DeepSeek-V3.2 Series Open Source, Performance Rivals Gemini-3.0-Pro
🚀 Surprise Release on ChatGPT’s Third Anniversary
On the third anniversary of ChatGPT, DeepSeek suddenly unveiled two new AI models:
- DeepSeek‑V3.2 — designed for balanced practicality, ideal for daily Q&A, general Agent tasks, and real‑world tool invocation.
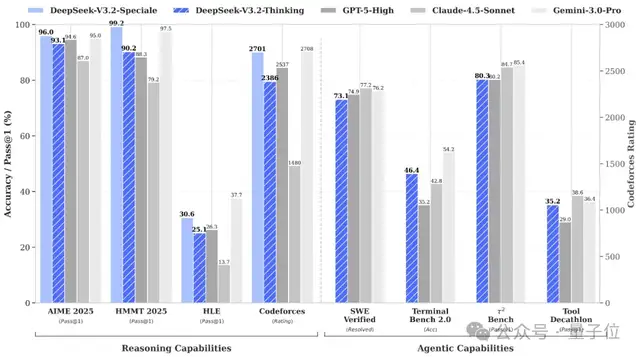
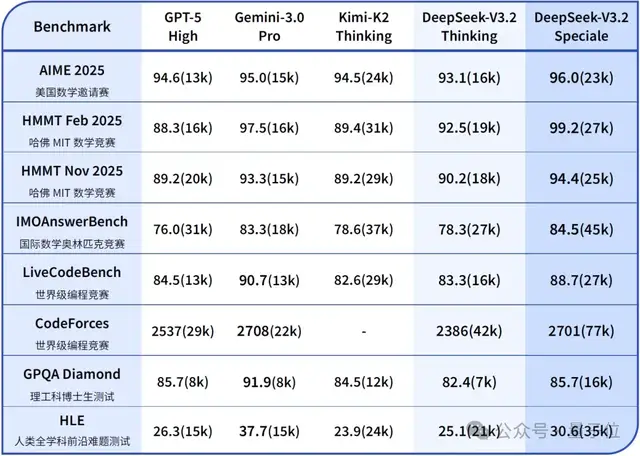
- 🧠 Reasoning ability: on par with GPT‑5, slightly below Gemini‑3.0‑Pro.
- DeepSeek‑V3.2‑Speciale — built for extreme reasoning, matching Gemini‑3.0‑Pro in benchmarks, excelling in advanced mathematical and logical tasks.
- 📚 Won gold medals in IMO 2025, CMO 2025, ICPC World Finals 2025, and IOI 2025, with ICPC second among humans and IOI tenth among humans.
---
DeepSeek‑V3.2 — Balanced, High‑Performance Agent Model
Key Characteristics
- GPT‑5‑level reasoning
- Shorter outputs than Kimi‑K2‑Thinking → faster response times
- Unified “thinking into tool invocation” — works in thinking and non‑thinking tool modes
- Trained with large‑scale Agent datasets: 1,800+ environments, 85,000+ complex instructions
Benchmark Highlights
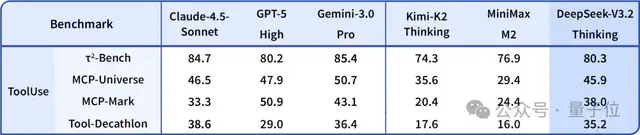
- Outperforms existing open‑source models in Agent evaluations.
- Wins tool‑invocation tests without specific training for those tools.
---
DeepSeek‑V3.2‑Speciale — Extreme Reasoning Edition
- Integrates DeepSeek‑Math‑V2 theorem‑proving
- Best for mathematical proofs, programming competitions, academic research
- Not optimized for casual conversation or writing
- Research‑only, no tool invocation
- Outperforms V3.2 in complex tasks → much higher token usage & cost
---
Availability
- App & Web use DeepSeek‑V3.2 by default
- Speciale available via temporary API
- Technical report, paper, and benchmarks released publicly
---
🔍 Technical Innovations in V3.2
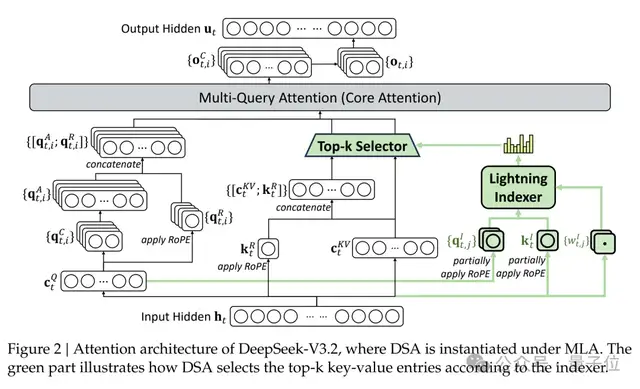
DeepSeek Sparse Attention (DSA)
- New attention mechanism
- Traditional: O(L²) complexity → slow for long contexts
- DSA: O(L·k), with k ≪ L
- Faster reasoning for long sequences with no performance drop
- FP8 precision, works with MLA (Multi‑Query Attention)
- Two key components:
- Lightning Indexer — quickly ranks token relevance
- Fine‑grained token selection
---
Training Process — V3.1 Terminus to V3.2
Phase 1: Dense Warm‑up
- Dense attention maintained
- Train lightning indexer to align with main attention
- 1,000 steps, 2.1 B tokens
Phase 2: Introduce Sparse Mechanism
- Each query token selects 2,048 key‑value pairs
- 15,000 steps, 943.7 B tokens
---
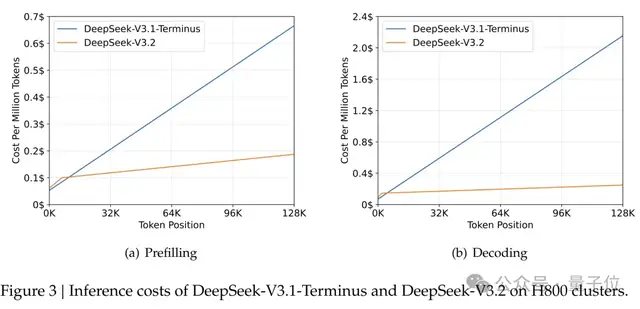
🏎 Performance Gains
On 128 k sequences:
| Stage | V3.1‑Terminus Cost | V3.2 Cost |
|-------------|--------------------|-----------|
| Prefill | $0.70 / 1M tokens | ~$0.20 |
| Decode | $2.40 / 1M tokens | $0.80 |
---
💡 Heavy Investment in RL
- RL compute budget >10% of pre‑training — rare in open‑source LLMs
- Developed stable, scalable RL protocol
- Targeted post‑training improvements for complex tasks

---
RL Scalability Enhancements
- Unbiased KL Estimation — removed systemic bias, stabilized gradients
- Offline Sequence Masking — prevents off‑policy degradation
- Keep Routing for MoE — keeps training/inference expert paths consistent
---
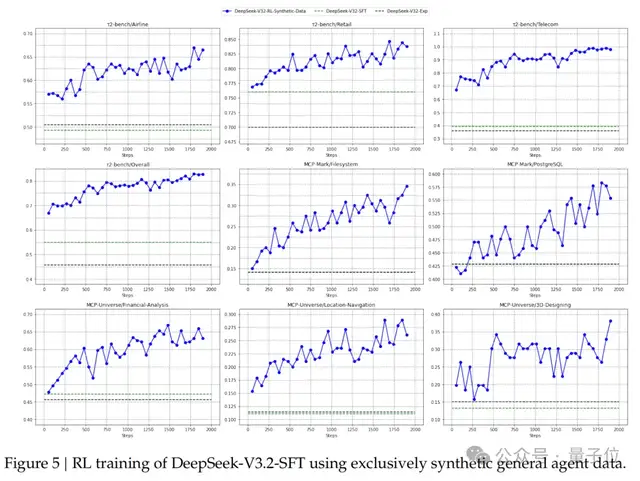
Expert Distillation Approach
Task Domains:
- Mathematics
- Programming
- Logical reasoning
- Agent general tasks
- Agent programming
- Agent search
Each domain: supports “thinking” & “non‑thinking” modes
→ Expert models feed high‑quality domain data into final training
---
🔧 Breakthrough in Agent Capabilities
- Combines reasoning + tool usage
- Optimized thinking context management:
- Discards reasoning traces only on new user messages, not tool actions
- Tool‑call history & results preserved
---
Prompt Engineering for Cold Starts
- Special prompts encourage tool calls during reasoning
- For competitions: clearly separates “thinking” from final answer
---
Real‑World Applicability
Platforms like AiToEarn官网 enhance model utility by:
- Multi‑platform publishing (Douyin, Bilibili, LinkedIn, X, etc.)
- AI content creation, analytics, and monetization
- Public AI model rankings (AI模型排名)
---
⚙ Automated Environment Synthesis
- 1,827 environments, 85,000 complex prompts
- Example: travel plan under constraints (budget balance, no repeat cities)
- “Hard to solve, easy to verify” — perfect for RL


---
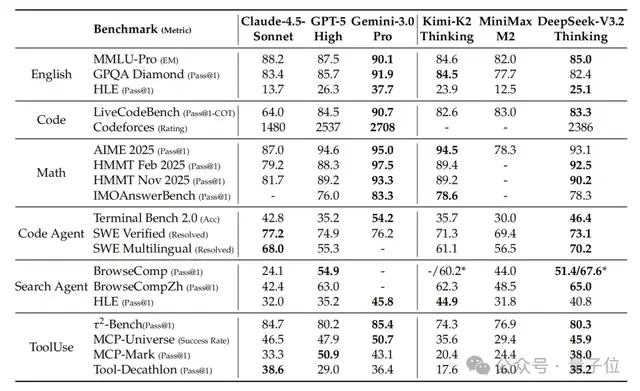
Code & Search Agent Data
- Code Agent: millions of GitHub issue–PR pairs → executable environments in Python, Java, JavaScript
- Search Agent: multi‑agent pipeline, long‑tail entity sampling, verified answers
Results:
- SWE‑Verified: 73.1%
- Terminal Bench 2.0: 46.4%
- Tool benchmarks: near closed‑source model performance
---
📉 Limitations
- Lower training FLOPs → narrower world knowledge than top closed‑source models
- Less token‑efficient — longer trajectories needed for equal quality
- Improvement targets set for future releases
---
DeepSeek, when will R2 arrive?! 🎯
---
For researchers, developers, and AI creators, DeepSeek‑V3.2 is a blueprint for integrating reasoning, tool usage, and efficiency.
Platforms like AiToEarn官网 let builders:
- Connect AI generation with publishing
- Analyze performance across platforms
- Monetize creativity at scale
Open‑source + multi‑platform reach = real‑world AI impact.


