DeepSeek’s Ultimate Ambition: Transforming the Core Language of Large Models into Images | DeepSeek Paper Analysis

DeepSeek-OCR — Optical Compression for Long-Context AI

When we think about DeepSeek, multimodality is rarely the first association.
However, on October 20, DeepSeek released DeepSeek-OCR as an open-source project — an OCR (Optical Character Recognition) model achieving SOTA results on benchmarks like OmniDocBench.

Why the sudden move into OCR?
The answer: the computational bottleneck of long-context processing in LLMs.
---
Core Idea — Optical Context Compression
The paper proposes a radical approach:
- Render text into images
- Use a Visual Language Model (VLM) to “decompress” the image back into text
Since images can be encoded into far fewer visual tokens than text tokens, this can dramatically reduce context length requirements.
Well-known AI figure Andrej Karpathy highlighted four key benefits:
- Information compression: Shorter context windows with higher efficiency
- More versatile inputs: Not limited to plain text — supports formatting, images, and colors
- Stronger processing capacity: Visual bidirectional attention can outperform autoregressive text attention
- No input tokenizer: Removes traditional NLP tokenization bottlenecks
This could redefine LLM input paradigms — making "a picture worth a thousand words" a literal design principle.
---
01 – OCR in Name, Long Context in Essence
LLMs compete to expand context windows from thousands to millions of tokens. The limitation: Transformer attention mechanism complexity scales quadratically with sequence length.
Current optimizations — grouped attention, multi-query attention, RoPE — only reduce compute cost, not token count.
DeepSeek instead asked:
> Can we reduce the number of tokens themselves?
This led to Context Optical Compression:
- Text tokens → sequential units in LLM
- Visual tokens → small image patches in VLM
Example:
- A 1024×1024 image → 4096 patches → 4096 visual tokens
- Half-size image can encode ~10,000 text tokens’ worth of content
---
By seeing large documents as images instead of reading them as text, LLMs can store and process far more information, potentially with richer multimodal understanding.
Platforms like AiToEarn官网 could eventually integrate such compression to publish AI-generated content cross-platform, analyze performance, and monetize efficiently — enabling scalable creative workflows that benefit from reduced token counts.
---
02 – DeepEncoder: The Art of Compression
To achieve compression, DeepSeek designed DeepEncoder — a special-purpose visual encoder for high-resolution text images with minimal activation memory usage.
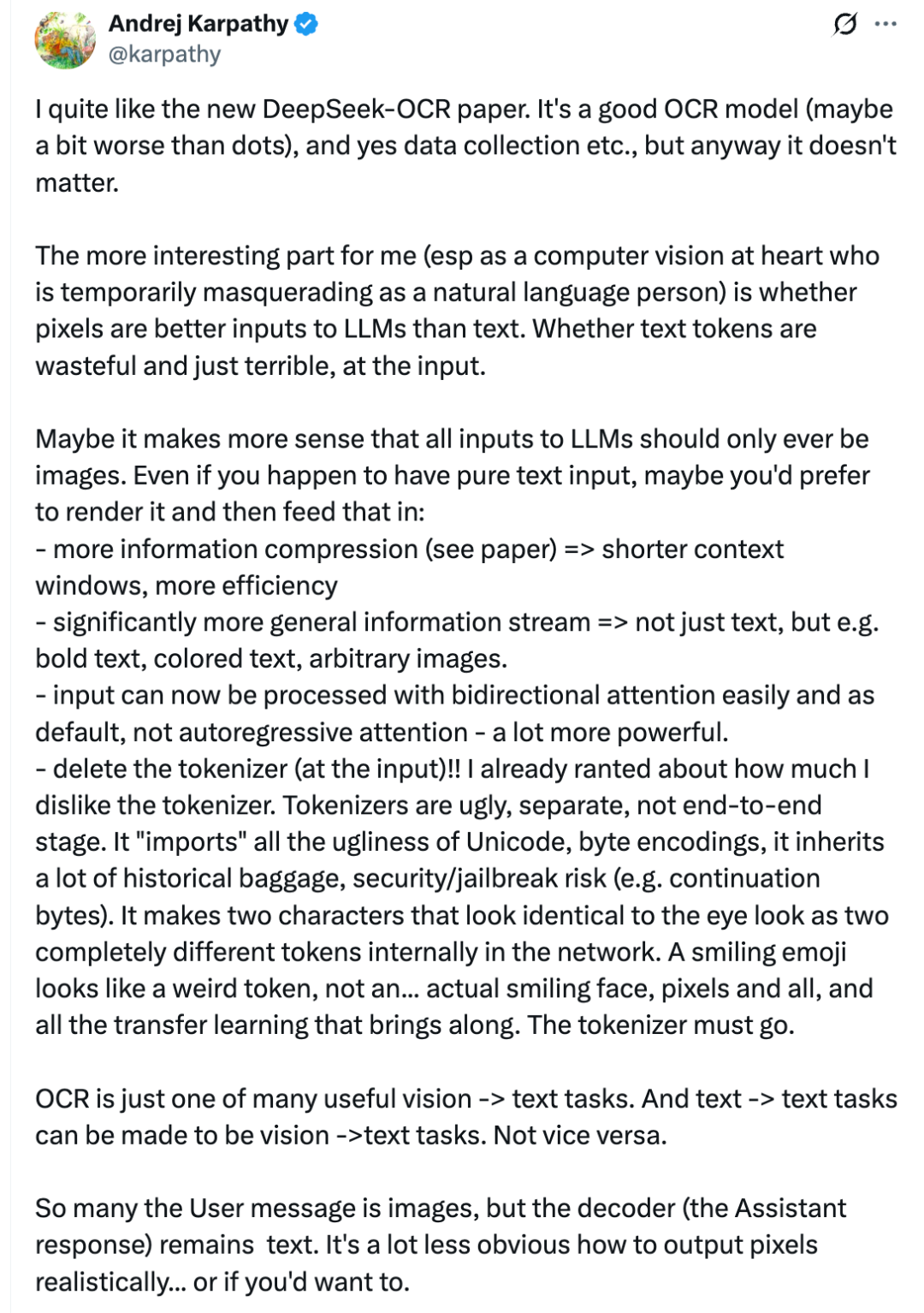
Three-Stage Architecture (~380M parameters)
- Local Perception — 80M SAM-base perceiver
- Windowed attention on 4096 patches
- Minimal activation memory
- Compression — 16× learnable convolution downsampling
- 4096 → 256 visual tokens
- Retains essential features for decompression
- Global Understanding — 300M CLIP-large
- Processes only the compressed tokens
- Uses expensive global attention without memory overflow
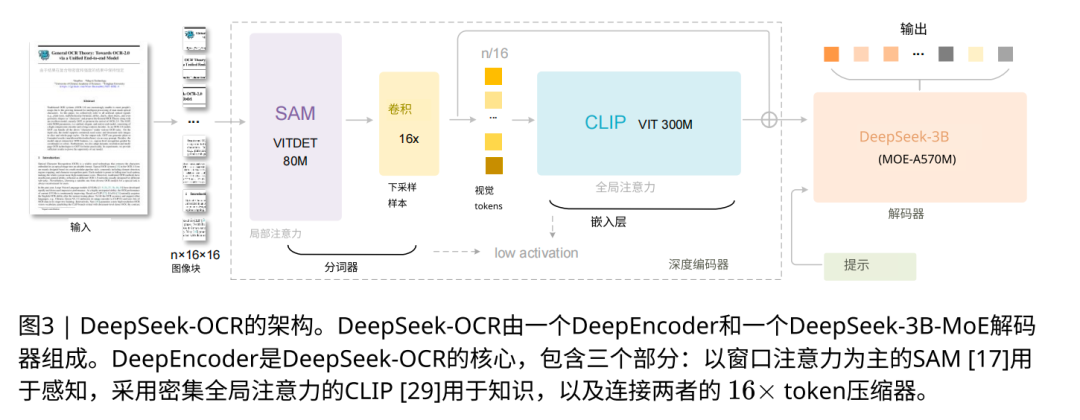
The output: 256-token visual summary → fed to DeepSeek-3B-MoE decoder → generates reconstructed text.
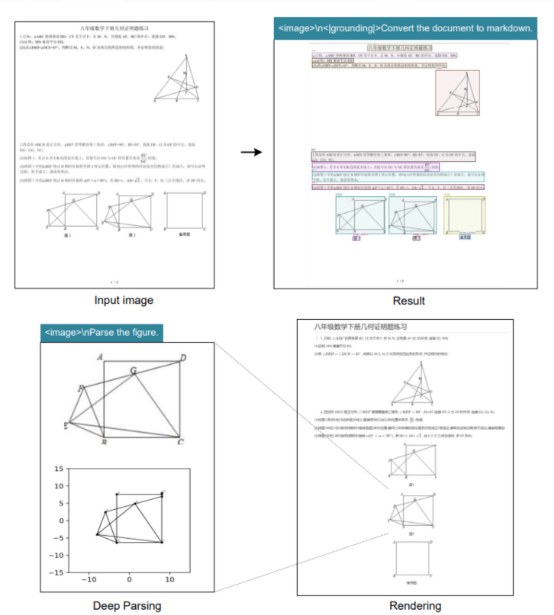
Advantages over other VLMs:
- Single sequential refinement pipeline
- Internal compression (no token explosion)
- Global attention after compression (avoids overflow)
---
Compression Performance
- 10× Compression — 64 visual tokens decoding 600–700 text tokens with 96.5% accuracy
- 20× Compression — usable quality (~60%)
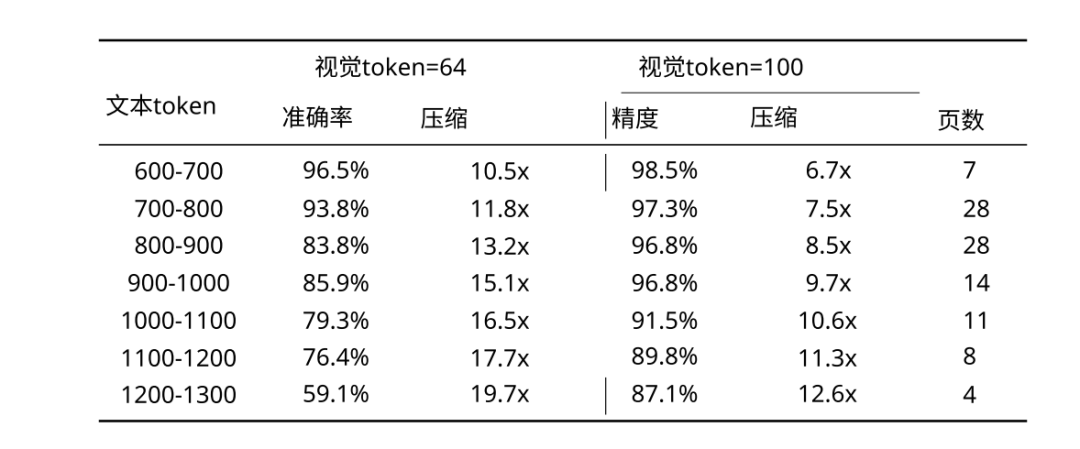
Token needs vary by document:
- Slides: ~64 tokens
- Books/reports: ~100 tokens
- Newspapers: ~800 tokens (Gundam Mode)
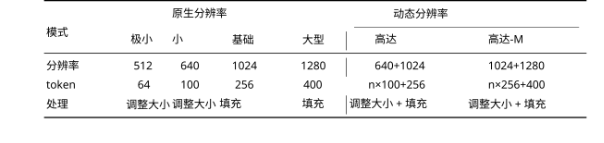
OmniDocBench results:
- Small mode: 100 tokens → beats GOT-OCR2.0 (256 tokens)
- Gundam mode: <800 tokens → beats MinerU2.0 (~7000 tokens)
Processing scale:
- 1× A100 GPU → ~200K pages/day
- 20× servers (8× A100 each) → ~33M pages/day

Supports 100+ languages, maintains formatting, outputs pure text or captions.
---
03 – Enhanced Windowed Attention
Earlier attention-window models (BERT, RNN) suffered information island effects — losing long-range dependencies.
DeepSeek-OCR solves this via:
- Pre-trained encoder–decoder with deep layout/language priors
- Hybrid local + global attention after compression
Result: prior-guided perceptual compression → maintains global coherence without heavy compute cost.
---
04 – Simulating Human Memory with Optical Forgetting
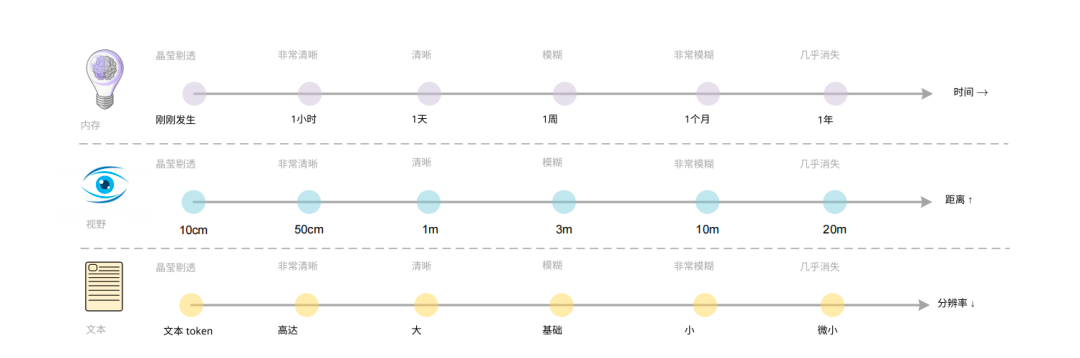
Human memory is layered and decays over time — important info stays vivid, irrelevant fades.
DeepSeek-OCR's multi-resolution setup could simulate:
- Recent contexts (high-res, Gundam mode)
- Mid-term (Base mode, 256 tokens)
- Long-term (Tiny mode, 64 tokens)
---
Example — Layered Conversation Memory
- Render yesterday’s chat → Base mode image
- Encode → 256 visual tokens
- Concatenate with today’s text tokens
- Decoder generates coherent responses using both
This could lead to theoretically infinite context through progressive compression, unlike sliding windows or brute-force retention.
---
Limitations & Next Steps
Current compression is uniform — important and trivial details blurred equally.
Future target: selective compression based on relevance, attention, and importance.
---
05 – Toward Unified Input Formats
Humans perceive text visually before decoding it linguistically.
Karpathy’s idea:
> Render all LLM inputs as images first
Could yield more natural, human-like, and context-scalable AGI memory systems.
This vision aligns with open-source tools like AiToEarn官网 & AiToEarn开源地址, enabling multimodal publishing workflows from a unified, image-first input system.
---



