# Disaggregated LLM Inference: Breaking the Bottlenecks in AI Infrastructure
Artificial intelligence models are evolving **at an accelerating pace**, yet infrastructure has lagged behind. As large language models (LLMs) grow from simple chatbot tools to enterprise-scale solutions, **traditional monolithic server architectures are becoming a major bottleneck**.
**Disaggregation**—splitting different stages of model processing across specialized hardware—may be the key to unlocking performance and efficiency.


---
## Introduction to Large Language Models
LLMs have transitioned from research projects to **critical business infrastructure**, powering:
- **Customer service chatbots**
- **Enterprise search**
- **Content creation workflows**
Models such as **GPT‑4**, **Claude**, and **Llama**—with billions of parameters—require **specialized compute** and **high throughput pipelines**.
One **central challenge** is the dual structure of inference:
1. **Pre‑fill stage** – Processes the input context.
2. **Decode stage** – Generates output tokens one at a time.
Each stage has **wildly different computational profiles**, making it difficult for a single hardware setup to be optimal.
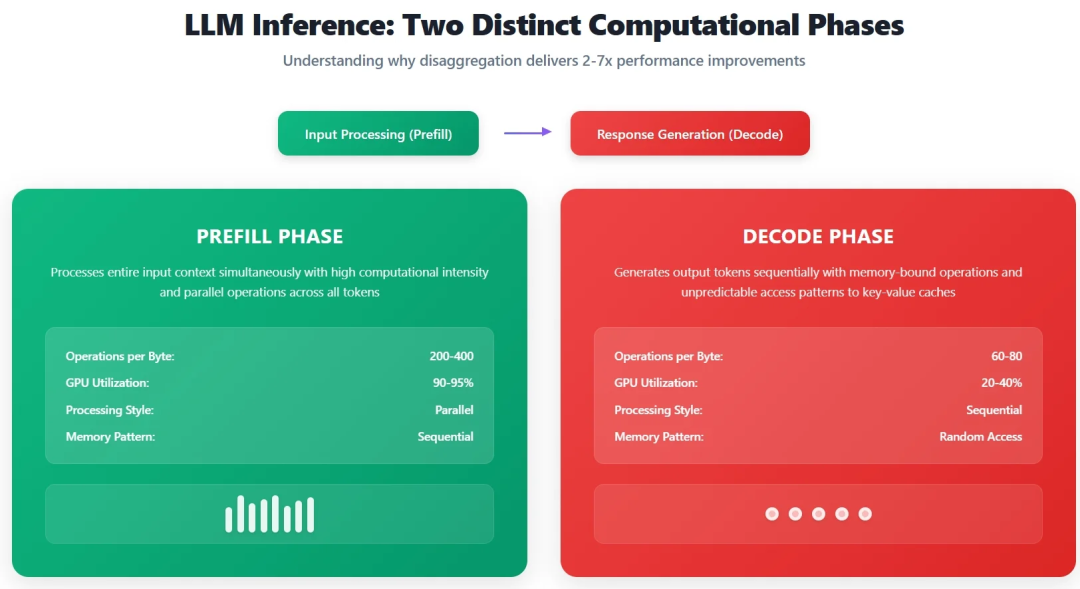
**Figure 1**: Characteristics of Pre‑fill vs. Decode Stages
---
## Pre‑fill vs. Decode Stages
### Pre‑fill
- **200–400 operations per byte of memory access**
- **GPU utilization: 90–95%**
- Ideal for **batch processing** and **compute-heavy hardware**
### Decode
- **60–80 operations per byte**
- **GPU utilization: 20–40%**
- Limited by **memory bandwidth**
- Highly **latency-sensitive**, low batching efficiency
### Example Workload Patterns
- **Summarization** – Prefill dominates (~80–90% time).
- **Interactive chatbots** – Require <200 ms latency.
- **Agentic AI** – Complex contexts (8K–32K+ tokens).
---
## Why a Single Accelerator Falls Short
Modern GPUs are **tuned for specific workloads**, e.g.:
- **NVIDIA H100** – Ideal for compute-heavy pre‑fill (3.35 TB/s bandwidth, triple A100’s FLOPs).
- **NVIDIA A100** – Sometimes better for memory‑bound decode operations.
### Hardware Trade‑offs
- Prefill needs **high compute density** + **large on‑chip memory**.
- Decode needs **high bandwidth** + **low-latency memory access**.
**Performance gap:** Decoding achieves ~⅓ the utilization compared to prefill.
---
## The Rise of Disaggregated LLM Inference
In **June 2023**, the **vLLM framework** introduced a **production-ready decoupled service architecture** with:
- **PagedAttention** – Efficient KV cache management.
- **Continuous batching** – Boosts throughput.
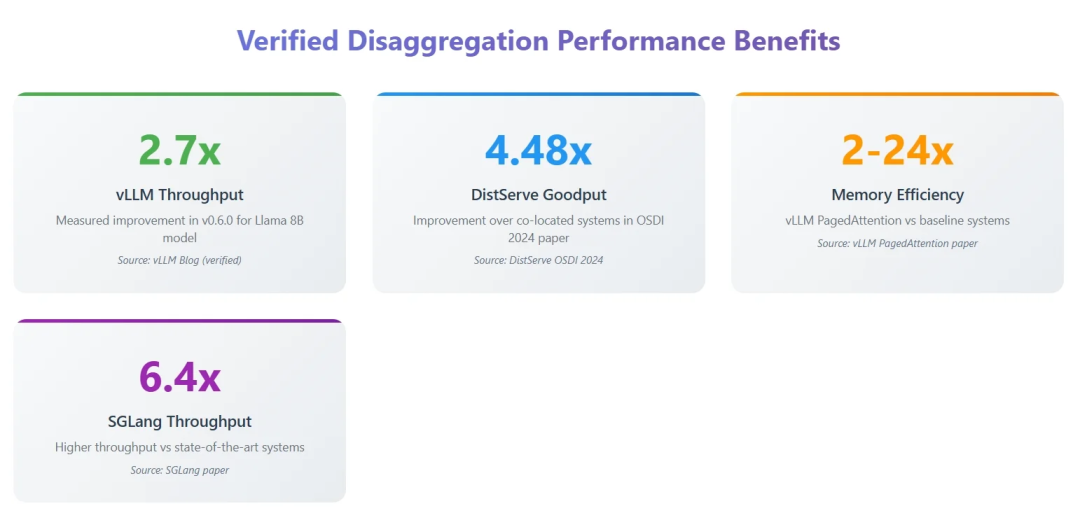
**Figure 2**: Benefits of Decoupling
**Performance Example:**
vLLM 0.6.0 → Llama‑8B throughput up **2.7×**, latency cut by **80%**.
Other notable evolutions:
- **SGLang** – RadixAttention + structured generation, **6.4× throughput** boost.
- **DistServe (OSDI 2024)** – **4.48× throughput** over co‑located deployment, **20× latency variance reduction**.
---
## Economic Impact
Monolithic setups often **over-provision expensive GPUs** for decoding, wasting resources.
Benefits of decoupled architectures:
- **15%–40% total cost reduction**
- **40%–60% GPU utilization improvement**
- **50% lower power consumption**
- **Up to 4× lower server configuration costs**

**Figure 3**: LLM Workload Patterns
---
## Implementation Strategy
### Blueprint: Decoupled Service Pipeline
**Prefill cluster**
- High FLOPs GPUs (e.g., H100)
- Optimized for large prompt batching
**Decode cluster**
- High bandwidth GPUs (e.g., A100)
- Optimized for low-latency token generation
**Networking**
- InfiniBand / NVLink for KV cache transfer
- Central scheduler routes workload based on profile
---
### Technical Steps
1. **Workload Analysis**
Identify pre‑fill vs. decode‑dominant applications.
2. **Resource Partitioning**
Map each workload stage to optimal hardware.
3. **Framework Selection**
- vLLM – General deployments, broad model support.
- SGLang – Structured generation, multimodal.
- TensorRT‑LLM – Enterprise-grade control.
4. **Deployment Strategy**
Parallel rollout with A/B testing.
---
## Real‑World Cases
### Splitwise (Microsoft Research)
- **1.4× throughput** improvement, **20% cost reduction**.
- Azure DGX clusters, InfiniBand.
### SGLang vs. DeepSeek
- Large-scale Atlas Cloud deployment: **52.3k input tok/sec**, **22.3k output tok/sec**.
- **5× throughput boost** over baseline tensor-parallel.
### DistServe (OSDI 2024)
- **7.4× concurrency** gain, **12.6× SLA compliance**.
- Tested with NVLink / PCIe 5.0 interconnects.
---
## Best Practices
- **Monitor**: GPU utilization, latency, cache hit rates.
- **Isolate components**: Resilient microservice deployment.
- **Secure communication**: End-to-end encryption, service mesh.
---
## Security & Reliability
### Security
- Strong encryption between clusters.
- Service mesh for secure service-to-service calls.
- Strict roles & access control.
### Reliability
- Redundant clusters & load balancing.
- Circuit breakers to prevent cascading failures.
- Distributed state management with strong consistency.
---
## Future Hardware & Software Evolution
- **Specialized chips** for each stage with co‑design between memory and compute.
- **Chiplet architectures** for flexible allocation.
- **Near‑memory computing** to reduce data movement.
- Industry move towards **API standardization** and **model format portability**.
---
## Bridging Infrastructure & Monetization
Platforms like [AiToEarn官网](https://aitoearn.ai/) enable:
- AI generation + multi-platform publishing
- Analytics + ranking ([AI模型排名](https://rank.aitoearn.ai))
- Publishing to Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter.
This matches the **distributed orchestration principles** in decoupled LLM inference—maximizing efficiency and revenue simultaneously.
---
### Summary
**Decoupled architectures**:
- Optimize prefill & decode separately
- Improve performance, costs, and scalability
- Transitioned from research to production use
**Next step**:
Standardization, specialized hardware design, and integration with content monetization ecosystems will define the future AI operational landscape.
---
**Original article link:**
[https://www.infoq.com/articles/llms-evolution-ai-infrastructure/](https://www.infoq.com/articles/llms-evolution-ai-infrastructure/)
---
**Recommended Reading**
- [Altman’s Ambition Shows Cracks: Three Bottlenecks](https://mp.weixin.qq.com/s?__biz=MjM5MDE0Mjc4MA==&mid=2651258056&idx=1&sn=4e637c0bfe91e53d76f69079b1cc1321&scene=21#wechat_redirect)
- [Moats in the AI Era: Cursor vs. DeepSeek](https://mp.weixin.qq.com/s?__biz=MjM5MDE0Mjc4MA==&mid=2651258045&idx=1&sn=f12c3e858a5bba368f83cf46cb9817db&scene=21#wechat_redirect)
- [Small Team Builds Hit App Under Pressure](https://mp.weixin.qq.com/s?__biz=MjM5MDE0Mjc4MA==&mid=2651257946&idx=1&sn=959fe8ddb257f00584df3132cd260e9c&scene=21#wechat_redirect)
- [Korean Data Center Burns 22 Hours](https://mp.weixin.qq.com/s?__biz=MjM5MDE0Mjc4MA==&mid=2651257900&idx=1&sn=2301e50b20063fd0e1fab415cfa63bce&scene=21#wechat_redirect)
[Read Original](https://www.infoq.cn/news/ViFEG6YOJR5WY2OTkux9)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=5c8bda3f&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMjM5MDE0Mjc4MA%3D%3D%26mid%3D2651258555%26idx%3D2%26sn%3De5ed740ad51cc6ef0c93ba95054b44ca)