DeepSeek-V3.2 Released! Here's the Analysis

DeepSeek V3.2 — Technical Report Overview

---
> Source: DeepSeek, QbitAI
> Technical Report: Download PDF
---
New Releases
DeepSeek has announced two powerful models:
- DeepSeek-V3.2 — Balanced and practical, ideal for everyday Q&A, general Agent tasks, and tool usage.
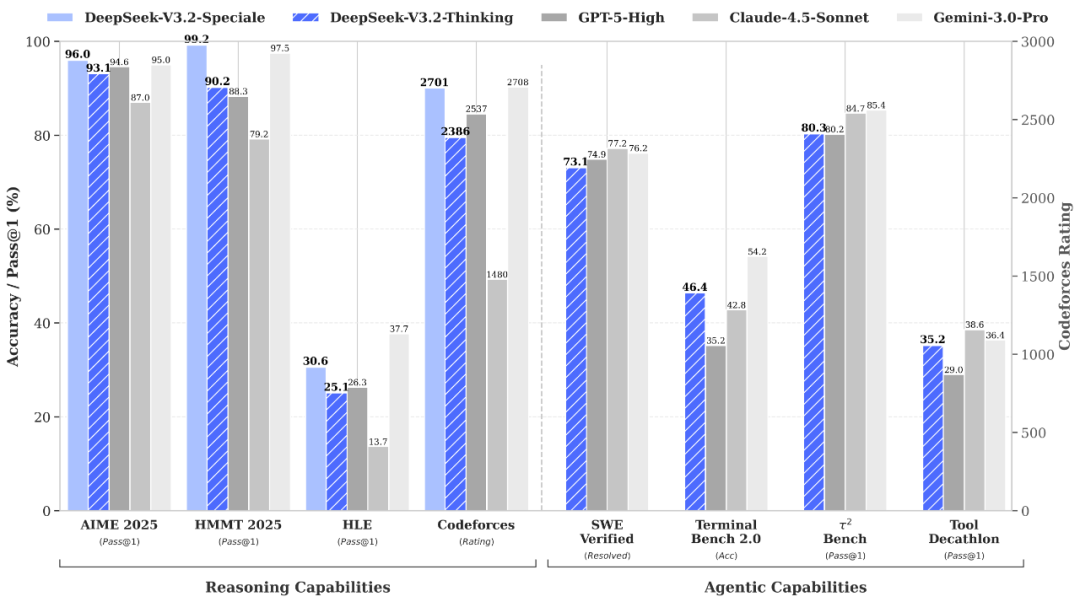
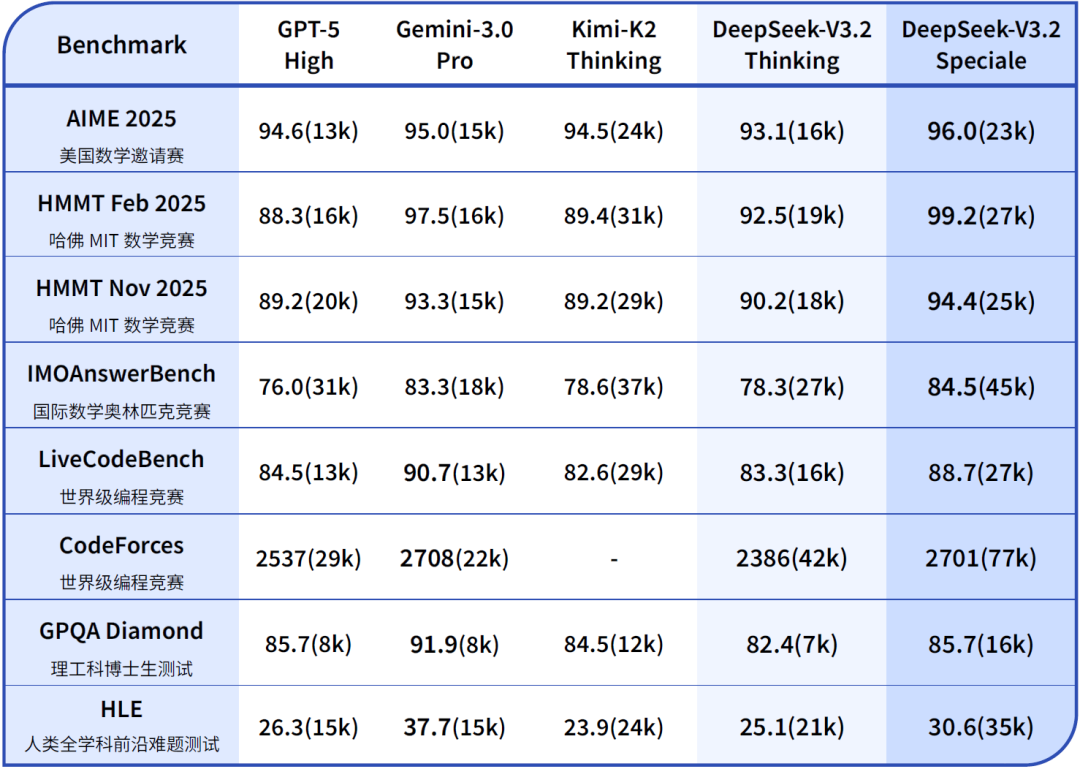
- Reasoning level: Comparable to GPT‑5, slightly below Gemini‑3.0‑Pro.
- DeepSeek-V3.2-Speciale — Optimized for extreme reasoning.
- Achievements: Surpassed Gemini‑3.0‑Pro in math and programming competitions; gold medals in IMO 2025 & IOI 2025.
---
Evolution of the V3 Series
Past Milestones
- DeepSeek V3 – Introduced MoE and Mixed Layer Attention (MLA).
- DeepSeek V3.1 – Added Hybrid Reasoning Mode; improved Agent capabilities.
- DeepSeek V3.1-Terminus – Enhanced language style and Agent stability.
- DeepSeek V3.2-Exp – Trial run for DSA architecture.
- DeepSeek V3.2 – First stable integration of DSA with large-scale RL and Agentic task synthesis.

Image source: Founder Park
---
DeepSeek-V3.2-Speciale Highlights
Strengths:
- Advanced instruction following
- Mathematical proof
- Logical verification
Recommended for: Complex mathematical reasoning, competitive programming, academic research.
Note:
- Not optimized for casual conversation or writing.
- Research-only.
- No tool-usage support.
---
Three Core Technical Upgrades
Core 1: DeepSeek Sparse Attention (DSA) — Efficient Long-Text Processing
DSA is the key architectural innovation in V3.2, reducing traditional attention complexity from O(L²) to O(L·k), significantly lowering inference costs for long-context tasks.
Key Features:
- FP8 precision support
- Compatible with MLA architecture
- Training-friendly integration
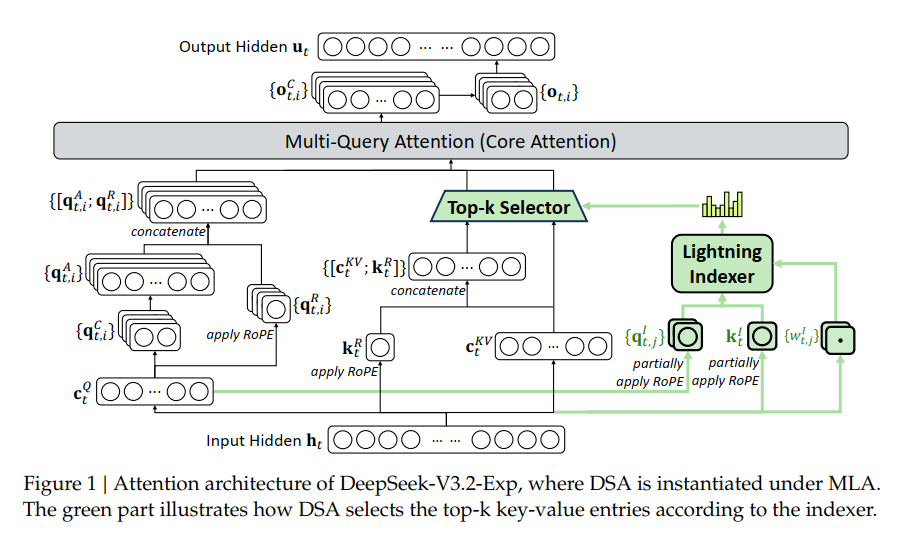
Components:
- Lightning Indexer — Selects top‑k relevant tokens quickly
- Fine-Grained Token Selection — Improves relevance filtering
- ReLU Activation — Enhances throughput
Two-Stage Training Strategy:
- Dense Warm-up: Train indexer with dense attention
- 1,000 steps / 2.1B tokens
- Sparse Attention: Use top‑2,048 key-value selections
- 15,000 steps / 943.7B tokens
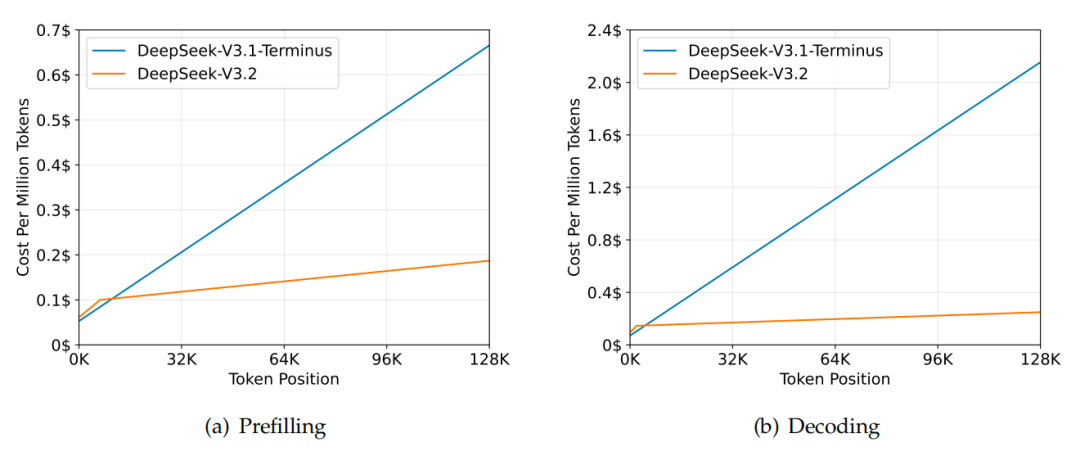
Performance Gains (128k sequence length, H800 cluster):
- Pre-fill per million tokens: $0.70 → ~$0.20
- Decode per million tokens: $2.40 → ~$0.80
---
Core 2: Scalable Reinforcement Learning
DeepSeek invested >10% of pre-training compute into RL — rare in open-source development — enabling significantly better performance on hard tasks.
GRPO Algorithm Enhancements:
- Unbiased KL Estimation — Removes systemic bias.
- Offline Sequence Masking — Filters deviating off-policy samples.
- MoE Routing Consistency — Saves routing paths between inference/training.
Expert Distillation:
- Trained in 6 domains: Math, Programming, Logical Reasoning, General Agent, Agent Programming, Agent Search.
- Each supports thinking and non-thinking modes.
- Specialist models generate domain datasets for final training.
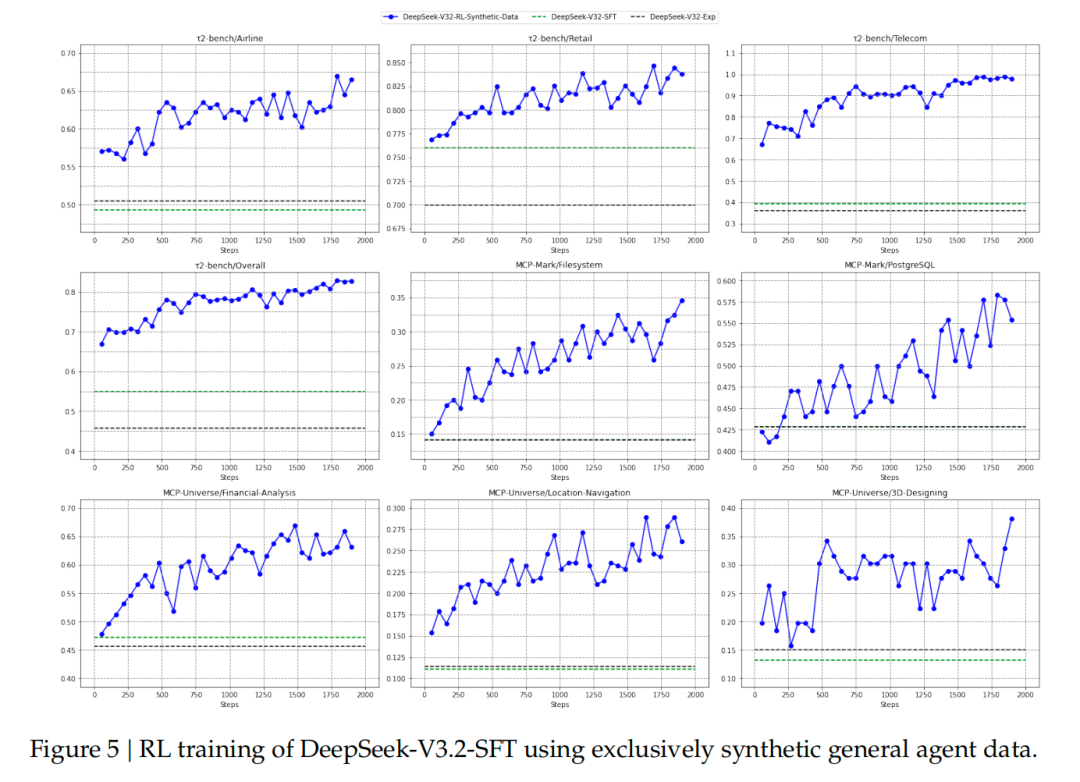
---
Core 3: Agent Capability Breakthrough
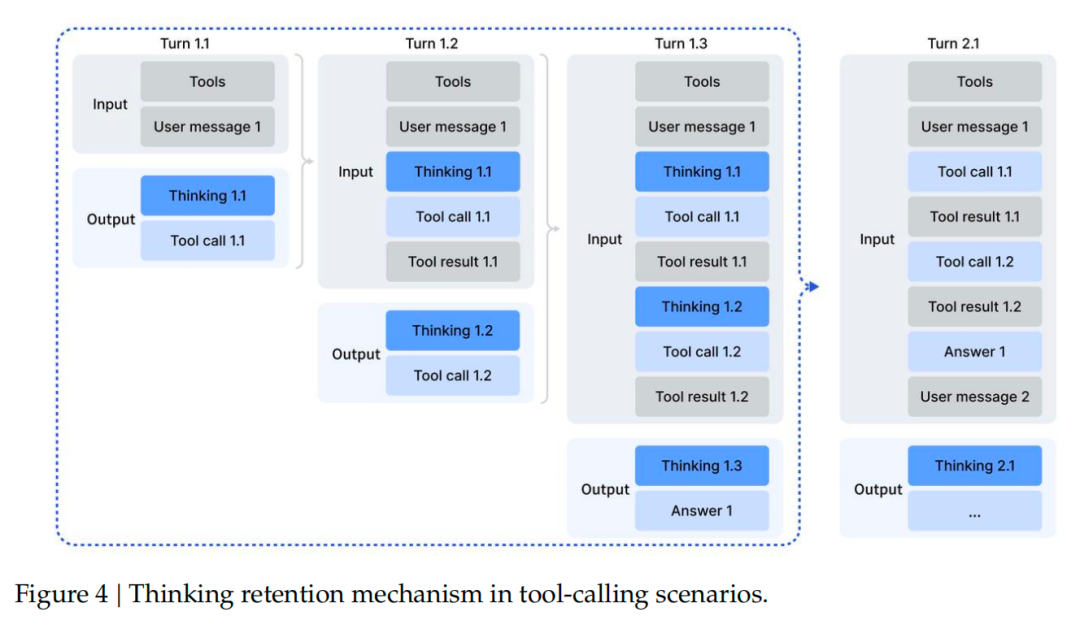
Context Management:
- Retain reasoning content unless a new user message is added.
- Tool-message additions keep reasoning history.
- Tool results persist even if reasoning content is removed.
Cold Start Prompt Design:
- System prompts guide natural tool calls in reasoning.
- Tagged reasoning paths enforced for complex problem solving.
Automated Environment Synthesis:
- 1,827 task-oriented environments
- 85,000 complex prompts
- Example: Travel Planning across multiple constraints

Specialized Agents:
- Code Agent: Harvests millions of filtered GitHub issue–PR pairs, builds environments for Python, Java, JS, etc.
- Search Agent: Generates training data from long-tail entity sampling, Q&A construction, and verification.
Evaluation Results:
- SWE‑Verified solve rate: 73.1%
- Terminal Bench 2.0 accuracy: 46.4%
- Strong tool-use performance on MCP‑Universe & Tool‑Decathlon — close to closed-source standards.
---
Deployment & Monetization Opportunities
Advanced models like DeepSeek‑V3.2 can be integrated into creative and commercial workflows via platforms such as AiToEarn官网 — an open-source global AI content monetization ecosystem.
Features:
- Multi-platform publishing: Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
- AI content generation + analytics + ranking (AI模型排名).
- Enables efficient monetization of AI-driven creations.
This infrastructure supports deploying agents in technical, creative, and multi-platform scenarios seamlessly.
---
In Summary:
DeepSeek-V3.2 pushes the frontier in efficient long-text processing (DSA), massive-scale RL, and multi-capability Agents — while the Speciale version offers unmatched reasoning power for advanced computational challenges.
---
Would you like me to also prepare a side-by-side performance table comparing V3.2 and Speciale against other major AI models? That could make this report even clearer.


