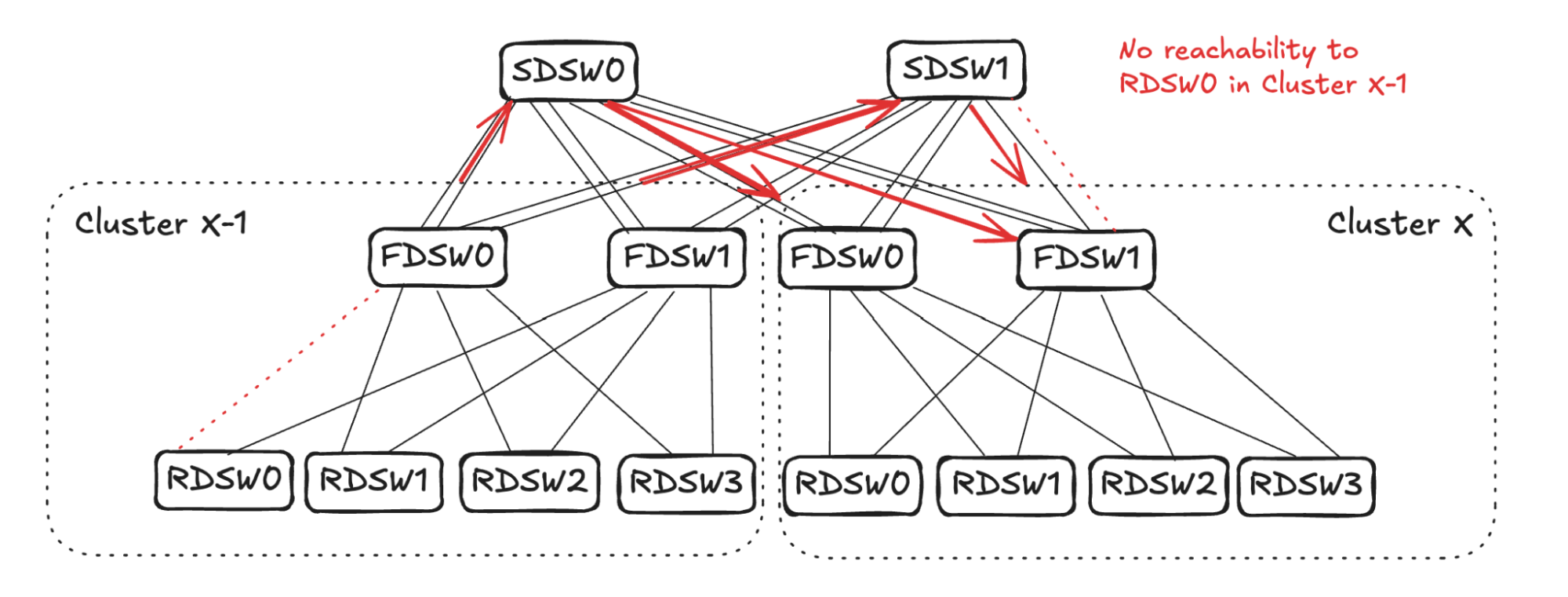
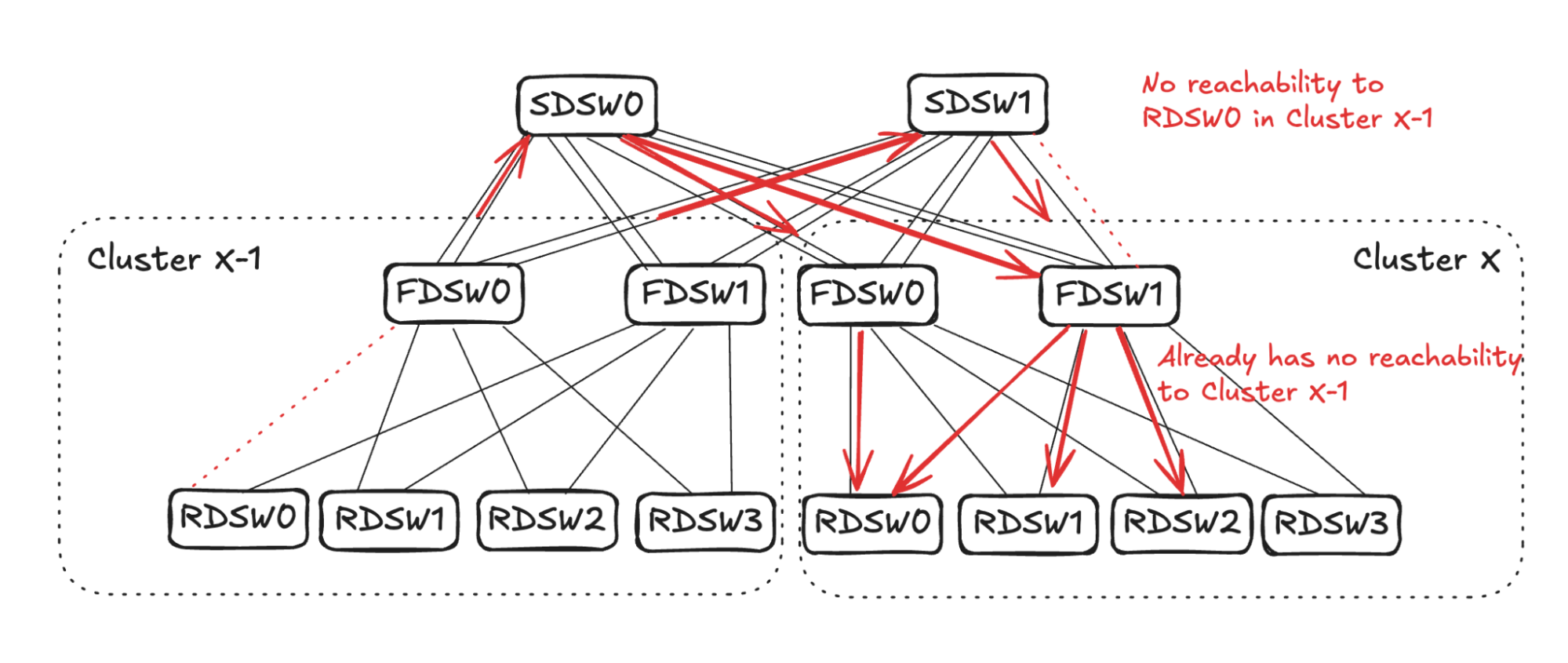
---
## 7. Future Work
- **Multi-region mega clusters**
Cross-region GPU interconnect tens of km apart ([details](https://engineering.fb.com/2025/09/29/data-infrastructure/metas-infrastructure-evolution-and-the-advent-of-ai/)).
- **Hyperports**
Aggregate multiple 800G ports at ASIC level to behave as one physical port.
- **Heterogeneous GPU/NIC support**
Natively handle varied hardware configurations.
---
## 8. Related AI Content Infrastructure
Platforms like [AiToEarn官网](https://aitoearn.ai/) parallel DSF’s scalability in the **AI content monetization** domain:
- **AI generation** across diverse workloads
- **Cross-platform publishing** — Douyin, Kwai, WeChat, Bilibili, Facebook, Instagram, Threads, LinkedIn, YouTube, Pinterest, X (Twitter)
- **Analytics + Model Ranking** ([AI模型排名](https://rank.aitoearn.ai))
- **Open-source** workflows ([AiToEarn文档](https://docs.aitoearn.ai), [GitHub](https://github.com/yikart/AiToEarn))
Just as DSF scales GPU clusters efficiently, AiToEarn scales multi-platform content pipelines globally.
---