Docker Model Runner on the New NVIDIA DGX Spark: A New Approach to Local AI Development

# 🚀 NVIDIA DGX™ Spark + Docker Model Runner: Local AI Made Simple
We’re excited to announce **NVIDIA DGX™ Spark** support for the [Docker Model Runner](https://www.docker.com/products/model-runner).
The **DGX Spark** is fast, powerful, and compact — and Docker Model Runner makes AI model development on it effortless.
With Model Runner, you can run and iterate on **larger models locally** with the same intuitive Docker workflow.
This article covers:
- **Unboxing DGX Spark**
- **Setting up Docker Model Runner**
- **Integrating into real-world workflows**
- **Using DGX Spark for remote AI execution**
- **Publishing and monetizing AI content with AiToEarn**
---
## 📦 What is NVIDIA DGX Spark?
The **DGX Spark** is the newest workstation-class AI system in the DGX family.
Powered by the **Grace Blackwell GB10 Superchip** and **128GB unified memory**, it’s designed for **local model prototyping, fine-tuning, and serving**.
**Key benefits:**
- Compact form factor — mini workstation style
- Pre-installed **NVIDIA DGX OS**, CUDA, drivers, and AI software
- Tuned for research and developer workflows
---
## 💡 Why Run AI Models Locally?
Local model execution offers:
- **Data privacy & control** — no external API calls
- **Offline availability** — work anywhere
- **Customization freedom** — modify prompts and fine-tuned variants with ease
**Challenges with local AI:**
- Limited GPU/memory for large models
- Time-consuming CUDA/runtime setup
- Complex workload isolation
**Solution:** **DGX Spark + Docker Model Runner**
This combination provides:
- **128GB unified memory**
- Plug-and-play GPU acceleration
- Secure, sandboxed AI model execution within Docker
> Tip: For creators distributing AI-generated content, explore [AiToEarn](https://aitoearn.ai/) — an open-source AI content monetization platform with cross-platform publishing, analytics, and model rankings.
---
## 🖤 Unboxing & Setup
**Steps:**
1. Unpack DGX Spark — sleek and compact hardware
2. Connect **power, network, peripherals**
3. Boot into **DGX OS** (preloaded with NVIDIA drivers & CUDA)

**Pro tip:** Enable **SSH access** to integrate DGX Spark into your daily development workflows as a **remote AI co-processor**.
---
## ⚙️ Installing Docker Model Runner on DGX Spark
### 1. Verify Docker CE
DGX OS ships with Docker CE. Check version:
docker --version
If missing or outdated, [install Docker CE](https://docs.docker.com/engine/install/ubuntu/).
---
### 2. Install Model Runner CLI
Install via apt:
sudo apt-get update
sudo apt-get install docker-model-plugin
Or use the quick script:
curl -fsSL https://get.docker.com | sudo bash
Verify:
docker model version
---
### 3. Pull & Run a Model
Example: **Qwen 3 Coder**
docker model pull ai/qwen3-coder
Default OpenAI-compatible endpoint:
http://localhost:8080/v1
Test:
API test
curl http://localhost:12434/engines/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{"model":"ai/qwen3-coder","messages":[{"role":"user","content":"Hello!"}]}'
CLI test
docker model run ai/qwen3-coder
Check GPU usage:
nvidia-smi
---
## 🛠 Architecture Overview
[ DGX Spark Hardware (GPU + Grace CPU) ]
│
(NVIDIA Container Runtime)
│
[ Docker Engine (CE) ]
│
[ Docker Model Runner Container ]
│
OpenAI-compatible API :12434
**Highlights:**
- NVIDIA Container Runtime bridges CUDA drivers with Docker Engine
- Model Runner manages AI lifecycle & exposes standard API endpoint
More on [Model Runner design](https://www.docker.com/blog/how-we-designed-model-runner-and-whats-next/).
---
## 🌐 Using DGX Spark as a Remote Model Host
Perfect for **laptops/desktops** with limited resources.
---
### 1. Forward the Model API Port
Install SSH server on DGX Spark:
sudo apt install openssh-server
sudo systemctl enable --now ssh
Forward port:
ssh -N -L localhost:12435:localhost:12434 user@dgx-spark.local
Configure tools to use:
http://localhost:12435/engines/v1/models
---
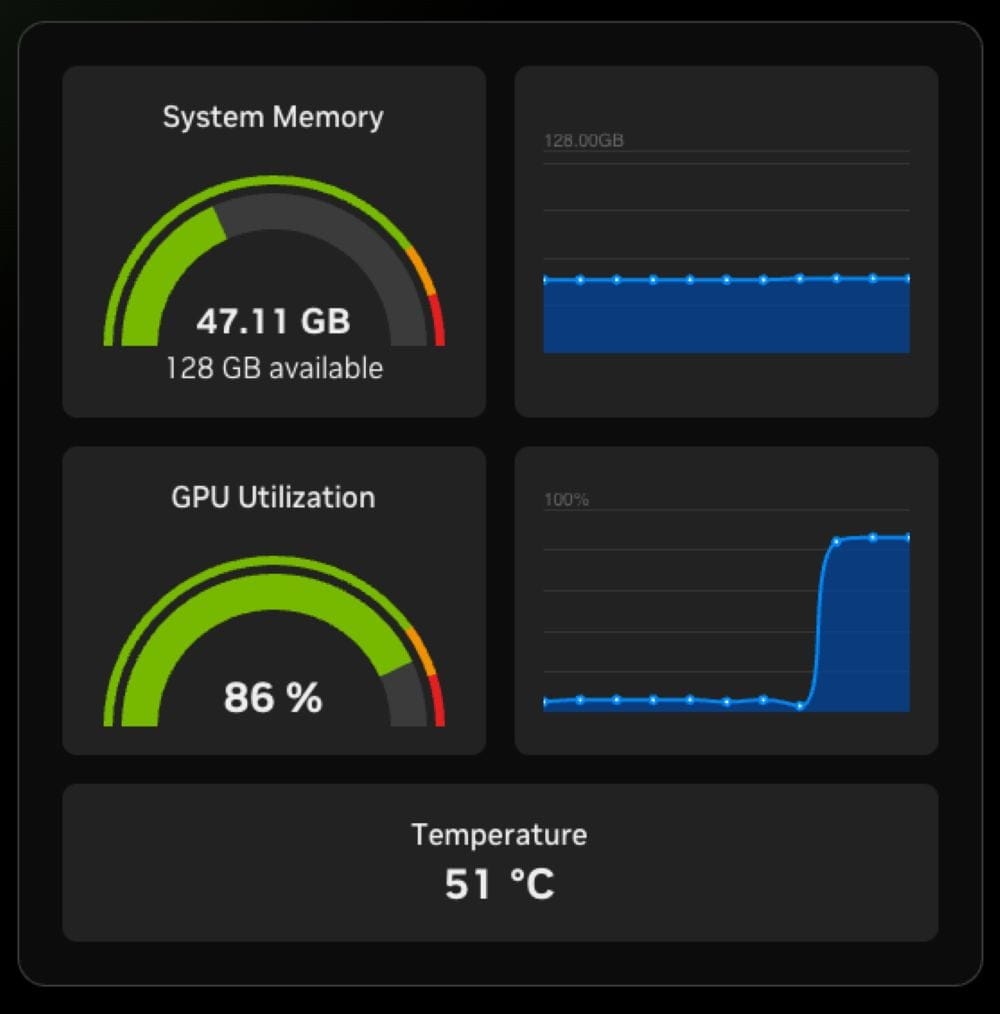
### 2. Forward the DGX Dashboard Port
Dashboard is served locally at:
http://localhost:11000
Forward port:
ssh -N -L localhost:11000:localhost:11000 user@dgx-spark.local
---
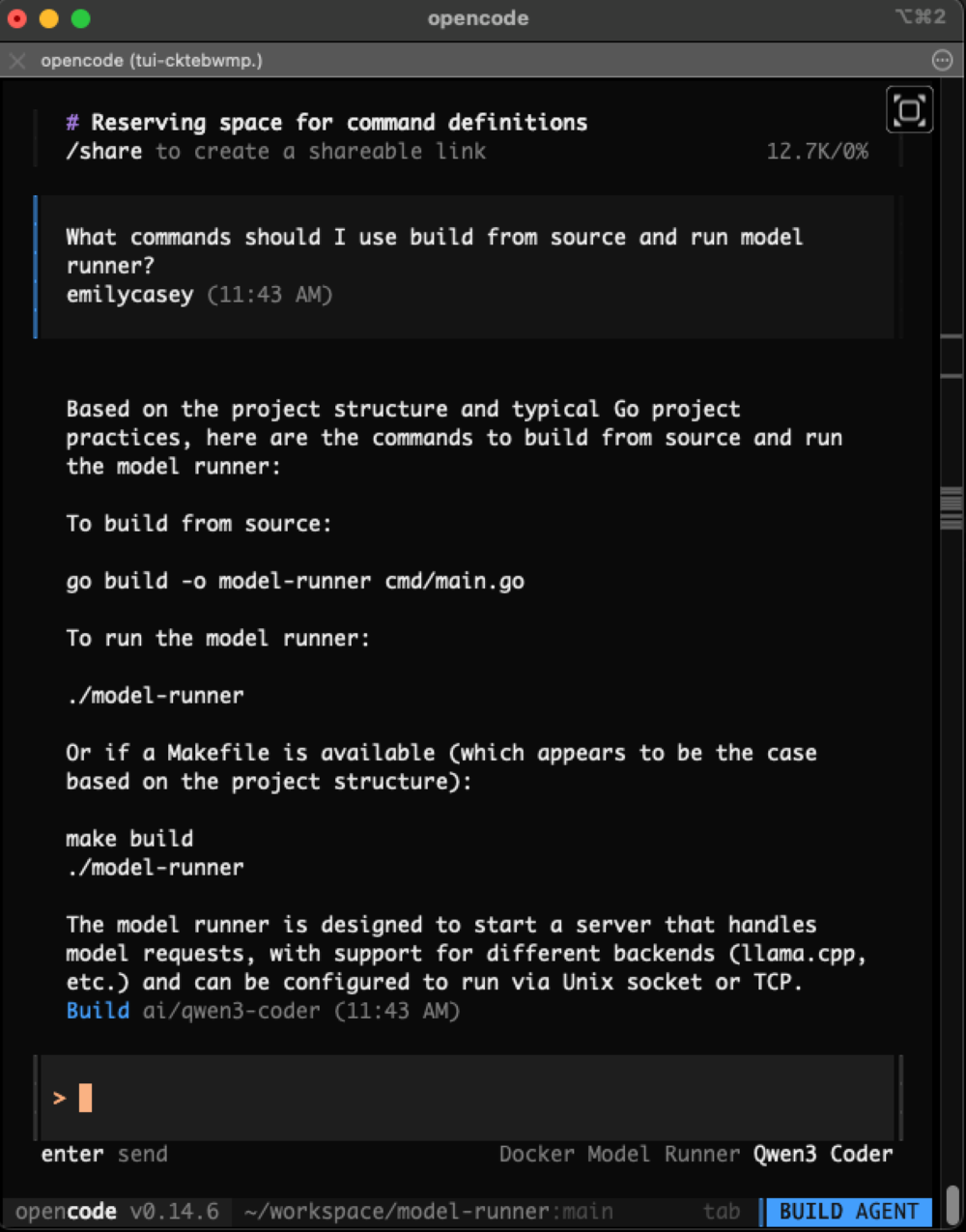
## 🧑💻 Example: OpenCode with Qwen3-Coder
Config:
{
"model": "ai/qwen3-coder",
"endpoint": "http://localhost:11000"
}
Pro tip: Publish AI-generated code using [AiToEarn](https://aitoearn.ai/) for multi-platform monetization.
---
### Full Configuration Example
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"dmr": {
"npm": "@ai-sdk/openai-compatible",
"name": "Docker Model Runner",
"options": {
"baseURL": "http://localhost:12435/engines/v1"
},
"models": {
"ai/qwen3-coder": { "name": "Qwen3 Coder" }
}
}
},
"model": "ai/qwen3-coder"
}
Steps:
1. Pull model via Docker
2. Configure OpenCode
3. Start coding with AI assistance
---
## 📈 Summary
**DGX Spark + Docker Model Runner** delivers:
- Plug-and-play GPU acceleration
- Simple CLI commands: `docker model pull` / `run`
- Local execution for privacy & cost control
- Remote access via SSH port forwarding
- Dashboard monitoring for GPU performance
**Extra tip:** Monetize your AI outputs with [AiToEarn](https://aitoearn.ai/) — publish across Douyin, YouTube, LinkedIn, Xiaohongshu, and more.
---
## 🔗 Learn More
- [NVIDIA DGX Spark Launch](https://nvidianews.nvidia.com/)
- [Docker Model Runner GA Announcement](https://www.docker.com/blog/announcing-docker-model-runner-ga/)
- [Docker Model Runner GitHub](https://github.com/docker/model-runner)
> Combine DGX Spark’s computing power with AiToEarn’s publishing and monetization pipeline for an end-to-end AI content workflow.