Douyin & LV-NUS Release Open-Source Multimodal Model, Achieves SOTA with Small-Scale Design, 8B Inference Rivals GPT-4o
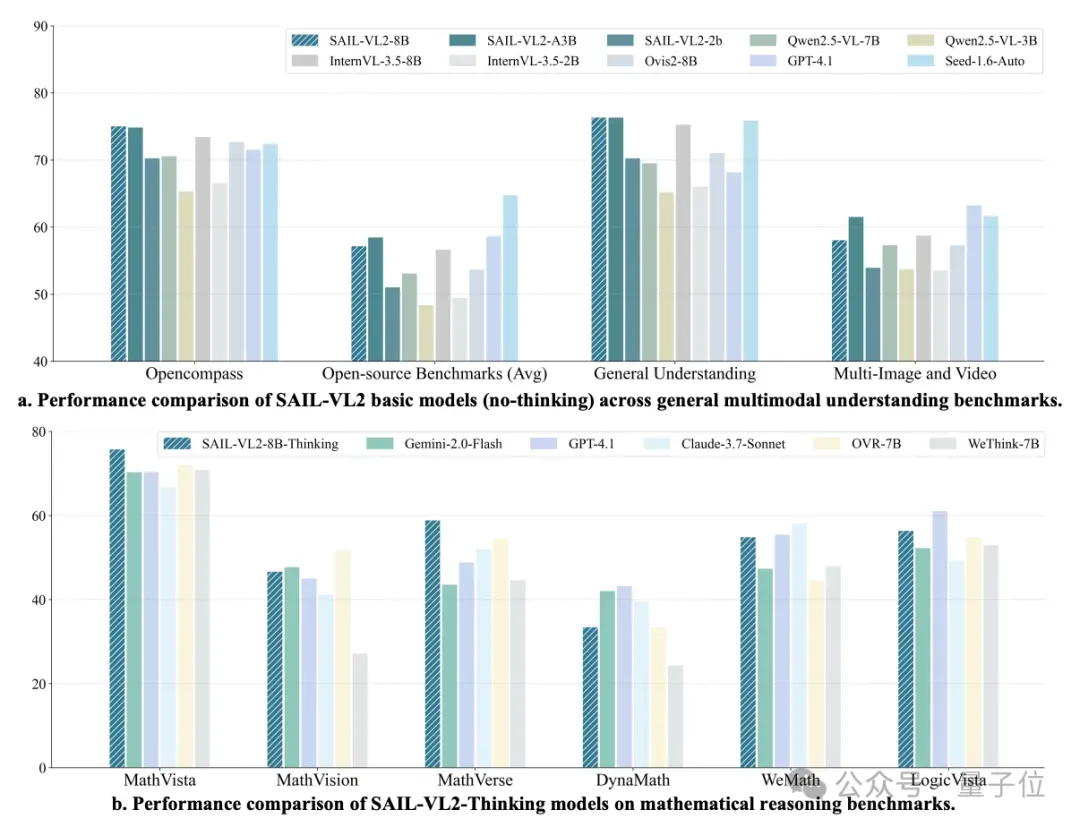
SAIL-VL2: 2B Model Ranked #1 Among Open-Source Models Under 4B Parameters
The SAIL-VL2 multimodal large model — jointly developed by Douyin's SAIL team and LV-NUS Lab — has achieved remarkable results.
With 2B and 8B parameter versions, it has set performance breakthroughs across 106 datasets, rivaling or surpassing both similar-scale and much larger closed-source models in complex reasoning benchmarks such as MMMU and MathVista.
---
Key Innovations
SAIL-VL2 advances the field through data, training, and architecture improvements, proving that small models can be powerful. It combines fine-grained visual perception with reasoning abilities comparable to large-scale systems. Both model weights and inference code are open-sourced for community use.

---
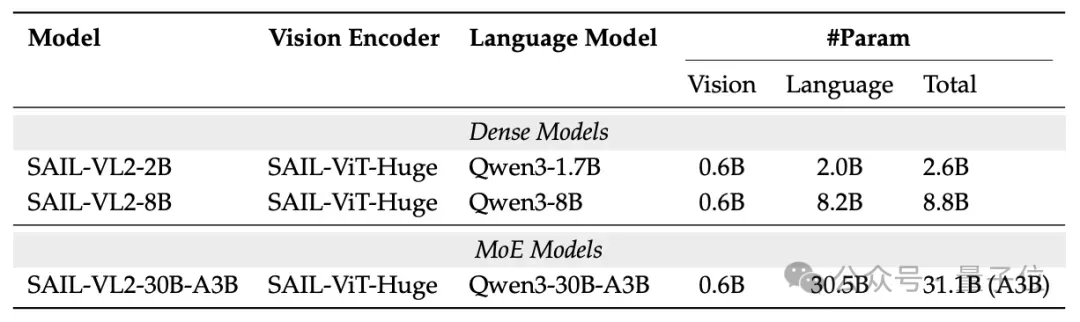
Architecture Highlights
SAIL-VL2 diverges from traditional dense LLMs by using a sparse Mixture of Experts (MoE) approach, with flexible configurations targeted at diverse applications:
---
SAIL-ViT: Progressively Optimized Visual Encoder
To solve visual–language alignment, SAIL-VL2 uses a three-stage strategy:
- Warm-up Adaptation
- Freeze SAIL-ViT and LLM
- Train only the Adapter with 8M data
- Activate cross-modal mapping
- Fine-grained Alignment
- Freeze LLM
- Unlock SAIL-ViT and Adapter
- Train with 6.7M caption & COR data for deeper alignment
- World Knowledge Injection
- Unlock all parameters
- Use 36.5M multi-task data to improve generalization
Results:
- Nearest-neighbor distance: 1.42 → 1.15
- Wasserstein distance: 4.86 → 3.88
- Both indicate stronger alignment.
---
MoE Architecture: Efficiency & Balance
- 31.1B model uses Qwen3-MoE, activating 3B parameters per inference.
- Load-balancing losses and data calibration improve expert activation entropy by 20%, ensuring specialization.
---
SAIL-ViT-AnyRes: Flexible Visual Resolution
- 2D RoPE interpolation allows arbitrary input resolutions, up to 1792×1792.
- In RefCOCO localization tasks, SAIL-ViT-AnyRes scores 57.82 vs. 53.28 for fixed-resolution models.
---
Automated Data Pipeline
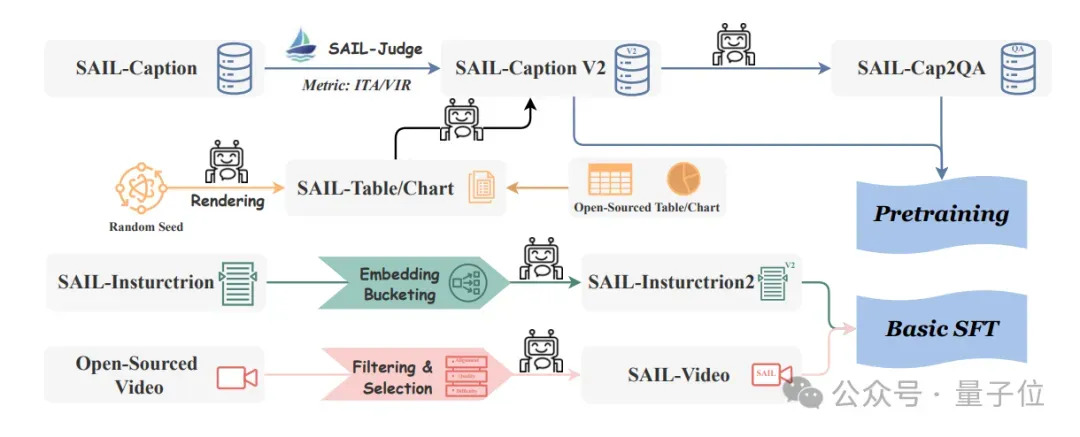
Two main strategies: quality filtering & scope expansion.
- SAIL-Caption2
- Scores Visual Info Richness (VIR) and Image–Text Alignment (ITA) from 1–5
- Discards samples <3
- Produces 250M general captions and 1.69M chart captions
- Synthetic VQA from captions boosts QA dataset diversity
- Pure Text & Multimodal Instruction Data preserve LLM language and strengthen instruction-following
---
Progressive Pretraining: Perception → Reasoning
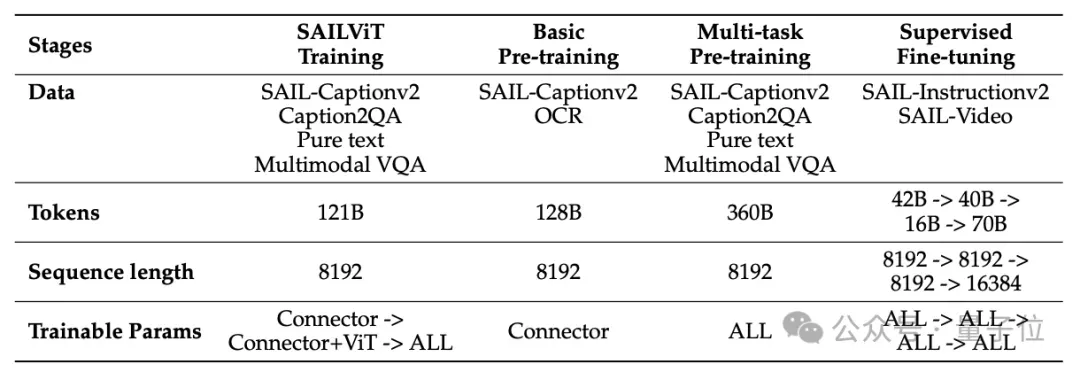
Two-Stage Multimodal Pretraining
- Basic Pretraining with 64M data for cross-modal alignment
- Multi-task Pretraining with 180M data for visual comprehension & instruction-following
Data Resampling
- Balances datasets
- Optimizes n-gram distribution
- Mitigates bias
- Improves training efficiency
---
SAIL-Video: Video QA Alignment
- Screened 6 datasets, yielding 6.23M samples
- Dual scoring: QA alignment, content richness, QA difficulty
- Result: 5.1M high-quality video-QA pairs
---
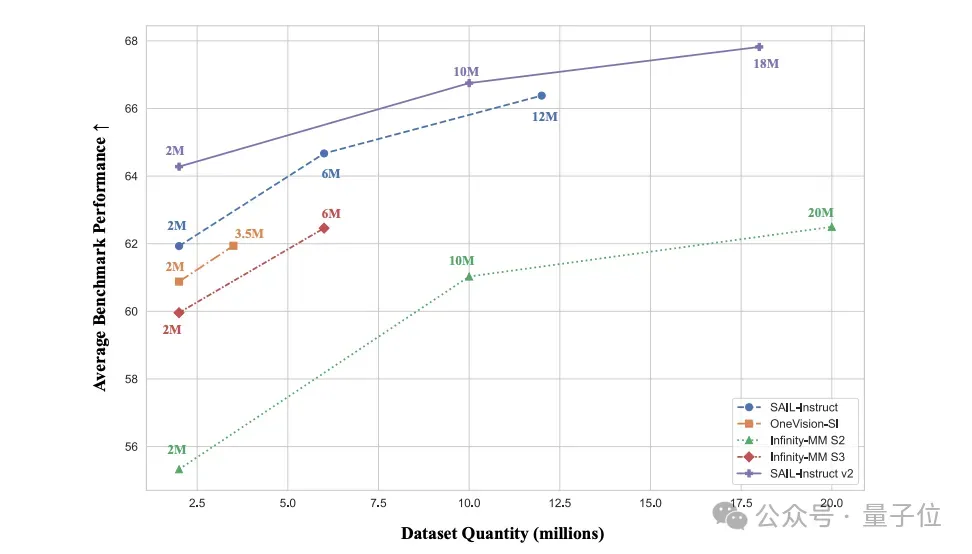
SAIL-Instruction2: Instruction Fine-Tuning
- Uses datasets like Mammoth & MMPR
- Dual validation + category filtering
- Generates 20M instruction samples
---
Multimodal Chain-of-Thought (CoT) Data
- Sources: VisualWebInstruct, MathV360K
- Filtered for challenging yet solvable
- Result:
- 400k LongCoT SFT samples
- 1M Think-Fusion SFT samples
- 150k RL samples
---
Five-Stage Post-Training Strategy
- Base SFT – 4-stage data injection with model fusion for strong instructions
- LongCoT SFT – 400k CoT samples for stepwise reasoning
- Verifiable Reward RL – Dual rewards for correctness & format compliance, focusing on STEM accuracy
- Think-Fusion SFT – Mixed data + conditional loss for flexible reasoning
- Mixed Reward RL – Complex 3D signals for balanced reasoning & concise output
---
Training Efficiency Optimizations
- Dynamic Batch Packaging
- Concatenate samples to reduce padding
- +50% training speed, +0.7% QA performance
- Visual Token Balance
- Relieves encoder memory pressure
- +48% efficiency
- Kernel Fusion – Fewer memory ops, ×3 MoE training speed
- Streaming Data Loading + Hybrid Parallelism – Reduced communication overhead
---
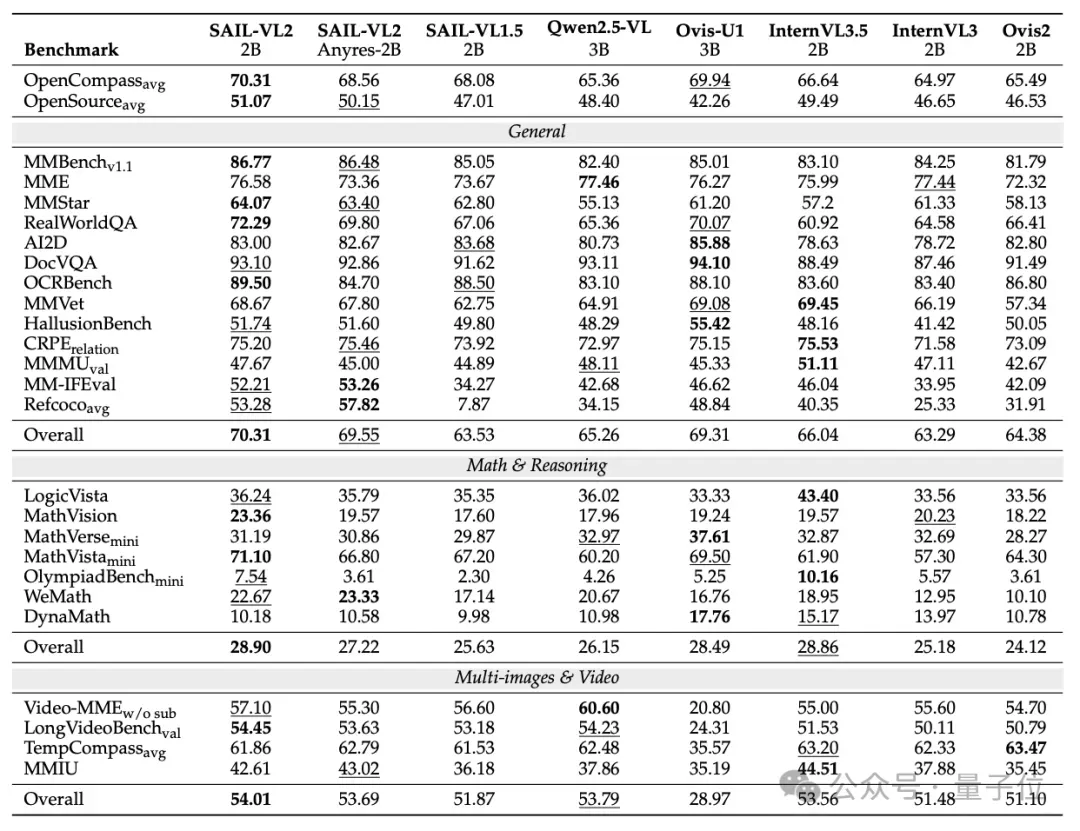
Benchmark Results
General Multimodal Benchmark
- SAIL-VL2-2B: 70.31 OpenCompass
- Surpasses Qwen2.5-VL-3B (65.36) & InternVL3.5-2B (66.64)
- #1 open-source under 4B parameters
- SAIL-VL2-8B: Highest score in similar-scale category
---
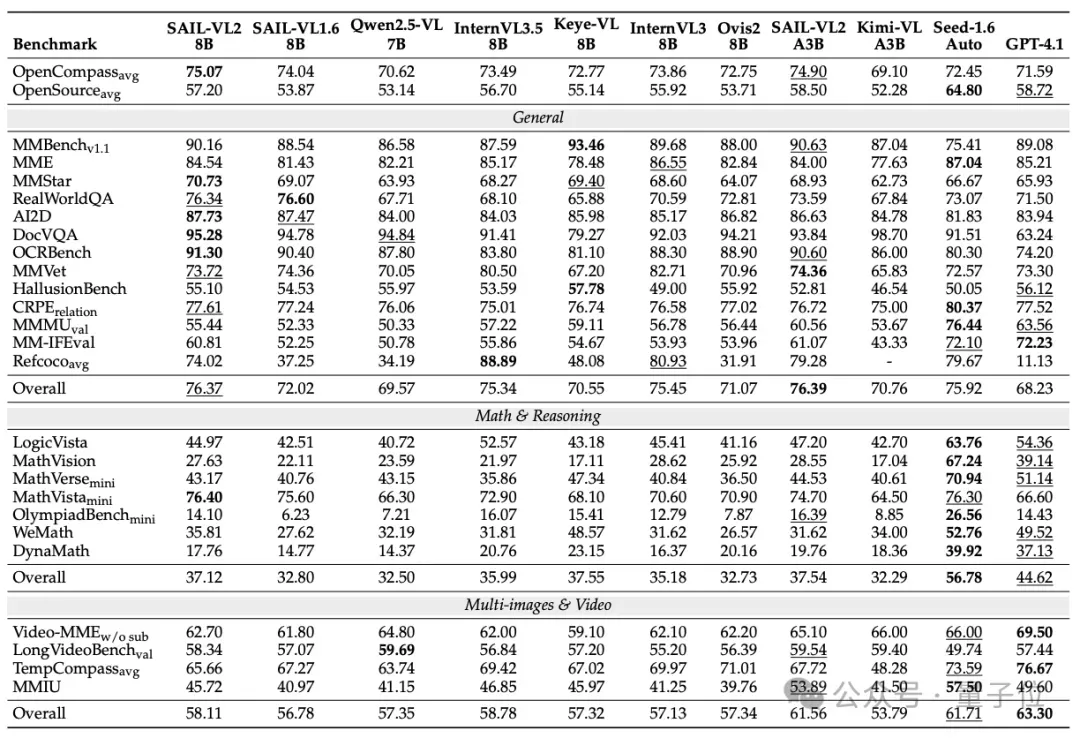
Fine-Grained Tasks
- SAIL-VL2-2B:
- MMStar: 64.07
- OCRBench: 89.50
- SAIL-VL2-8B:
- MMStar: 70.73
- OCRBench: 91.30
---
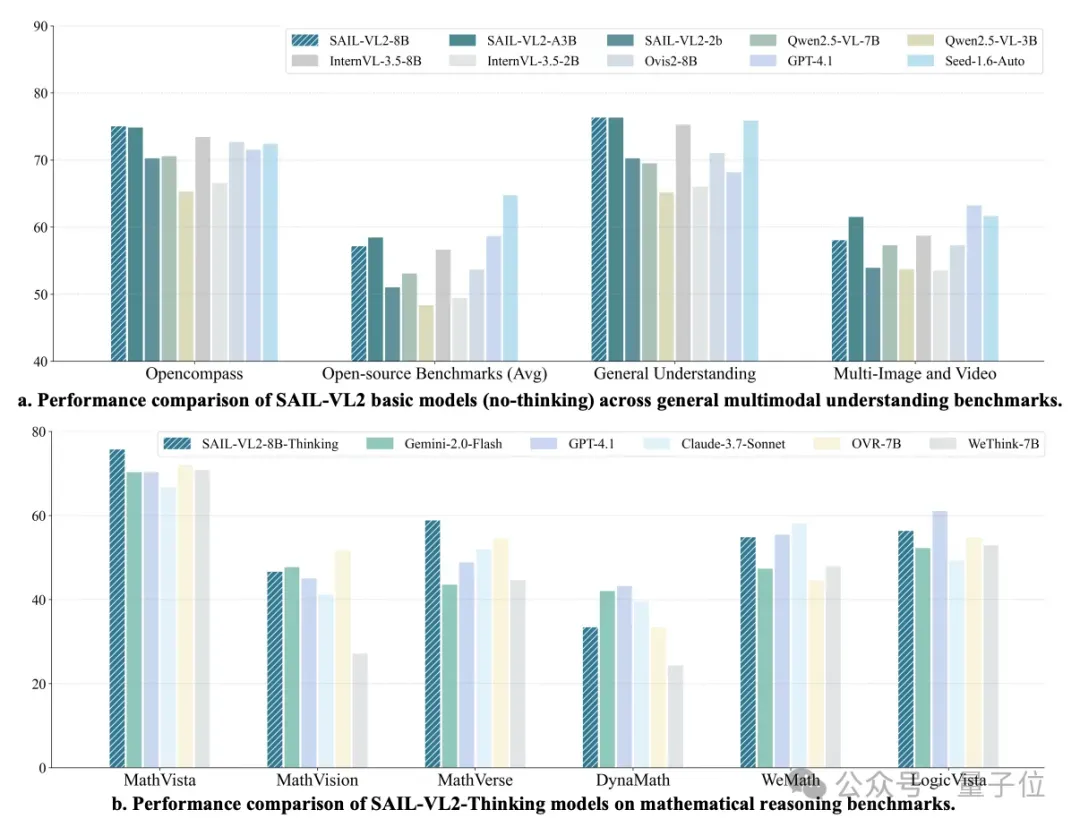
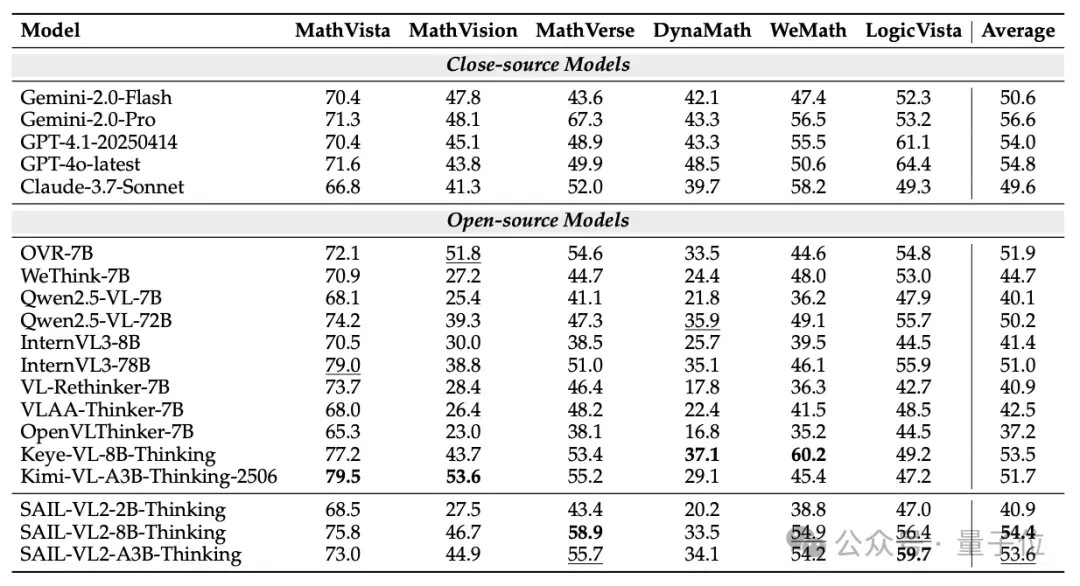
Multimodal Reasoning
- SAIL-VL2-8B-Thinking: 54.4, 2nd only to GPT-4o-latest (54.8)
- SAIL-VL2-A3B-Thinking: 53.6, beating Gemini-2.0-Flash (50.6)
---
Practical Integration & Monetization
Platforms like AiToEarn官网 integrate powerful models, cross-platform publishing, analytics, and ranking — enabling creators to monetize AI outputs (image, video, text) across networks like Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).
---
Paper: https://arxiv.org/pdf/2509.14033
Code & Models: https://github.com/BytedanceDouyinContent/SAIL-VL2
Hugging Face Model Hub: https://huggingface.co/BytedanceDouyinContent
---
AiToEarn Resources
---
If you’d like, I can also create a compact executive summary version of this Markdown, keeping all the essential data points but making it digestible in less than 500 words. Would you like me to prepare that?



