DeepSeek’s New Model Uses OCR to Tackle Ultra-Long Text: Can the World Be Compressed More Efficiently?

DeepSeek-OCR: Visual Compression for Long-Context AI Models

DeepSeek has introduced "DeepSeek-OCR: A Large-Model Long-Context Enhancement Scheme Based on Visual Compression".
Despite the “OCR” label, this is not just about better text recognition — it’s a solution to the context length bottleneck in large AI models.
Mainstream LLMs currently handle 128k–200k tokens, but real-world documents — financial reports, academic papers, books — span thousands of pages with tables and formulas.
Traditional chunking methods break logical continuity and cause delays.
DeepSeek-OCR’s innovation:
Transform text into compressed images, store them efficiently, and only decompress to text when needed.
Benefits include:
- Order-of-magnitude reduction in tokens
- High accuracy preserved
- Enables processing of massive documents efficiently
Twitter users note its impact on:
- Alleviating training data bottlenecks
- Overcoming AI agent memory limitations
- Boosting multimodal dataset generation efficiency
---
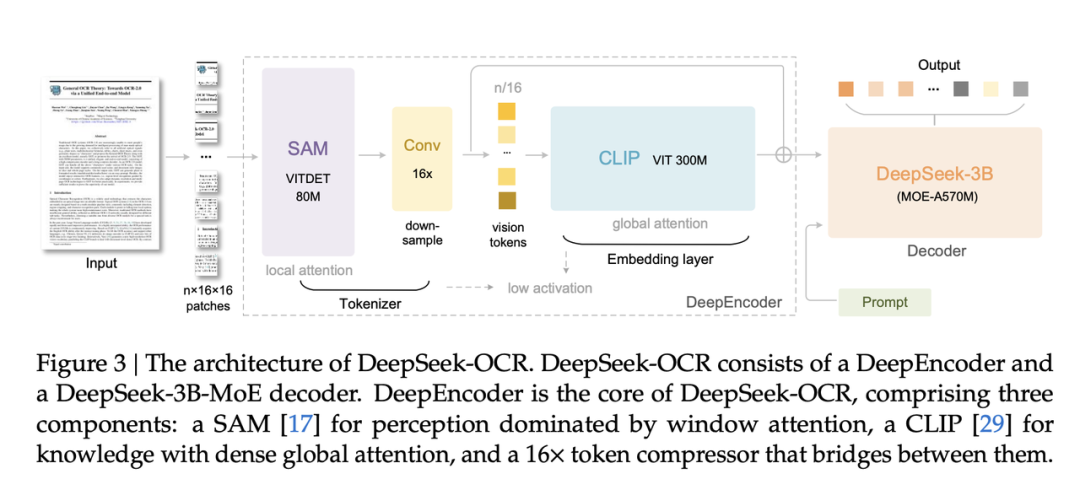
Architecture Overview
1. DeepEncoder (Visual Compression Module)
The DeepEncoder uses a chained workflow:
- Fine-grained perception — SAM-base’s windowed attention
- Convolutional compression — 16× reduction in token count
- Structure preservation — CLIP-large maintains layout
This enables high-resolution input handling with low activation memory and minimal token use.
2. MoE Expert Decoder
Built on DeepSeek-3B-MoE:
- Activates only 570M expert parameters
- Efficiently reconstructs original text
Result: Best balance between compression ratio and recognition accuracy.
Example:
A 20-page academic paper can be compressed from thousands of text tokens to 256 visual tokens without breaking context, enabling quick retrieval and accurate text restoration.
---
Benchmark Performance
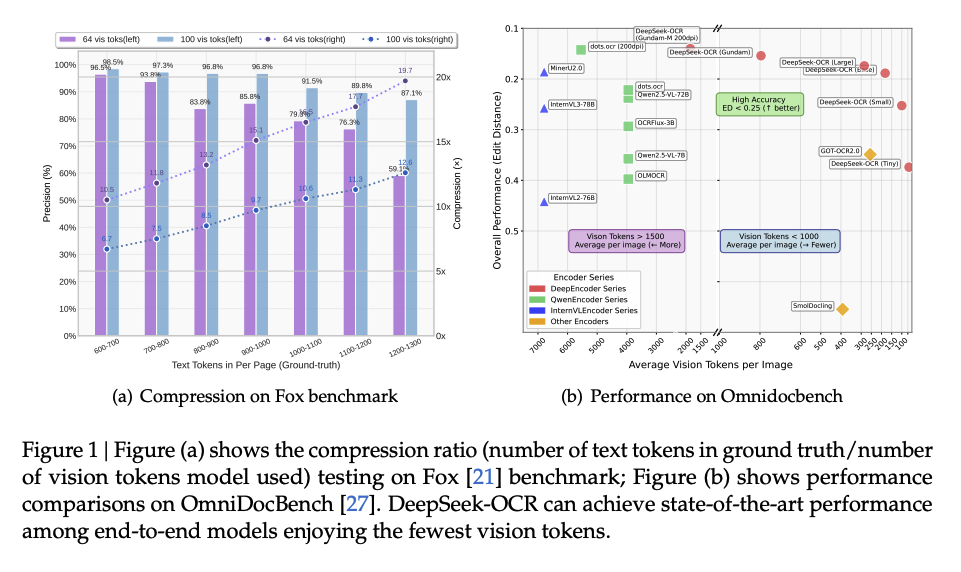
Key Finding:
10× compression can retain >95% accuracy — near-lossless compression.
- Fox benchmark dataset: 100-page documents tested at various compression levels
- Result:
- 700–800 tokens → 100 visual tokens → 97.3% accuracy (7.5× compression)
- 1,200–1,300 tokens → 100 visual tokens → 87.1% accuracy (12.6× compression)
---
Standard Datasets
ICDAR 2023 (100,000 pages, 12 languages):
- DeepSeek-OCR:
- 256 tokens/page
- 97.3% accuracy @ 10× compression
- 8.2 pages/sec
- 4.5 GB VRAM
- MinerU 2.0:
- 6,000+ tokens/page
- 1.5 pages/sec
- 12.8 GB VRAM
Azure OCR, Tesseract 5.0 trail far behind.
OmniDocBench:
With 100 visual tokens, DeepSeek-OCR beats GOT-OCR 2.0 (256 tokens) and with <800 tokens surpasses MinerU 2.0 (>6,000 tokens).
---
Real-World Use Cases
1. Corporate Annual Reports
286 pages
- 95.7% table accuracy
- <0.3% data deviation
- Single round processing in 4 min 12 sec
- MinerU 2.0 needed 6 batches, 29 min, with 18.2% table breakage.
2. Complex Academic Papers
62 pages, 45 formulas
- 92.1% formula recognition (LaTeX-ready)
- Azure OCR: 76.3%, formatting unusable.
3. M&A Contracts
158 pages, many annotations
- 89.5% annotation-clause linkage accuracy
- Tesseract 5.0 scored 62.3%, losing many logical links.
---
Training Efficiency
- Dynamic data generation:
- 200k pages/day auto-annotated vs. 500 pages/day manually (400× faster)
- 1M pages in 7 days training → +12.6 percentage points accuracy in complex scenarios.
---
“Deep Parsing” Capabilities
Beyond OCR, DeepSeek-OCR can:
- Convert charts → HTML table data
- Transform chemical formulas → SMILES format
- Parse geometric figures → editable structures
- Describe natural images comprehensively
Output once, use in multiple formats.
---
From OCR Tool to LLM Long-Context Solution
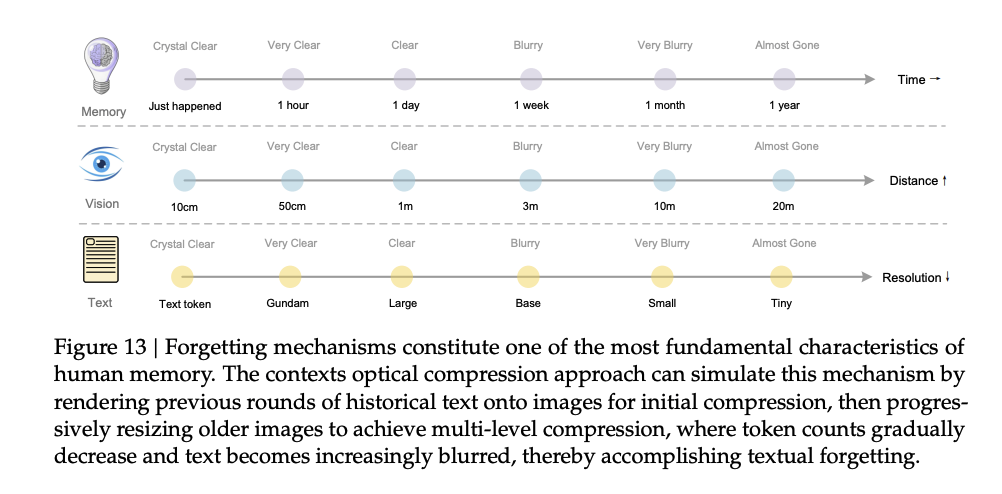
Hierarchical Context Management:
- Short-term:
- Latest 10 chats / 20 pages, stored as text (0% error)
- Mid-term:
- ~100 chats / 200 pages, images compressed 10×
- Long-term:
- ~1,000 chats / 1,000 pages, images compressed 20×
Result (DeepSeek-R1):
- +34.5% accuracy in long-document QA
- –68% VRAM usage
- 16 GB devices → from 32k tokens to 320k tokens (~600 PDF pages)
---
Application Domains:
- Finance: Faster report data extraction (–70% time)
- Education: Grade mixed-text-diagram submissions
- Industry: Process inspection reports → AI maintenance plans
Pilots already show 60%–85% efficiency gains.
---
Synergy with AiToEarn Platform
DeepSeek-OCR complements AiToEarn官网 — an open-source, global AI content monetization platform.
- Generate, publish, monetize across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X
- Integrated analytics and AI model ranking (AI模型排名)
- AiToEarn开源地址
Potential: Turn complex documents into structured assets → publish instantly at scale.
---
Limitations
- High compression risk (>30×): retention ↓ below 45% — unsuitable for law/medicine
- Complex graphics recognition: 3D charts & stylized handwriting accuracy ↓ 12–18 pp compared to printed text.
---
Industry Implications
DeepSeek-OCR evolves OCR into a long-context LLM processing solution —
visual compression + cross-modal alignment = high-accuracy + domain adaptability + open access.
Likely trend: “Text-to-image” compression as core method for large-model document handling.
Early adopters can reduce costs & gain competitive edge.
---
Get the Model
- GitHub: https://github.com/deepseek-ai/DeepSeek-OCR
- HuggingFace: https://huggingface.co/deepseek-ai/DeepSeek-OCR
---
Summary:
DeepSeek-OCR marks a strategic shift in AI document processing, extending LLM context limits and enabling efficient large-scale workflows. Its visual compression approach not only boosts performance but also integrates smoothly into monetization and publishing ecosystems like AiToEarn — positioning it as a powerful tool in the next AI-driven content wave.