Discussing How DeepSeek-OCR and Glyph Use Visual Compression to Simulate Human Memory Decay and Overcome LLM Context Window Limits

Comparative Analysis: DeepSeek-OCR vs. Glyph in Visual Compression for Long-Context AI
Date: 2025-10-30
Location: Jilin
Both DeepSeek-OCR and Glyph center on the concept of visual compression as a way to overcome the computational challenges large language models (LLMs) face when handling extended sequences of text. This document analyzes their respective approaches, architectures, and impactful differences.


---
1. DeepSeek-OCR — Revolutionizing OCR via Visual Compression
1.1 Objective & Paradigm Shift
Problem: LLM computation costs scale quadratically with sequence length.
Solution: Contexts Optical Compression paradigm:
- Render long text into an image.
- Compress into a small set of visual tokens via a vision encoder.
- Decompress back into text using an LLM.
This approach embeds more information into fewer tokens, efficiently transmitting high-volume text.
1.2 Technical Architecture
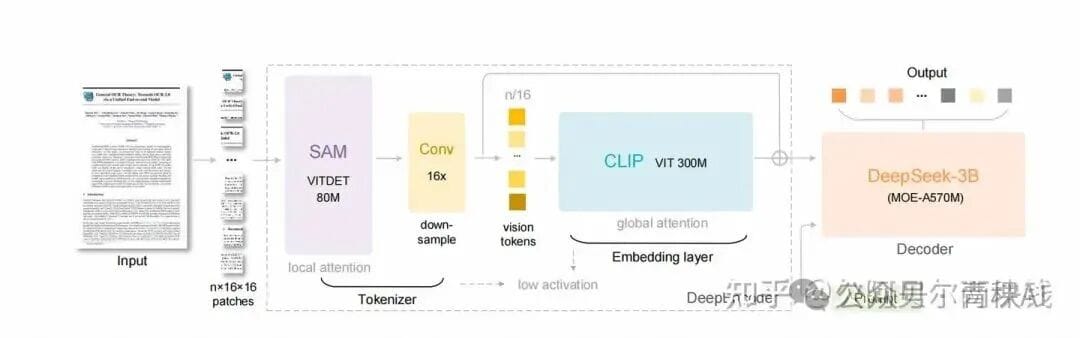
- DeepEncoder (Vision Encoder)
- Combines SAM (local perception) + CLIP (global knowledge).
- Integrates 16× convolutional compression (4,096 → 256 patch tokens).
- Supports multi-resolution input and High Tower Mode for dynamic image stitching.
- Low activation memory — ideal for high-resolution documents.
- DeepSeek-3B-MoE (Decoder)
- Mixture-of-Experts with 570M active parameters.
- Restores text from compressed visual tokens while balancing language capability and inference cost.
1.3 Performance Highlights
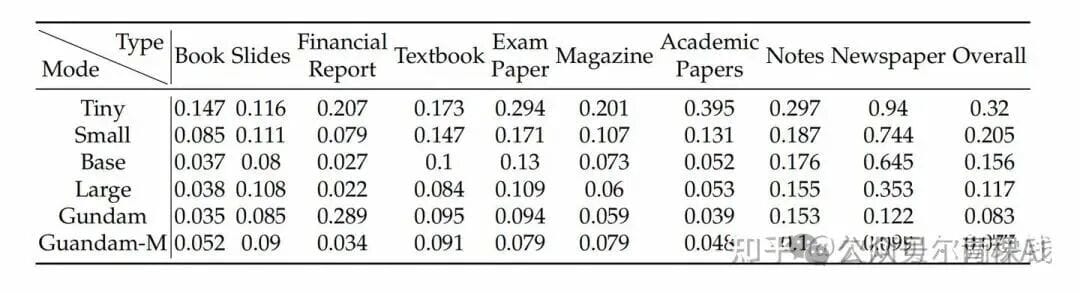
- Compression & Accuracy:
- ≤10× compression → 97% OCR accuracy.
- 20× compression → ~60% accuracy.
- On OmniDocBench, 100 tokens > GOT-OCR2.0 (256 tokens); 800 tokens > MinerU2.0 (>7,000 tokens).
- Industrial Capability:
- Single A100-40G processes 200K+ pages/day, supports 100+ languages.
- Parses charts, chemical formulas, general visual tasks, image captioning, and object detection.

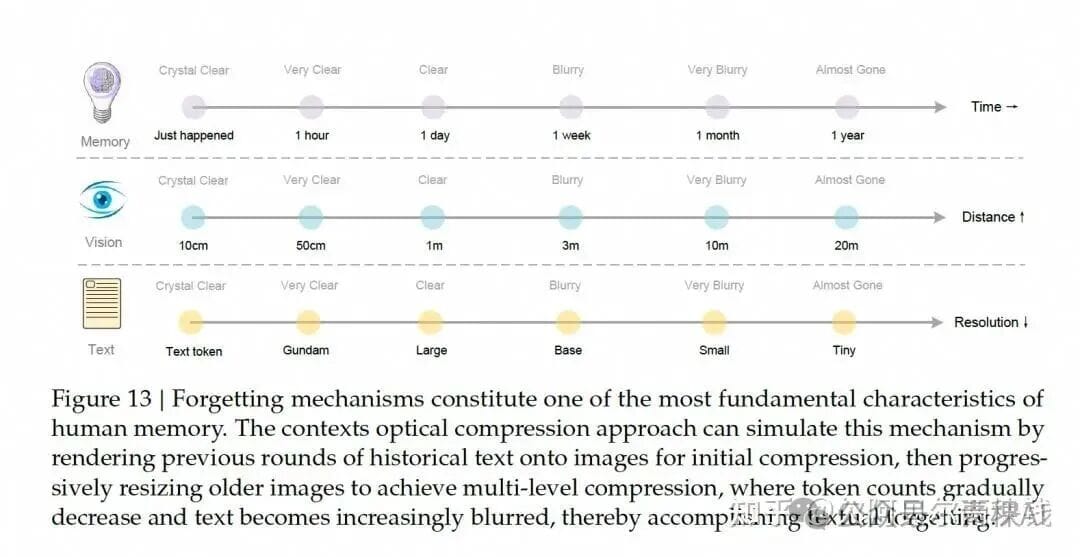
1.4 Deeper Implications — Visual Compression as LLM Memory Mechanism
Simulates human memory:
- Recent context: High-resolution images (high fidelity).
- Older history: Gradual compression into smaller, blurrier images (fewer tokens).
This hierarchical visual memory can support infinite-context LLMs by balancing retention and compute load.
---
2. Glyph — Extending LLM Context via Visual-Text Compression
2.1 Objective & Approach
Goal: Increase LLM context limits without heavy architecture changes.
Method:
- Transform text into images → let the model read visualized text.
- Keep token budget fixed while embedding richer context.
This enables efficient compression for ultra-long textual inputs without structural modifications.
---
Comparison Insight:
- DeepSeek-OCR → Aggressive compression, dual-stage architecture, OCR plus rich vision tasks, inspired by human memory.
- Glyph → Architecturally low-friction, general method for any long-text input.
For creators building long-context AI systems or multimodal pipelines, platforms like AiToEarn官网 facilitate real-world deployment: AI-powered content generation, cross-platform publishing, analytics, and model ranking — all of which benefit from the efficiency visual compression brings.
---
3. Glyph Core Framework — Three Phases
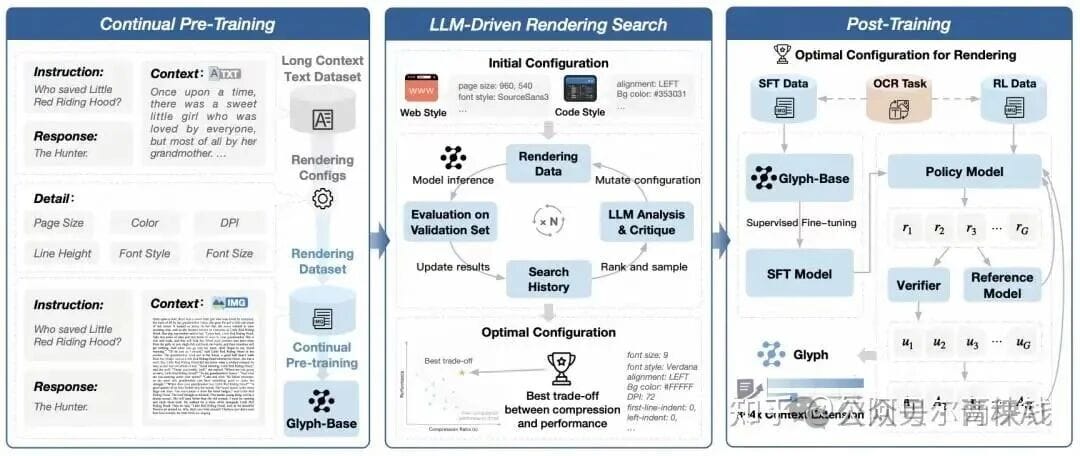
- Continuous Pre-training
- Render text into multiple visual styles (document, web, code).
- Train on OCR, text-image modeling, visual completion to align vision with language.
- LLM-Driven Render Search
- Genetic search algorithm evaluates rendering configs (fonts, resolution, layout).
- Iteratively finds optimal trade-off between compression ratio and comprehension.
- Post-training
- Supervised fine-tuning (SFT) + reinforcement learning (GRPO).
- OCR-assisted tasks strengthen text recognition.
---
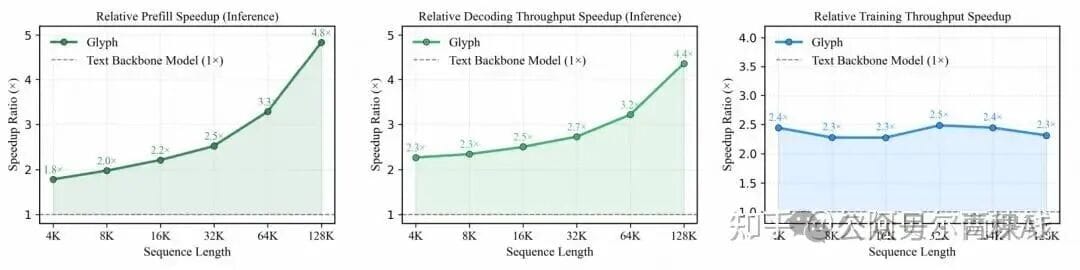
4. Glyph Experimental Results
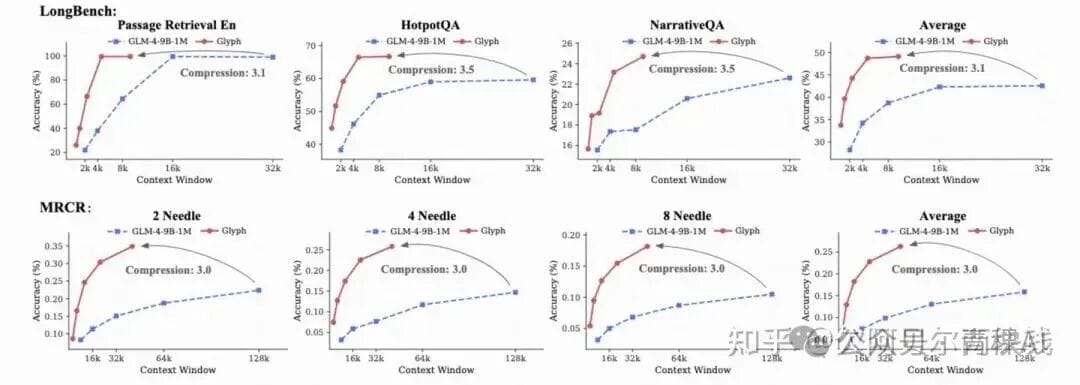
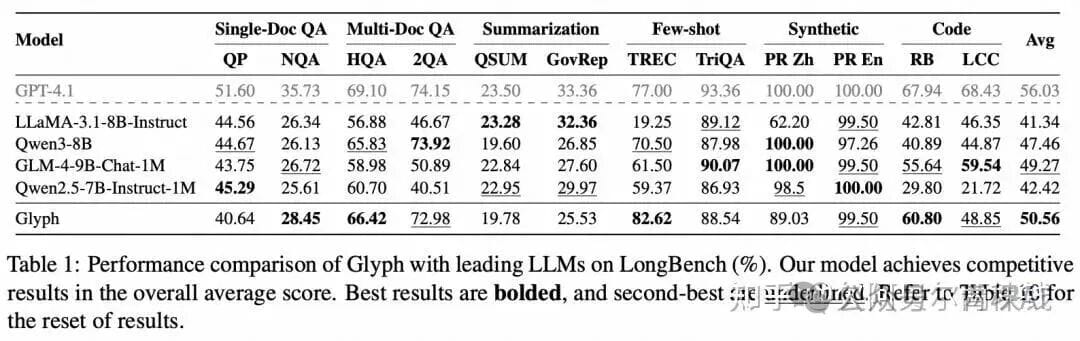
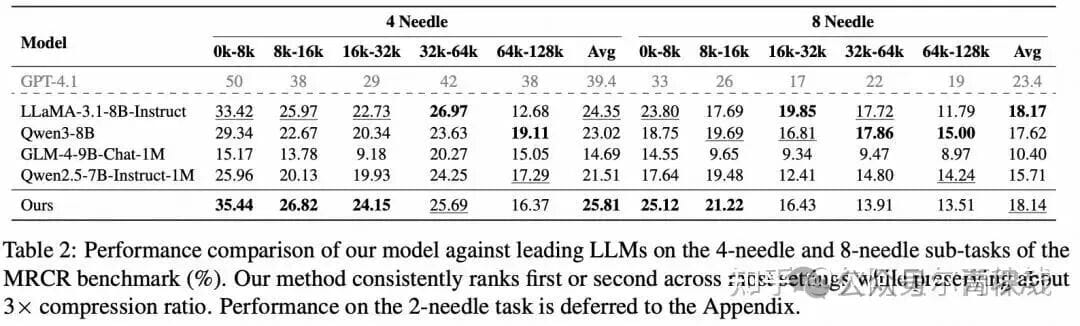
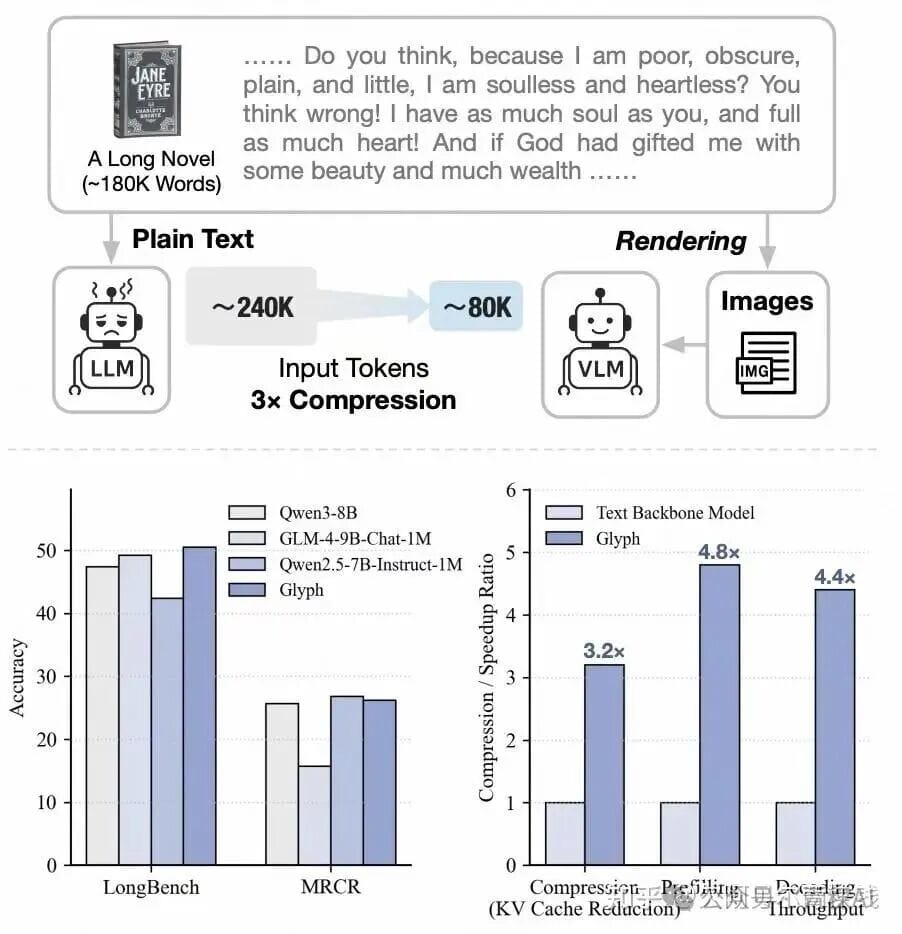
- Compression & Accuracy:
- 3–4× input compression on long-text benchmarks (LongBench, MRCR) → accuracy matches mainstream LLMs (Qwen3-8B, GLM-4-9B-Chat-1M).
- Efficiency Gains:
- 4× faster inference, 2× faster training.
- Greater inference advantage with longer contexts.
- Extreme case: 8× compression allows 128K context VLM to handle million-token tasks.
---
5. Core Differences & Value
Compared to Traditional Context Extension
Glyph does not modify attention or positional encodings — compression happens at the input layer via vision-text encoding. Combined with traditional methods, could reach billion-token contexts.
Compared to DeepSeek-OCR
- DeepSeek-OCR: Specializes in OCR + structured visual tasks under heavy compression.
- Glyph: General-purpose for diverse text scenarios; validates visual compression for any long-text input.
---
6. Comparative Summary Table
| Dimension | DeepSeek-OCR | Glyph |
|-----------|--------------|-------|
| Core Focus | OCR, document parsing | General long-text extension |
| Core Value | OCR efficiency, LLM memory mechanisms | Break context limits, boost long-text processing |
| Compression & Accuracy | ≤10× → 97%; 20× → 60% | 3–4× → mainstream-level accuracy |
| Extra Capabilities | Charts, multilingual OCR, visual understanding | Diverse text styles (docs, code), extreme compression |
---
7. Strategic Impact
Innovations like Glyph show how cross-modal compression can empower LLMs to handle ultra-long contexts without losing precision.
DeepSeek-OCR shows targeted gains in OCR-heavy workloads.
Platforms like AiToEarn官网 integrate these advances into global publishing workflows — connecting AI generation, multi-platform publishing (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter), analytics, and model rankings.
---
8. References
---
9. Technical Community Invitation



Join us:
- Long press or scan QR to add assistant on WeChat.
- Remark format: Name - School/Company - Research Area - City
- Example: Xiao Xia - Zhejiang University - Large Language Models - Hangzhou
- Access deep learning / machine learning exchange groups.
---
10. Recommended Reading
- Latest Survey on Cross-Language Large Models
- Most Impressive Deep Learning Papers
- Practical Deployment Capability of Algorithm Engineers
- Transformer Model Variants Review
- Optimization Algorithms from SGD to NadaMax
- PyTorch Attention Mechanisms

---
> Final Note: For researchers, engineers, and AI practitioners exploring Transformer architectures, attention mechanisms, and optimization strategies, these resources offer both theoretical depth and PyTorch-based practical implementations. Coupled with content monetization platforms like AiToEarn官网, they enable not only experimentation with large-context AI models but also rapid deployment across global platforms.
---
End of Document


