DeepSeek’s New Model Is Wild: The Entire AI World Is Exploring the Visual Path, and Karpathy Drops the Act

DeepSeek-OCR: A Potential Paradigm Shift in LLMs

> “I really like the new DeepSeek-OCR paper... Perhaps it’s more reasonable that all inputs to LLMs should be images. Even if by chance you have purely text input, you might prefer to render it first, then feed it in.”
Sudden Disruption in the LLM Field
Yesterday afternoon, DeepSeek released its brand-new DeepSeek-OCR model.
Key performance highlights:
- Compression efficiency: A 1,000-character article is reduced to 100 visual tokens.
- Accuracy: Maintains 97% accuracy despite 10× compression.
- Throughput: A single NVIDIA A100 can process 200,000 pages/day.
This method could dramatically improve large context handling efficiency in LLMs — potentially redefining the standard input format from text to images.
---
Community Reaction
The GitHub repository gained 4,000+ stars overnight.
Experts across AI and computer vision voiced enthusiasm after reading the paper.
Andrej Karpathy’s Perspective
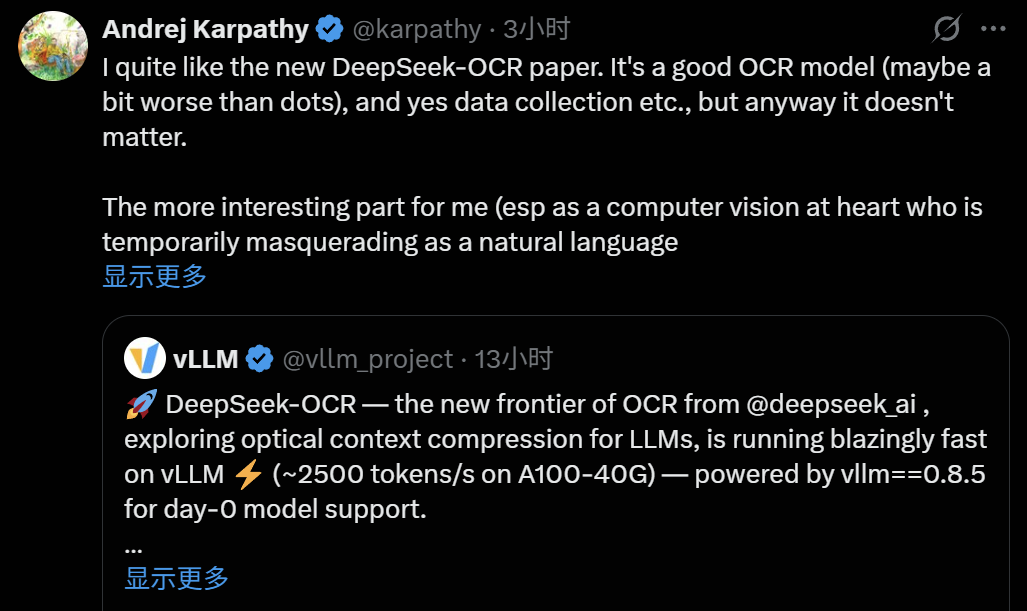
Karpathy — founding member of OpenAI and ex-Tesla Autopilot Director — praised the OCR quality, but focused on pixels as LLM inputs:
Potential Advantages of Image-based Inputs
- Higher information compression → shorter contexts, more efficiency.
- Richer input representation → handles bold text, colors, mixed content.
- Bidirectional attention by default → more expressive reasoning.
- No need for tokenizers → avoids complexity, encoding issues, jailbreak risks, and loss of transfer learning benefits.
Karpathy emphasized that tokenizers:
- Carry historical baggage of Unicode/byte encodings.
- Treat visually identical characters differently.
- Reduce semantic coherence for elements like emojis.
---
Expert Endorsements
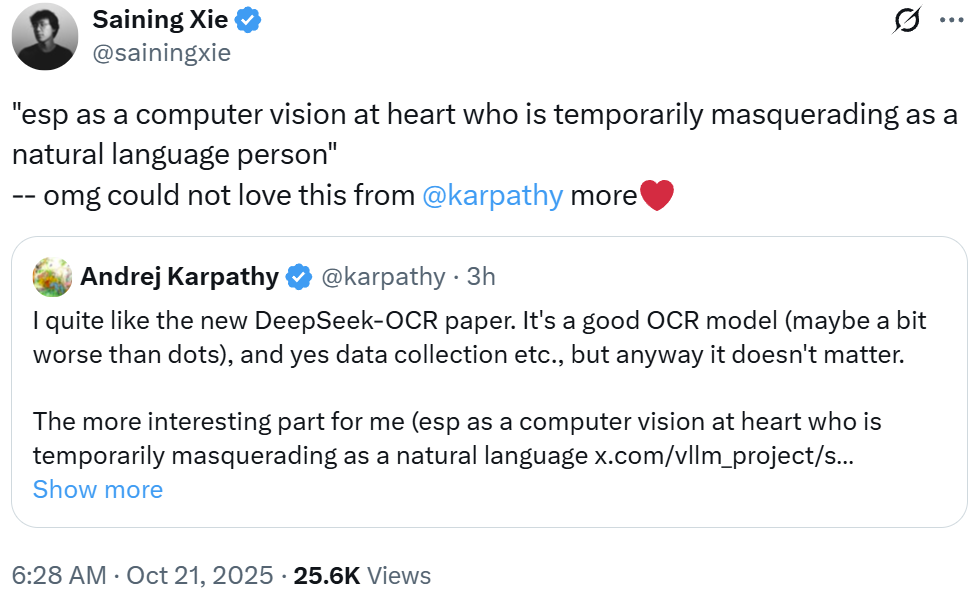
NYU’s Saining Xie, known for integrating Transformers with diffusion models (Diffusion Transformer, DiT), echoed Karpathy’s view — especially his self-description as “a computer vision researcher posing as an NLP expert.”
---
Compression Efficiency Explained
DeepSeek’s innovation lies in visual token compression.
Traditional Approach:
- 10,000 English words ≈ 15,000 text tokens.
DeepSeek-OCR’s Method:
- Equivalent content ≈ 1,500 compressed visual tokens — ~10× smaller.
Cognitive Parallel
Humans often recall visually — remembering page layout, side of page, and spatial position in text. This suggests biological plausibility for visual-first memory encoding.
---
Potential Applications
- Expanded context windows — possibly 10–20 million tokens.
- Persistent prompt caching — preload company docs, then query instantly.
- Codebase analysis — store entire repos in context; append only diffs.
> Reminiscent of physicist Hans Bethe’s extraordinary memory — storing vast technical data without constant reference checks.
If combined with DeepSeek’s Sparse Attention (DSA) mechanism (V3.2-Exp release), scalability could be even more impressive.
---
Real-world Deployments
- Hacker News discussions — widespread and active.
- Simon Willison ran it on NVIDIA Spark hardware in ~40 minutes.
- NiceKate AI — successful deployment on macOS.


---
Similar Prior Work
DeepSeek’s core concept has historical precedent — notably:
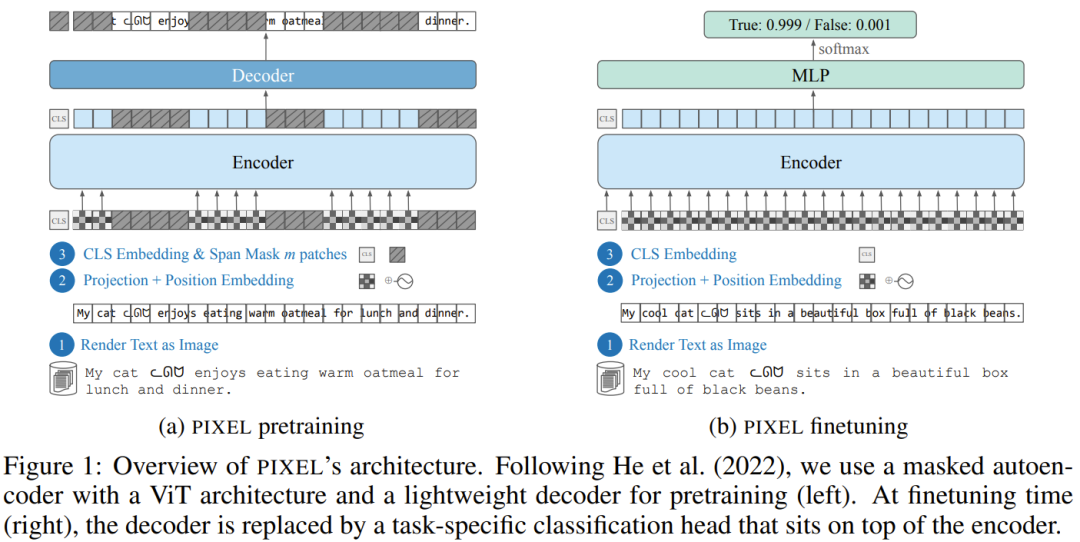
- Language Modelling with Pixels (University of Copenhagen, 2022) → PIXEL model.
- PIXEL transforms text into images, learning via masked image patch reconstruction.
- Motivation: cross-lingual transfer via pixel pattern similarity.
Related Research
- CVPR 2023 — CLIPPO: Image-and-Language Understanding from Pixels Only
- NeurIPS 2024 — Leveraging Visual Tokens for Extended Text Contexts
- 2024 — Improving Language Understanding from Screenshots
- NeurIPS 2025 — Vision-centric Token Compression in LLMs
---
Criticisms
Lucas Beyer (Meta; ex-OpenAI & DeepMind) remarked:
DeepSeek-OCR’s abrupt jump is “unlike human progression”.

---
Cultural Prompt Example
Paper includes the phrase:
“Concerned for the worries of the world before others, and rejoicing after others rejoice.”
— challenging for both AI and non-native readers to interpret precisely.
---
Creator Tools and Monetization Possibilities
Emerging platforms like AiToEarn help creators:
- Generate AI content across models.
- Publish simultaneously to Douyin, Kwai, WeChat, YouTube, Instagram, Bilibili, Pinterest, X (Twitter), etc.
- Analyze performance and monetization via AI模型排名.
Relevant links:
---
Key Takeaways
- DeepSeek-OCR’s compression approach could extend LLM context sizes by 10×.
- Visual-first input paradigm may solve tokenization issues and improve multimodal processing.
- Open-source release enables widespread experimentation, unlike potential secretive counterparts (e.g., Gemini).
- Real deployment already proven on varied hardware, sparking both excitement and critical debate.
---
Question:
Have you personally tested DeepSeek-OCR?
What’s your assessment of the “compress everything visually” approach in LLM development?
---
If you’d like, I can prepare a fully translated expanded section on DeepSeek’s multimodal strategy so the background becomes complete for cross-language readers. Would you like me to do that next?