# Reinforcement Learning for Large Language Models — From Theory to Ultra-Large-Scale Systems
*Date: 2025‑11‑12 • Location: Zhejiang*

Reinforcement learning (RL) is a **key method for advancing large language models (LLMs) toward higher intelligence**. It remains the most critical and complex stage in their training.

RL is challenging not only in terms of algorithms, but also in terms of **system architecture requirements**.
This article is adapted from **"Design, Implementation, and Future Development of Reinforcement Learning AI Systems"**, a talk by Alibaba algorithm expert **Cao Yu** at *AICon Beijing 2025*.
It traces RLHF systems from theory through engineering practice, sharing current state, trends, theory, best practices, and future perspectives — especially in open-source ecosystems and community collaboration.
---
## AICon 2025 Overview
**Event Dates:** Dec 19–20, Beijing
**Theme:** *"Exploring the Boundaries of AI Applications"*
Focus topics:
- Enterprise‑level agent deployment
- Context engineering
- AI product innovation
Speakers from leading enterprises and startups will share hands‑on experience in applying LLMs for R&D, operations, and business growth.
---
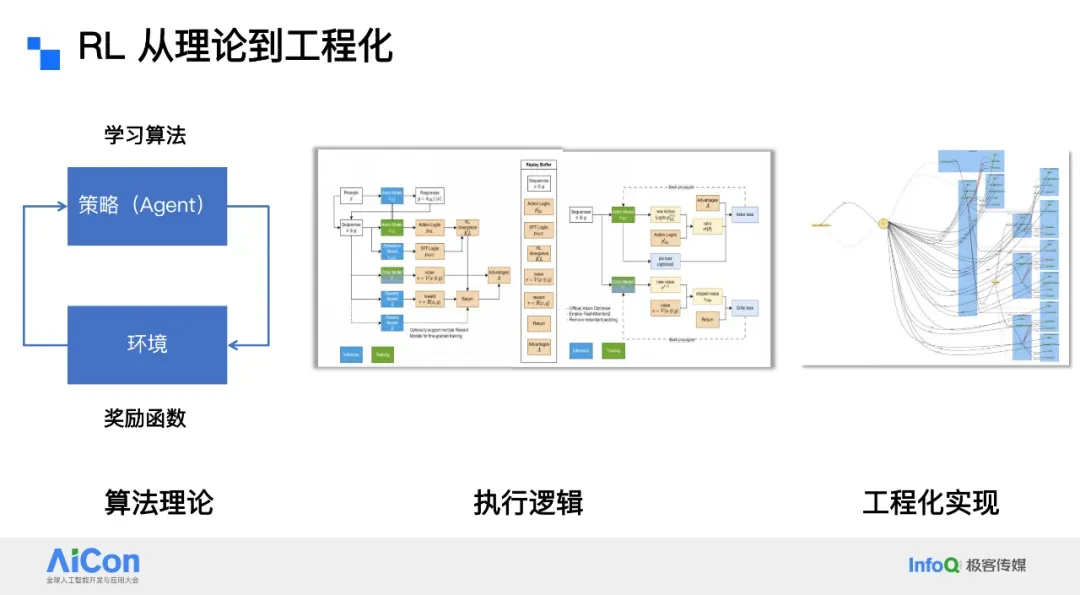
## RLxF — Bridging Theory and Engineering
RL theory starts from a simple loop:
**Agent ↔ Environment interaction**.
- **Agent:** originally RL entities; now also LLMs acting as intelligent agents.
- **Environment:** the context in which the Agent operates, delivering state and reward.
- **Policy:** how the Agent chooses actions based on state.
In practice, frameworks like **Open RLxF** reveal **engineering complexity** beyond theory:
- *Training-mode models* (green)
- *Inference-mode models* (blue)
- Interconnected components driving aligned training.
Ant Group’s **AReaL** framework shows dense, real‑world RL operations diagrams — emphasizing additional engineering challenges.
---
## Foundations: Environment & Policy
- **Environment:**
- Chatbot: conversation with humans
- Programming agent: policy network + code executors + browser automation
- **Policy:** defines decision logic; transforms a chatbot into an active Agent.
---
## Key Additional Elements
### 1. Reward Function
Determines feedback quality.
Evolution:
- Human feedback RL
- Constitutional AI RL
- Rule‑verifiable RL
### 2. Algorithms
Drive **policy updates** based on state, actions, and rewards.
Examples: **PPO**, **GRPO**, **DPO**.
---
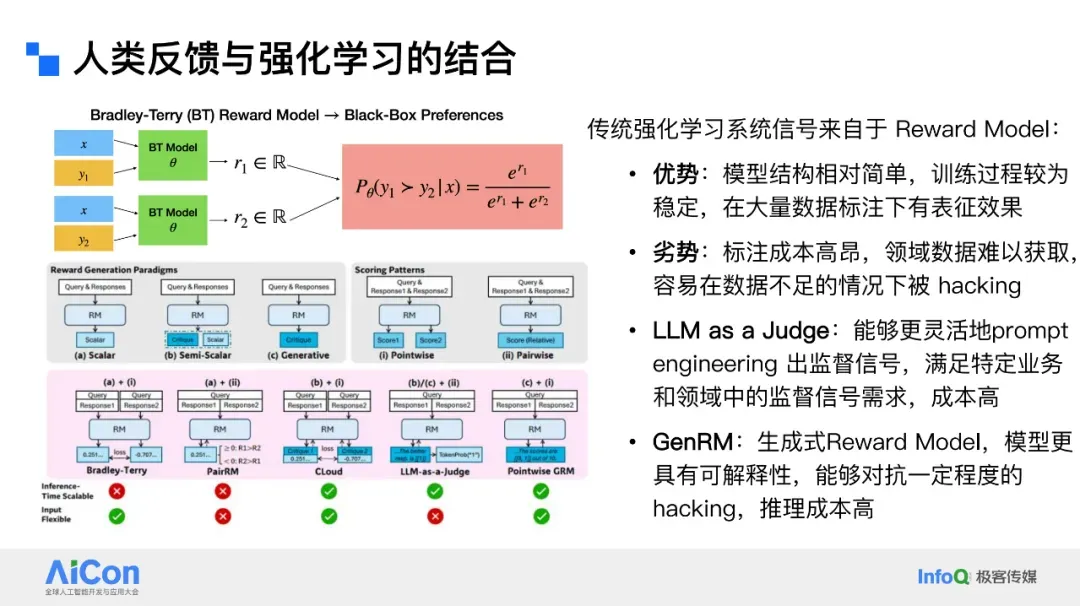
## Human Feedback Reinforcement Learning (RLHF)
**Process:**
1. Humans rate model responses.
2. Train a proxy model to mimic human judgement.
3. Use proxy model’s reward signal for RL updates.
**Pros:**
- Simple architecture
- Stable training
- Strong generalization
**Cons:**
- Limited human annotation coverage
- Risk of *reward hacking*
---
## Combining Human + Machine Feedback
**DeepSeek**’s best practice:
- Reward model outputs both score & textual explanation.
- Improves transparency & multi-sample performance.
LLMs themselves can act as reward models, offering domain-specific evaluation — at higher cost.
---
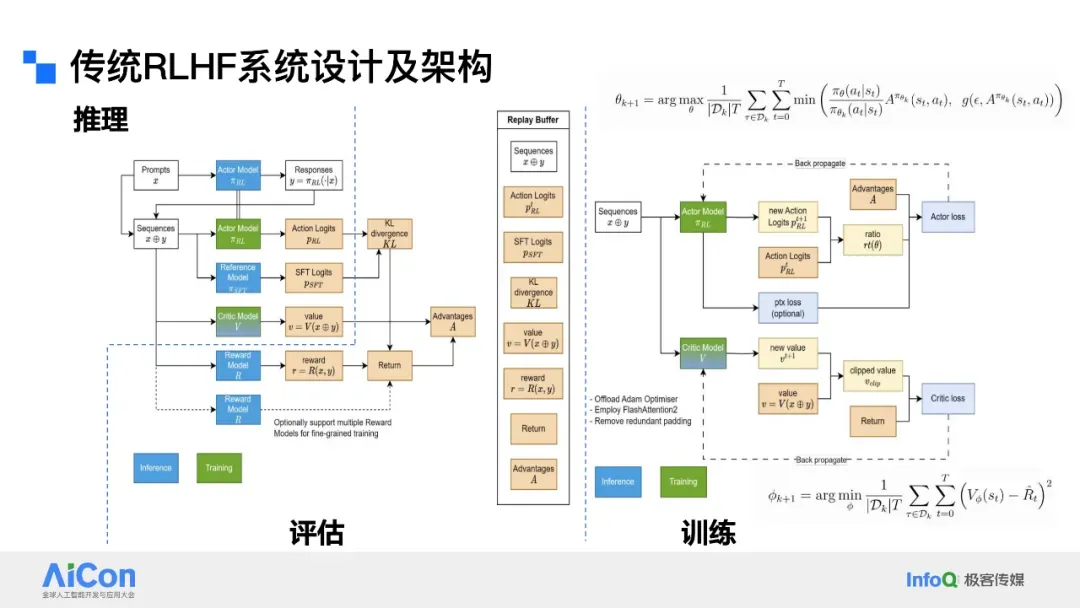
## Classic PPO Workflow
The PPO process includes:
- Reasoning (inference)
- Evaluation (human + reward model)
- Training (Actor–Critic updates)
Training uses **advantage estimation** to guide policy updates, while Critic model evaluates actions.
---
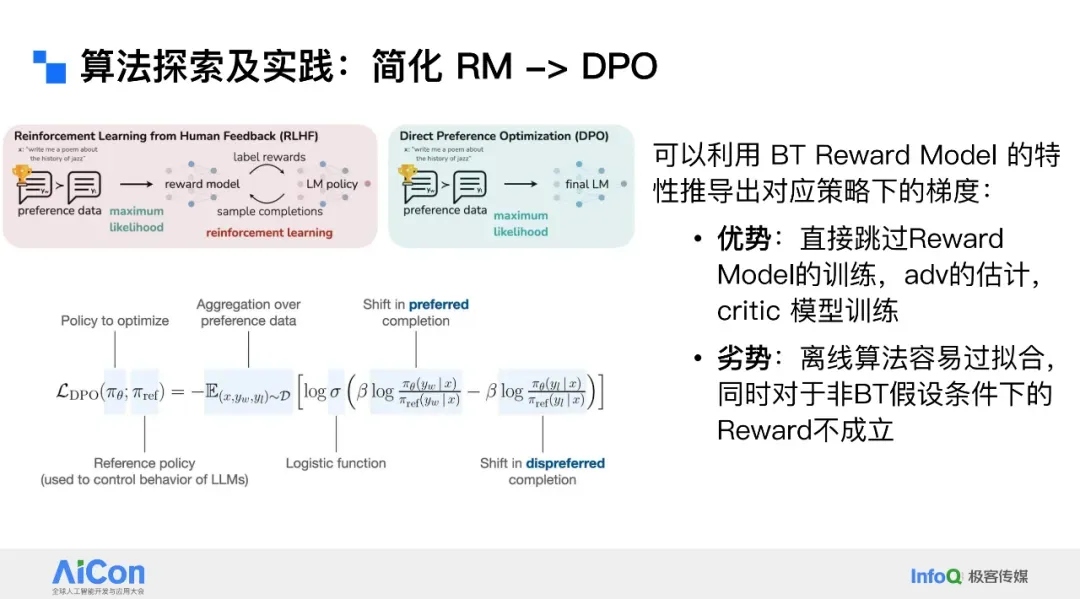
## Alternative Algorithms: BT Reward Model & DPO
Advantages:
- Skip training reward/critic models.
- Useful in niche, preference‑pair scenarios.
Drawbacks:
- Strong “better vs worse” assumption
- Offline training risks overfitting
Popularity faded as RL frameworks matured.
---
## GRPO — Applied by DeepSeek R1
**Enhancement:** Avoid Critic model training cost
**Approach:** Estimate advantage via repeated inference (mean & std deviation)
Best for reasoning‑intensive use cases; still leaves open questions about value functions for future multi‑round tasks.

---
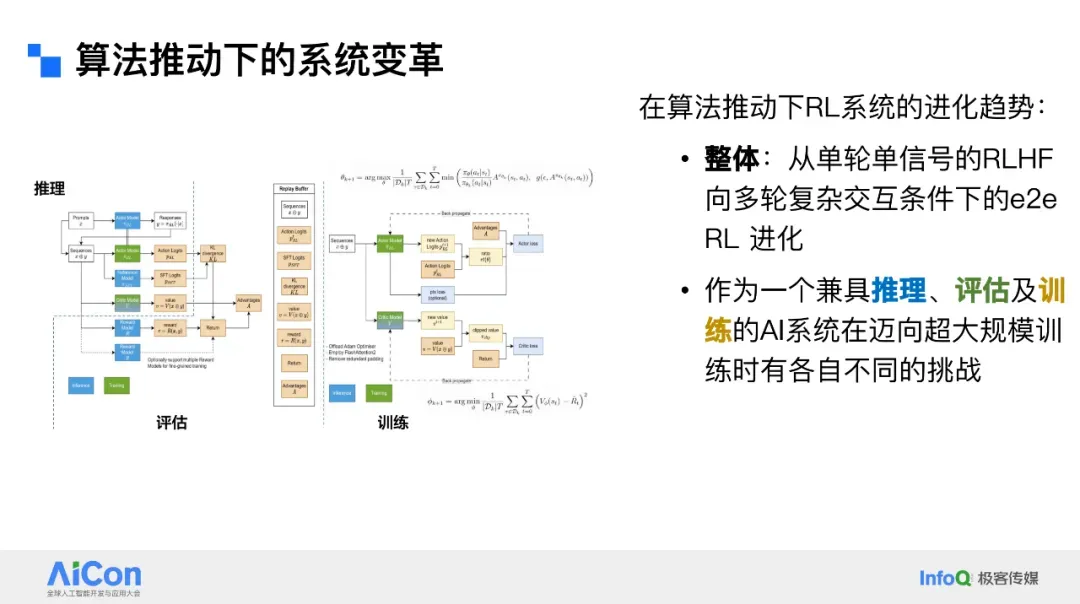
## Ultra-Large-Scale RL Trends
Development speed: measured in weeks, not years.
Shift from **RLHF** to **RLAIF** — expanding from human alignment to reasoning capability.
Example: DeepSeek + GRPO + high compute → major reasoning gains (e.g., top scores on China’s college entrance exams).

---
## Toward End‑to‑End RL
End‑to‑end RL means:
- Long‑form, multi‑turn, open‑ended decision making
- Integration with Internet, executors, tools
Challenges:
- Multi‑model training
- Reasoning + evaluation integration
Requires **systems + algorithm co‑design**.
---
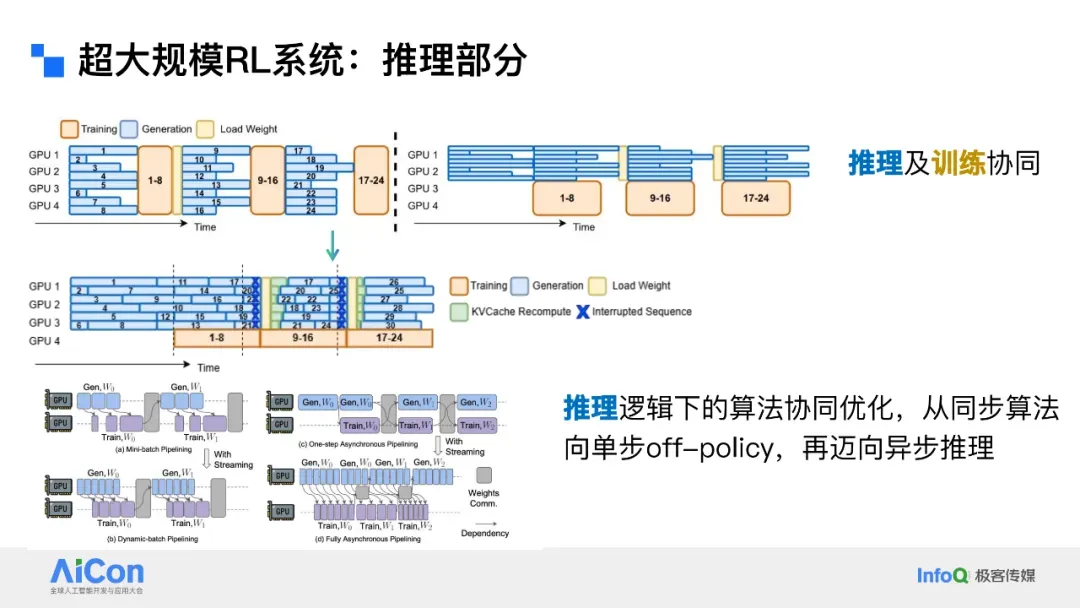
## Inference in Ultra‑Large‑Scale RL Systems
Key differences from static inference:
- **Weights update online** → must broadcast to cluster
- **Interruptibility** to avoid off‑policy inference
- Data routing + KV cache optimization
- GPU/CPU weight sharing (e.g., via CUDA IPC)

---
## Data Distribution Challenges
AReaL approach:
- Handle variable sample lengths efficiently
- Avoid full‑batch wait bottlenecks
- Support interruption on weight update
---
## Evaluation Stage Future
Current: CPU‑based rule scoring
Future: GPU + CPU simulation environments (games, metaverse)
Goal: Real‑world aligned large-scale evaluation systems

---
## Training Framework Decisions
Factors:
- Hugging Face + DeepSpeed ecosystem compatibility vs Megatron power
- Choice between ZeRO‑3, FSDP, FSDP2

---
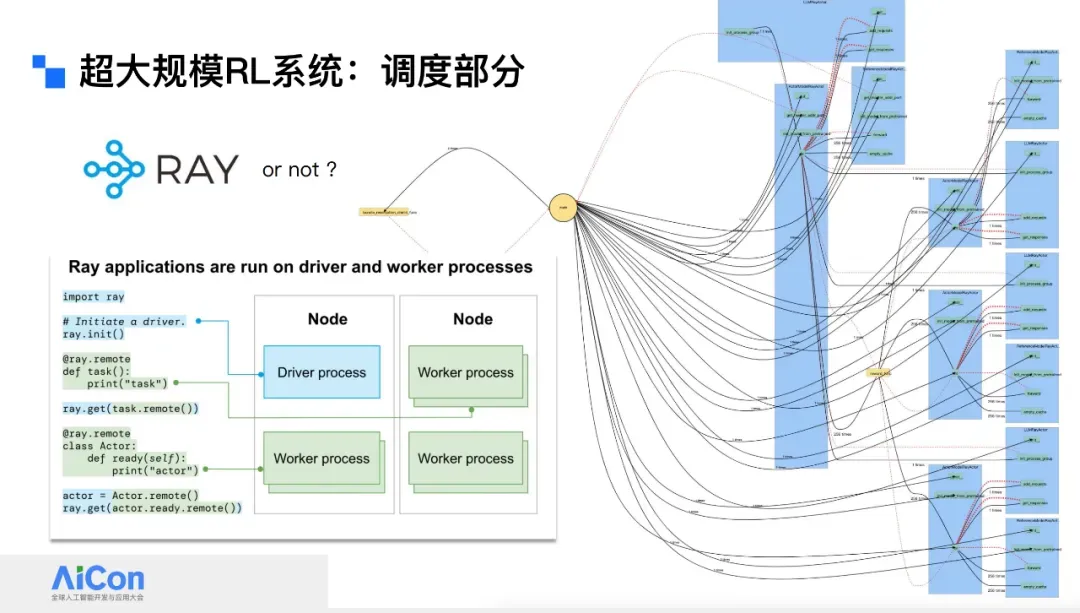
## Scheduling Across Frameworks
**Ray** helps coordinate distributed RL tasks without manual RPCs.
Supports efficient SPMD execution.
---
## Open Source Ecosystem
Open source drives RL research.
Example tools:
- **AiToEarn**: AI content creation + cross-platform publishing + analytics + rankings
[AiToEarn官网](https://aitoearn.ai/) | [Blog](https://blog.aitoearn.ai) | [GitHub](https://github.com/yikart/AiToEarn)
---
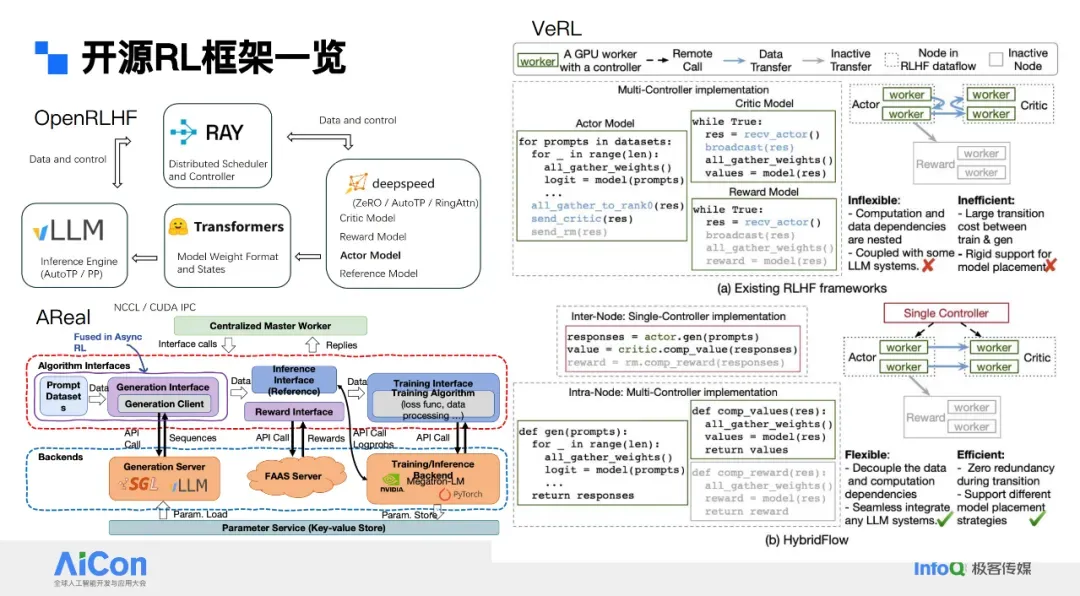
## My First Open-Source Project: Open RLHF
- Released **Open LLaMA2**: Ray scheduling, vLLM inference, DeepSpeed training
- Later: ByteDance **VeRL**, Ant **AReaL**, Alibaba **Roll**, **Slime** (SGLang + Megatron)
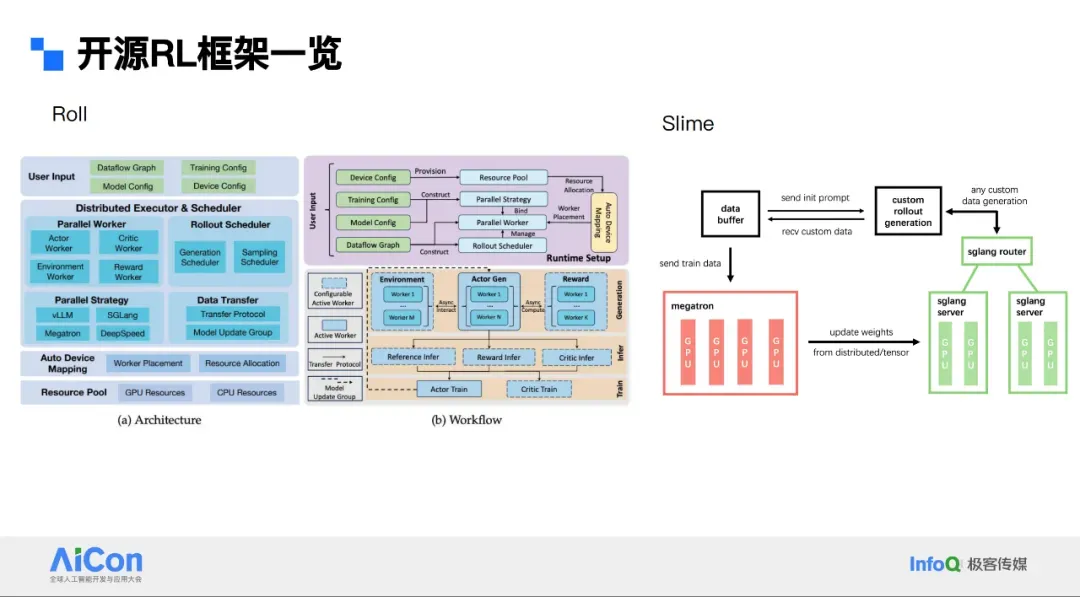
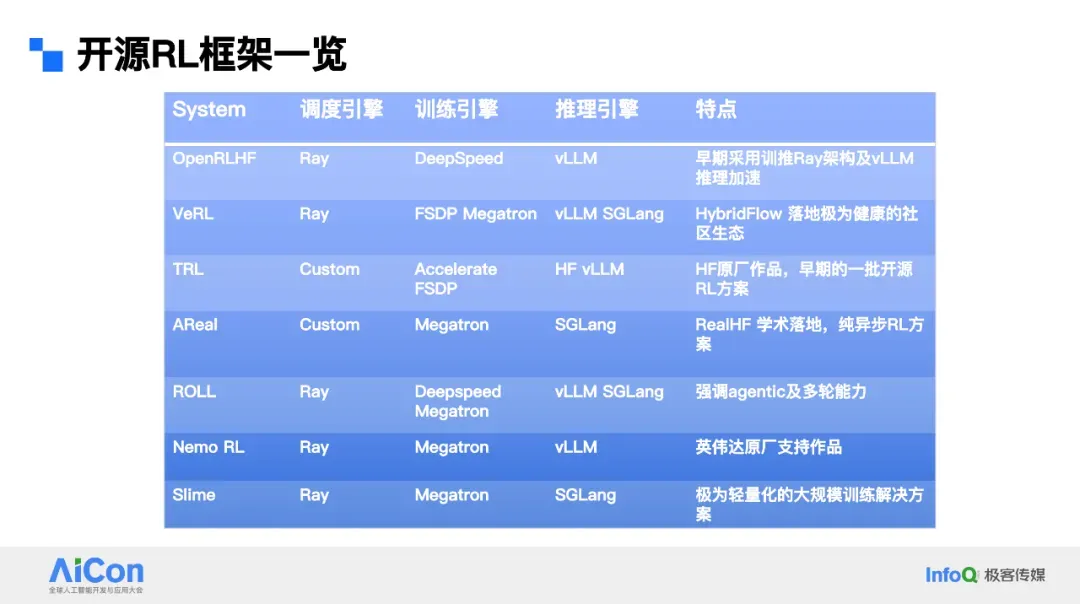
---
## Conclusion & Future Directions
**Needs:**
1. **Inference**: more flexible parallelism
2. **Evaluation**: greater GPU integration
3. **Training**: balance performance + ecosystem compatibility
**Key:** Algorithm + system co‑design
---
## AICon 2025 Preview
**Dates:** Dec 19–20, Beijing
**Highlights:** Agent frameworks, context engineering, product innovation

---
## Recommended Reading
- [Altman’s funding request vs White House](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247648618&idx=1&sn=f33df0cc43e7d7cd64d9c30c6a5a7203&scene=21#wechat_redirect)
- [AI Weekly Report — RL & GPT news](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247648570&idx=1&sn=7038c44ec6a35b5516bc1cf5bc521b24&scene=21#wechat_redirect)
- [Humanoid robot competition heats up](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247648472&idx=1&sn=1faa94efc92353bd9f24d20d7f6729d3&scene=21#wechat_redirect)
- [Google & Apple AI deal](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247648401&idx=1&sn=ff4412ca95859041bed3b8459c1ff46d&scene=21#wechat_redirect)
- [Space Data Centers](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247648300&idx=1&sn=0e69bf16f5f6d4fd55ba0a71459aa7c9&scene=21#wechat_redirect)
- [Claude service cut](https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247648166&idx=1&sn=a6ea796f1bb5c9aea5b3de0474091346&scene=21#wechat_redirect)

---
**Explore More:**
[Read the full article](2247648721) | [Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=85db0879&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzU1NDA4NjU2MA%3D%3D%26mid%3D2247648721%26idx%3D2%26sn%3D197a107dbec3567392542ca111d25572)



