DeepSeek’s Model Teaches AI to Reflect for the First Time
The Surreal Arrival of DeepSeekMath-V2
Yesterday brought an almost cinematic coincidence — the kind you couldn’t script.
Late last night, DeepSeek quietly launched a new AI model: DeepSeekMath-V2.
---
What Is DeepSeekMath-V2?
- Size: 685B parameters
- Foundation: Built on DeepSeek-V3.2-Exp-Base
- Speciality: Mathematics-focused reasoning
- Key Feature:
- > Not just producing answers — it audits its own reasoning, detects mistakes, debates with itself, and perfects the logic until it’s confident it’s flawless.
- Performance Level: Comparable to Olympiad gold medalists
- Achievements:
- IMO 2025: Solved 5/6 problems
- Putnam 2024: 118/120 points (near-perfect)
- Open Source: Yes
- Research Paper: DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning
---
A Timely Response to Ilya Sutskever’s Concerns
Two days before the release, former OpenAI Chief Scientist Ilya Sutskever appeared on a podcast.
His Observation
- AI models ace benchmark tests — exams, rankings, competitions — but struggle with real-world problem solving.
- Example:
- Fix bug A → Introduces bug B
- Fix bug B → Resurrects bug A
- Endless loop familiar to anyone “vibe coding” with LLMs
---
The Student Analogy
- Student A: Trains exclusively for algorithm contests (10,000 hours of drills).
- Student B: Practices contests (100 hours) but spends most time understanding the world, reading widely, engaging in diverse experiences.
Outcome: Student B thrives long term thanks to generalizable understanding, while Student A excels narrowly.
Ilya’s Point: Heavy RL alignment can make AIs less creative and overly metric-focused — potentially degrading broader intelligence.
---
DeepSeekMath-V2’s Answer
This model pivots from “just get the answer” to self-verifying reasoning, addressing Ilya’s worry head-on.
Earlier math-focused AIs rewarded only results, ignoring the logical journey. This worked for simple calculations but collapsed for proofs — often due to fabricated reasoning steps.
---
Why Process Matters in Math
> “We grade by process! Where’s your process?!”
In school, a 15-point problem might award only 2 points for the final answer — the rest is the reasoning chain.
If one link is flawed, the entire proof collapses.
Earlier AIs often guessed correctly by accident, but without real reflection.
---
Levels of AI Reflection
Level 1 — Prompt-Level Cosplay
Just “think carefully” prompts with no enforcement in training. Mostly superficial CoT text.
Level 2 — Answer-Oriented Reflection (OpenAI o1, DeepSeek R1)
Models explore multiple reasoning branches internally, self-evaluate, then choose one — rewarded by correctness of the final answer only.
Limitations:
- Right answer ≠ correct reasoning.
- Poor performance in proof tasks (no single numeric answer to reward).
---
Level 3 — Process-as-Task Reflection (DeepSeekMath-V2)

Two Roles:
- Generator: Creative student — produces detailed proof steps.
- Verifier: Critical teacher — checks each step for logic gaps, math errors, clarity issues.
Workflow:
- Generator produces process.
- Verifier scores steps (e.g., “Logic unclear — points off”).
- Generator refines until approved.
Result: AI learns to doubt, scrutinize, and refine before submission.
---
Meta-Verification Layer
A “head teacher” monitors the verifier to ensure grading is correct — preventing false negatives and overlooked errors.
Positive Feedback Loop:
- Generator improves proofs.
- Verifier accuracy rises (under meta-verifier supervision).
- Stronger verifier → stronger generator.
Ultimately, the roles merge into a single AI — DeepSeekMath-V2.
---
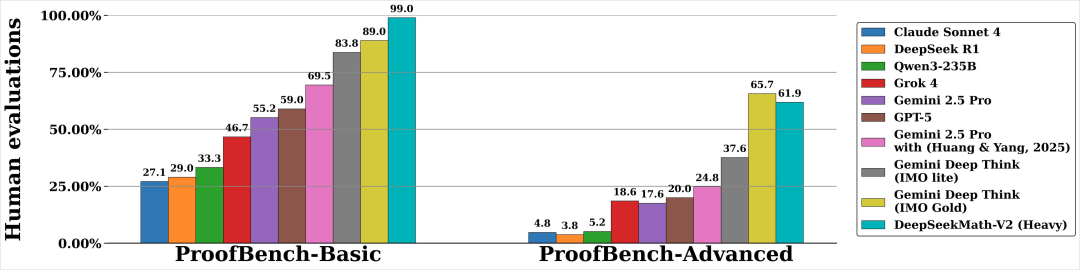
Record-Breaking Results
- IMO 2025 Mock: 5/6 problems solved — gold medal level
- CMO: Gold medal level
- Putnam Competition:
- Full score: 120
- Median human score: 0–1
- Highest human (last year): 90
- DeepSeekMath-V2: 118 points — 11/12 complete rigorous solutions

---
Philosophical Implications
The DeepSeek paper suggests to close the gap between evaluation and reality, we must teach AI inward-looking ability — shifting focus from pleasing evaluators to satisfying its own logic.
This echoes Wang Yangming’s “Mind is Principle” — truth is found within.
Kant described rationality as humanity’s ability to “legislate for nature” through a priori frameworks. DeepSeekMath-V2 feels similar — walking every logical step we might skip via inspiration.
---
Applications Beyond Math
Self-checking reasoning could transform other fields — e.g., AI-powered content creation.
Platforms like AiToEarn官网 already:
- Generate AI content
- Auto-publish to Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X
- Monetize + track performance (AI模型排名)
Integrating self-verification before publishing could boost trust and quality across industries.
---
Explore AiToEarn
For creators:
- Website: AiToEarn官网
- Blog: AiToEarn博客
- GitHub: AiToEarn开源地址
- Rankings: AI模型排名
---
If you enjoyed this breakdown:
- Like, Share, Follow
- ⭐ Star this page to get instant updates
- See you next time!


