DeepResearch Architecture and Practice Based on Spring AI Alibaba
DeepResearch System Documentation
1. Introduction & Overview
DeepResearch is a Java-based intelligent research automation system built with Spring AI and Alibaba Graph.
It enables an end-to-end workflow — from information gathering to analysis, and finally, structured report generation.
Key Capabilities
- Reasoning Chain:
- Automatically constructs a logical analysis process from collected materials to conclusions using multi-round information gathering.
- Java Technology Stack:
- Built for reliable, long-term stable operation.
- Spring Ecosystem Integration:
- Works seamlessly with Spring Boot, Spring Cloud, and other Spring components for easier development and integration.
- Observability:
- Langfuse integration enables visibility into Spring AI Alibaba Graph call chains, simplifying debugging and operations.
- Traceable Output:
- Every search result is linked to its original source for verification.
---
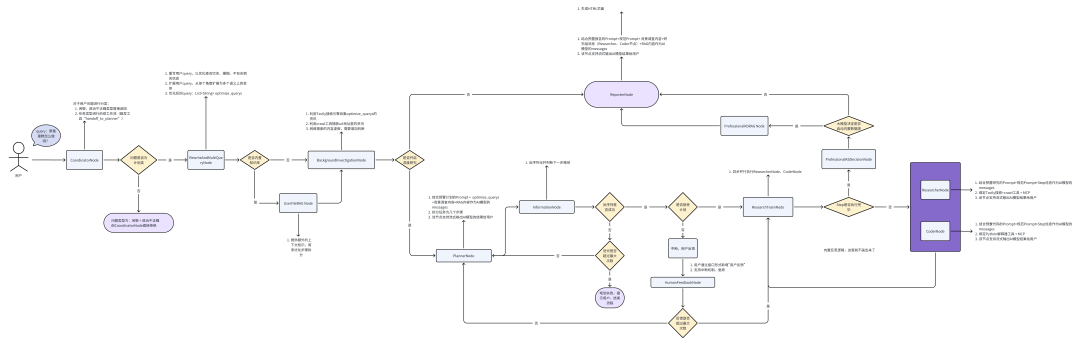
2. System Architecture
System Node Diagram

> Reply with “System Node Diagram” in our public account backend to view the high-resolution version.
---
3. Core Features & Node Implementation
Node Functions
This architecture consists of 11 primary nodes:
- CoordinatorNode – Coordinator
- Determines the task type from user input and decides execution flow.
- Terminates early if irrelevant.
- RewriteAndMultiQueryNode – Query Optimizer
- Refines user queries and creates multiple semantic variations.
- BackgroundInvestigationNode – Background Research
- Uses search engines to collect task-specific information (academic, travel, encyclopedic, data analysis, general research).
- PlannerNode – Task Planner
- Breaks tasks down into discrete, executable steps.
- InformationNode – Content Sufficiency Check
- Validates whether collected content is adequate.
- HumanFeedbackNode – Feedback Loop
- Allows user feedback to refine outputs.
- ResearchTeamNode – Research Execution Coordinator
- Runs `ReseacherNode` and `CoderNode` in parallel, awaits both results.
- ReseacherNode – Data Acquisition
- Searches content based on theme type.
- CoderNode – Data Processing
- Executes Python tools for data analysis.
- RagNode – Retrieval-Augmented Generation (RAG)
- Searches user-uploaded files in response to queries.
- ReporterNode – Output Integrator
- Aggregates all outputs into the final report.
---
Supporting Technologies
- Multi-model configuration
- Prompt engineering
- Multi-Agent collaboration
- LLM reflection mechanism
- Task planning
- Graph workflow — parallelism, streaming, human feedback
- Tool integration & custom MCP
- Specialized RAG knowledge base
- Traceable chain observability
- Online visualized reports
---
4. Retrieval-Augmented Generation (RAG)
4.1 Concept
The `spring-ai-alibaba-deepresearch` RAG module retrieves and fuses content from multiple heterogeneous sources using a strategy pattern.
Results are intelligently merged and re-ranked before being passed to the LLM for context-aware answers.
4.2 RAG Stages
Stage 1 – Document Processing & Indexing (Ingestion)
Workflow:
- Load documents from varied sources.
- Split into smaller text chunks.
- Transform into vectors using an embedding model.
- Store vectors with metadata in a vector store.
Stage 2 – Retrieval & Generation (Query Time)
Workflow:
- Convert user query into a vector.
- Perform similarity search in the vector store.
- Retrieve relevant chunks.
- Combine chunks with the query in a prompt for the LLM.
- Generate a grounded, factual answer.
---
4.3 Features
- Multi-source retrieval: APIs, Elasticsearch, local files.
- Hybrid strategies: Keywords + vectors.
- Pluggable strategy design: Easy extension of retrieval/fusion logic.
- Intelligent fusion: RRF algorithm improves relevance of final documents.
---
4.4 Configuration Options
- Enable/Disable: `spring.ai.alibaba.deepresearch.rag.enabled`
- Vector Store Types:
- `simple` – Local disk store.
- `elasticsearch` – ES-based vector store.
- Data Ingestion:
- Load at startup
- Scheduled directory scanning
- Manual file upload API
- API integration with third-party KBs
- Pipeline Processing:
- `query-expansion-enabled` – Multiple related queries.
- `query-translation-enabled` – Language translation.
---
5. Implementation Details
5.1 Core Interfaces
- VectorStore
- RetrievalAugmentationAdvisor
5.2 Workflow
- RagDataAutoConfiguration – triggers ingestion
- VectorStoreDataIngestionService – reading, splitting, storing
- RagVectorStoreConfiguration – store type selection
- RagAdvisorConfiguration – pipeline setup
---
Example Flow:
- `RagNode` retrieves query from state.
- Advises vector store retrieval.
- Enhances LLM’s answer with relevant docs.
- Injects result back into workflow state.
---
6. Report Management
6.1 Core Services
- ReportService – lifecycle management
- ExportService – format conversion
6.2 Storage
- Redis storage (`ReportRedisService`) for production.
- In-memory storage (`ReportMemoryService`) for dev/testing.
6.3 Export Formats
- Markdown (.md)
- PDF – HTML rendering with CJK font support
---
6.4 API Endpoints
- GET `/api/reports/{threadId}` – retrieve report
- POST `/api/reports/export` – export task
- GET `/api/reports/download/{threadId}` – file download
- GET `/api/reports/interactive-html/{threadId}` – LLM-generated HTML
---
7. Deployment
Method 1 – Docker (All-in-One)
cd spring-ai-alibaba-deepresearch
docker build -t spring-ai-deepresearch .
docker run --env-file ./dockerConfig/.env -p 8080:80 --name deepresearch -d spring-ai-deepresearch`.env` example:
AI_DASHSCOPE_API_KEY=
AI_DEEPRESEARCH_EXPORT_PATH=
TAVILY_API_KEY=
YOUR_BASE64_ENCODED_CREDENTIALS=Access: http://localhost:8081/
---
Method 2 – Manual Start
Requirements:
- Docker
- JDK 17+
- Node.js 16+
Middleware:
docker compose -f docker-compose-middleware.yml up -dIncludes Redis & Elasticsearch.
Backend:
mvn clean install -DskipTestsConfigure environment variables in IDE → Start backend.
Frontend:
pnpm install
pnpm run devProxy config via `vite.config.ts` if using relative path.
Access: http://localhost:5173/ui
---
8. Community
GitHub: https://github.com/alibaba/spring-ai-alibaba
Contributions: PRs / Issues / Requests welcome.
Contributors:
---
💡 Tip:
Consider AiToEarn — an open-source platform for AI content monetization, allowing you to:
- Publish across Douyin, Bilibili, YouTube, LinkedIn, Twitter, and more.
- Integrate with DeepResearch output for cross-platform sharing.
- Track analytics and optimize AI-generated content.
Docs: AiToEarn博客 | Repo: GitHub
---
Would you like me to prepare a concise quick-start RAG + AiToEarn integration guide so developers can directly deploy both for research & monetization workflows?