DeepSeek’s New Model Wows Silicon Valley: 2D Vision Compresses 1D Text, Runs on Single GPU, “Google’s Core Secrets Open-Sourced”

DeepSeek’s Latest Open‑Source Model Is Making Waves in Silicon Valley
DeepSeek has unveiled a 3B‑parameter open‑source model with an exponential performance leap, embracing a “less is more” philosophy. Some observers even speculate it has revealed techniques comparable to Google Gemini’s guarded trade secrets.
The only quirk? The name: DeepSeek‑OCR.

---
Solving the Long‑Text Compute Explosion
Large language models suffer from massive compute requirements when processing long sequences of text. DeepSeek‑OCR tackles this challenge using a vision‑based context compression strategy:
- A single image can contain huge amounts of text while requiring fewer tokens.
- Images serve as compressed representations of text — just like speed readers scan a page without reading every word.
Key benchmark:
- Compression ratio ≤ 10× → OCR decoding accuracy ~97%.
- Compression ratio 20× → Accuracy ~60%.
> A picture is worth a thousand words — and far fewer tokens.
---
Efficiency at Scale
DeepSeek‑OCR delivers high‑efficiency training data generation:
- 200,000+ pages/day
- Single A100‑40G GPU
Since launch:
- 3.3K GitHub stars
- HuggingFace’s #2 hot leaderboard position
- Broad praise across X (Twitter)
AI leader Andrej Karpathy commented:
> I like it... especially the idea that images can be a better input format for LLMs. Brilliant.
Some call it “AI’s JPEG moment” — a possible shift in how AI memory is architected.
---
Speculation Around Gemini Secrets
Rumors suggest DeepSeek‑OCR’s approach may overlap with Google Gemini’s internal techniques.

---
Beyond the Model: Toward AGI
Many see merging vision + language as a possible gateway to AGI. The DeepSeek paper also explores AI memory and “forgetting” mechanisms.
---
Core Concept: Context Optical Compression
The big idea:
> If one image can carry thousands of words, compress text into images and let models see the meaning.

Benefits:
- Fewer visual tokens replace many text tokens.
- Significant compute cost reduction for large models.
DeepSeek‑OCR achieves SOTA on OmniDocBench for document parsing.
---
Results Snapshot
The positioning chart shows:
- DeepSeek‑OCR uses the fewest visual tokens (far right)
- Maintains top-tier performance (vertical axis: lower = better)
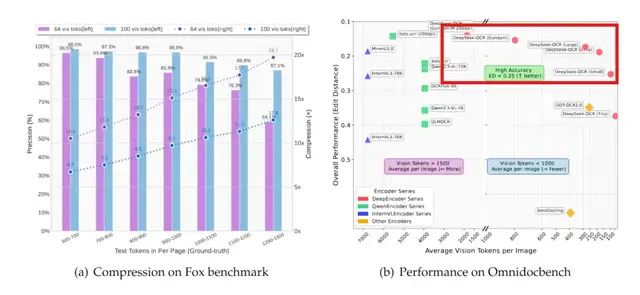
Performance Highlights:
- 100 tokens → Beats GOT‑OCR 2.0 (256 tokens/page)
- 400 tokens (285 effective) → Matches prior SOTA
- <800 tokens → Outperforms MinerU2.0 (~7000 tokens/page)
---
Future Potential
This approach could inform memory‑efficient LLM/VLM design. Optical context compression may reshape future AI architectures.
Creators and researchers can explore similar ideas on platforms like AiToEarn官网, which supports cross‑platform publishing and monetization across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X.
Tools like AiToEarn核心应用:
- Rank AI models
- Provide analytics
- Integrate publishing pipelines
---
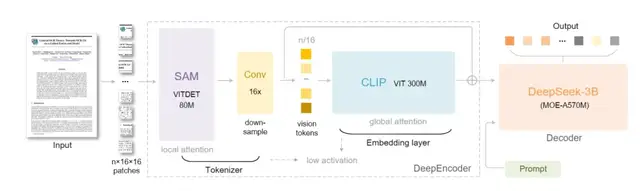
Architecture Overview
DeepSeek‑OCR consists of:
- Encoder — DeepEncoder
- Transforms images into highly compressed visual tokens
- Decoder — DeepSeek3B‑MoE‑A570M
- Reconstructs text from compressed tokens
---
DeepEncoder: Key Innovation
Mission: Produce very few high‑density visual tokens for high‑res images.
Pipeline:
- Local Processing
- SAM‑base model (80M params)
- Window attention extracts local features efficiently
- Generates many tokens but keeps memory usage low
- Compression
- 16× convolutional compressor reduces token count drastically
- Example: 1024×1024 → 4096 tokens → compress to 256 before global attention
- Global Understanding
- CLIP‑large model (300M params)
- Global attention processes condensed tokens with manageable compute
Dynamic modes:
- Tiny: 512×512, 64 tokens
- Gundam: Dynamic chunking, ~800 tokens
---
Versatility in Parsing
DeepSeek‑OCR excels at:
- Standard text recognition
- Complex visuals: financial statements, chemical formulas, geometry diagrams
- Over 100 languages

---
Research Team
Relatively low‑profile but impactful:
- Haoran Wei — Led GOT‑OCR 2.0 at StepStar, focusing on complex document parsing.
- Yaofeng Sun — Contributed to multiple DeepSeek models (R1, V3).
- Yukun Li — Nearly 10,000 Google Scholar citations; involved in DeepSeek V2, V3.

---
Optical Compression & Human Forgetting
Concept: Model memory decays like human memory:
- Recent memory: Clear, high‑fidelity (more tokens, high resolution)
- Long‑term memory: Blurry, reduced resolution (fewer tokens)
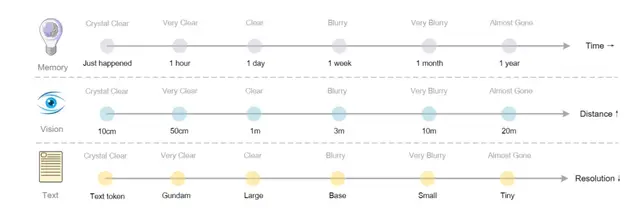
Potential Benefit:
- Dynamically allocate compute to different time spans in ultra‑long contexts
- Could enable infinitely long context processing
- More human‑like memory usage vs. today’s uniform context handling
---
Useful Links
- Hugging Face: https://huggingface.co/deepseek-ai/DeepSeek-OCR
- GitHub: https://github.com/deepseek-ai/DeepSeek-OCR
---
Creators experimenting with ultra-long context models can leverage AiToEarn官网 for seamless multi‑platform content generation, publication, analytics, and AI model ranking (AI模型排名) — bridging AI innovation with real‑world deployment.