EntropyLong: Efficient Long-Context Training via Uncertainty Prediction
EntropyLong: An Information-Theoretic Approach to Long-Text Training Data

EntropyLong is a long-text data construction method based on predictive uncertainty.
It identifies locations of missing information by measuring a model’s prediction entropy, retrieves relevant distant context, and verifies whether this context reduces uncertainty — ensuring training data contains genuine long-range dependencies.
Unlike heuristic methods, EntropyLong is grounded in information theory, guaranteeing measurable information gain for each constructed dependency.
> Paper link: Arxiv: 2510.02330
---
1. Background: Challenges in Long-Text Training
Large language models now support context windows of millions of tokens, but native high-quality long documents are rare.
Naively concatenating short documents does not yield true long-range relationships, so models fail to utilize long contexts effectively.
Existing Synthetic Approaches
- Query-driven – retrieve semantically related documents to form coherent sequences.
- Contrast-driven – interleave relevant docs with distractors for better discrimination.
- Task-driven – synthesize data targeting specific long-text capabilities.
- Self-generated – have LLMs create their own long-context content.
Limitations:
All these methods assume certain constructions are “good” without verifying actual utility for the model.
---
2. EntropyLong: Data Construction from Model Uncertainty
2.1 Core Insight – Prediction Entropy Marks Missing Information
A position with high entropy means the model is unsure and missing key context.
If distant information reduces entropy, a genuine dependency exists.
Entropy at position t:
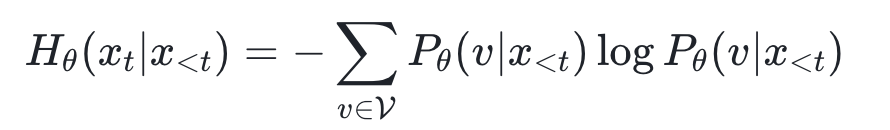
- High-entropy points → anchor positions for adding context.
---
2.2 Guiding Principle – Maximize Measured Information Gain
We define Contextual Information Gain as the reduction in entropy after adding candidate context:
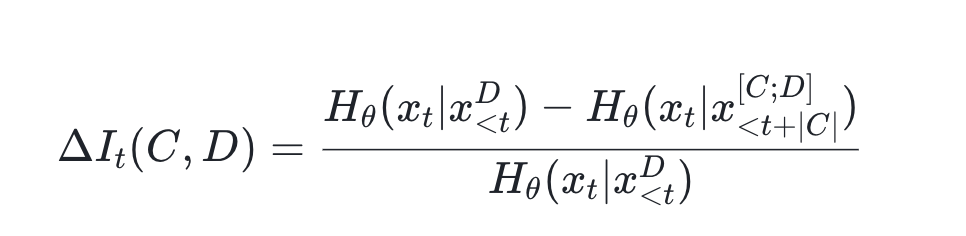
Practical implications:
- Empirical Validation – Only accept contexts that measurably reduce entropy.
- Information-Theoretic Selection – Pick contexts that maximize validated gain.
---
2.3 Testable Hypotheses
- Necessity of Validation – Data with validated contexts will outperform semantic-only retrieval sets for fine-grained dependencies.
- Optimal Thresholds – Ideal thresholds for both high-entropy detection and context acceptance balance quality and quantity of training data.
---
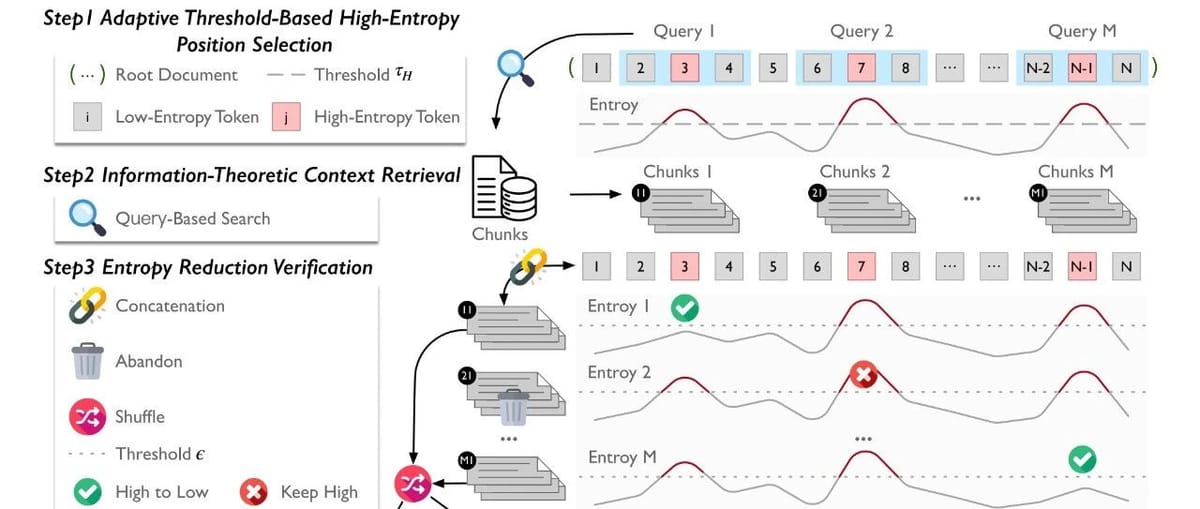
3. Methodology: Four Stages
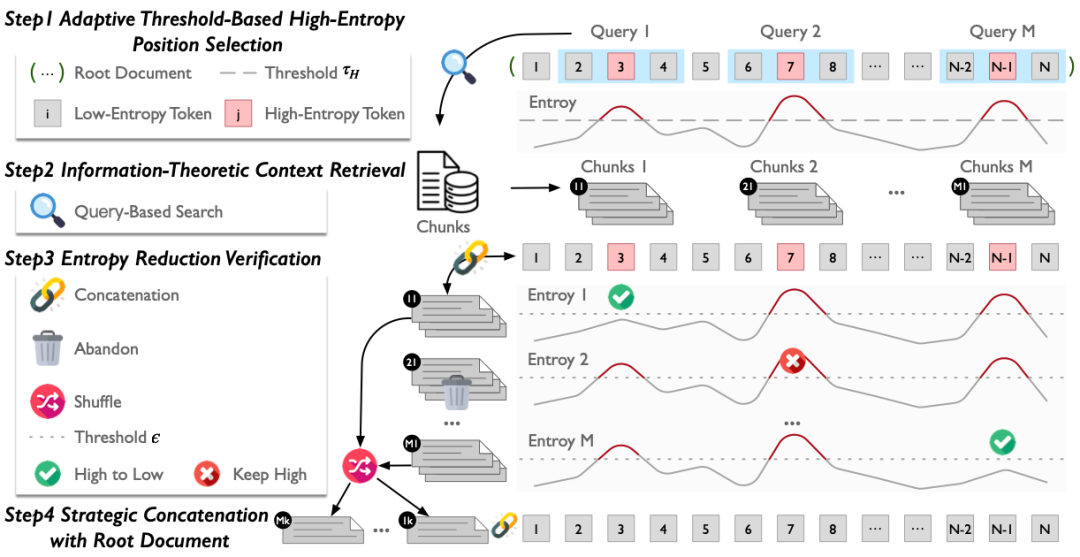
Stage 1 – High-Entropy Position Selection
- Compute entropy for each document position.
- Use adaptive threshold:
- where \(\bar{H}\) and \(\sigma_H\) are mean and std dev of entropy, \(\alpha\) is selectivity (e.g., 1.5).
- Mark positions meeting condition as high-uncertainty anchors.
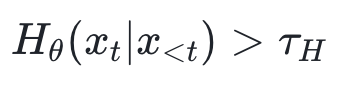
---
Stage 2 – Context Retrieval by Information Theory
- For each high-entropy position \(p\), select a window \(w\) before and after.
- Use this window as a dense-vector search query over a large corpus.
- Rank by cosine similarity; keep top \(k\) candidates.
---
Stage 3 – Entropy Reduction Verification
- Prepend each candidate context to original doc.
- Recompute entropy at anchor positions:
- Keep only contexts meeting reduction threshold:
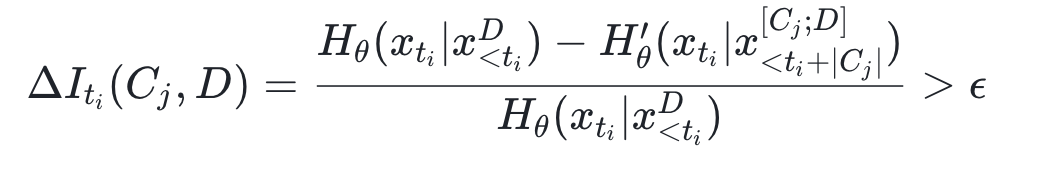
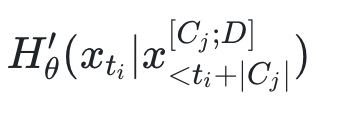
---
Stage 4 – Strategic Concatenation
- Randomly shuffle verified contexts linked to different high-entropy points.
- Concatenate to form final training sequence.
---
4. Experiments & Results
4.1 Setup
- Base Model: Meta-Llama-3-8B
- Context: Expanded to 128K tokens via RoPE adjustment.
- Steps: 1000 steps, batch 4M tokens.
- Dataset: FineWeb-Edu, Cosmopedia, 100K docs sampled, retrieval corpus >1B docs.
- Baselines: Quest (semantic concat), NExtLong (distraction-based concat).
- Benchmarks: RULER, LongBench-v2.
4.2 Results
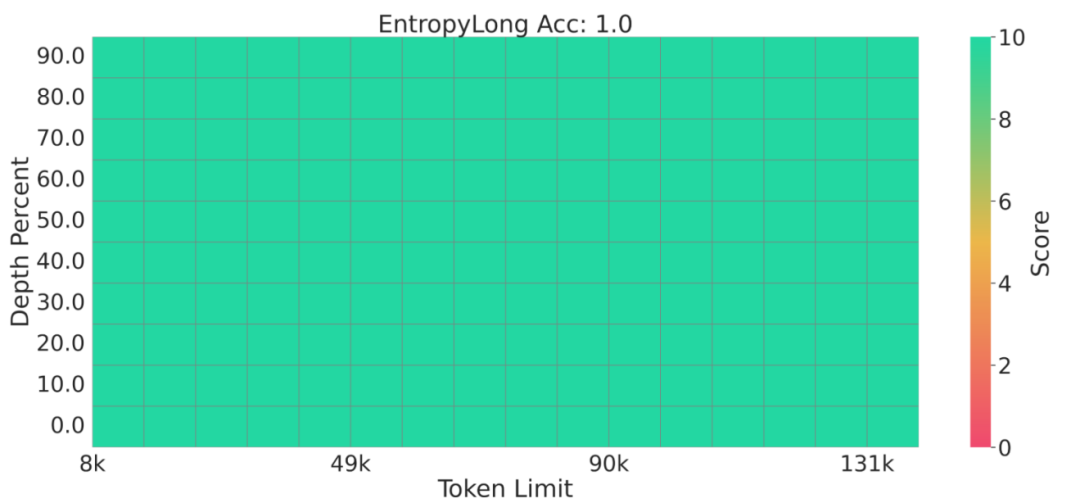
RULER
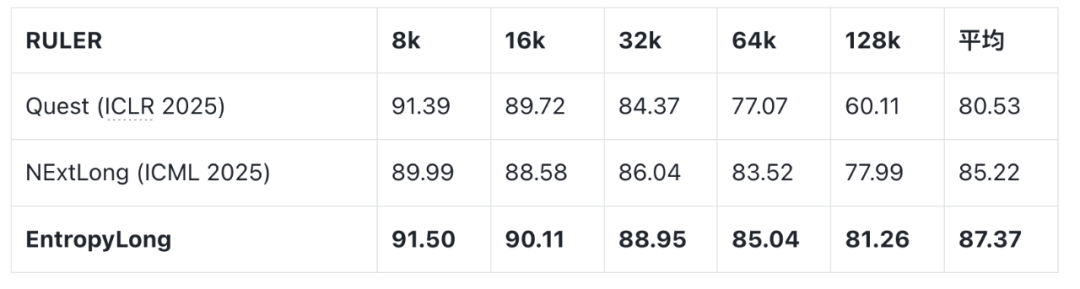
- Avg score: EntropyLong 87.37 vs Quest 80.53, NExtLong 85.22.
- At 128K: 81.26 vs Quest 60.11, NExtLong 77.99.
LongBench-v2 (after instruction fine-tuning)
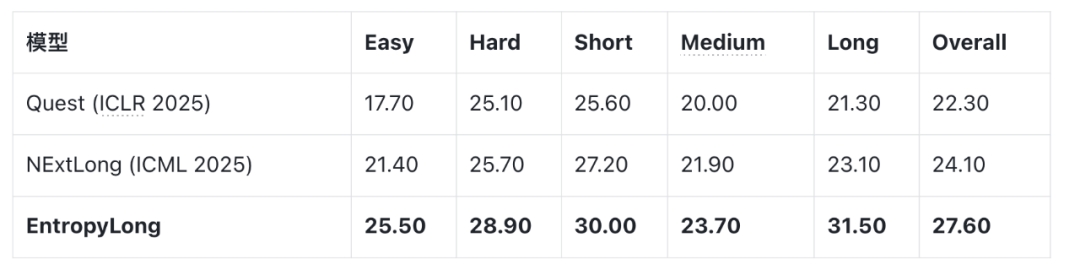
- Strong transfer across domains.
- “Long” task score: 31.50 vs Quest 21.30, NExtLong 23.10 (+8.40 best baseline).
---
5. Analysis: Why EntropyLong Works
5.1 Validation is Crucial (Hypothesis 1)
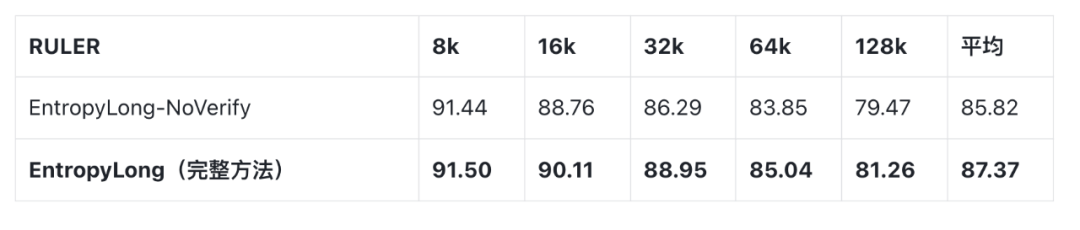
- Full EntropyLong: 87.37
- NoVerify version: 85.82 → drop due to false correlations retained.
5.2 Threshold Effects (Hypothesis 2)
High-Entropy Selection Threshold
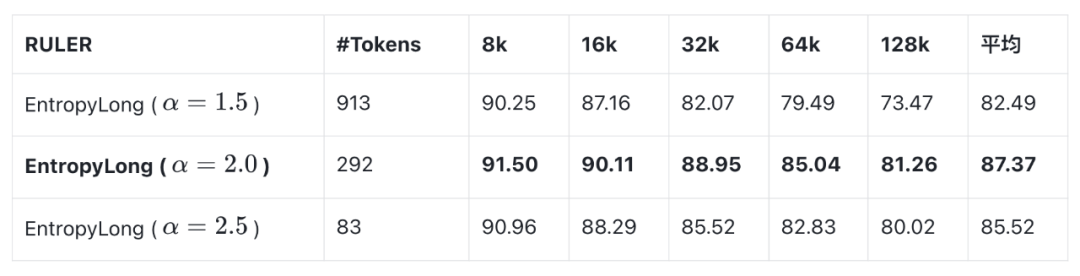
- Low: too many positions (noise), score drop.
- High: too few positions, insufficient training signal.
- Optimum: 292 positions.
Entropy Drop Threshold
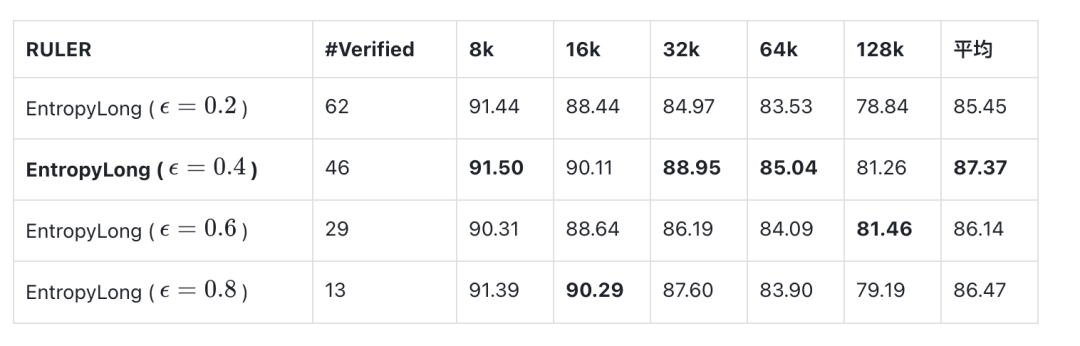
- Low: accepts weak contexts.
- High: too restrictive.
- Optimum: 46 dependencies → thresholds 2.0 & 0.4 validated.
---
5.3 Attention Pattern Analysis
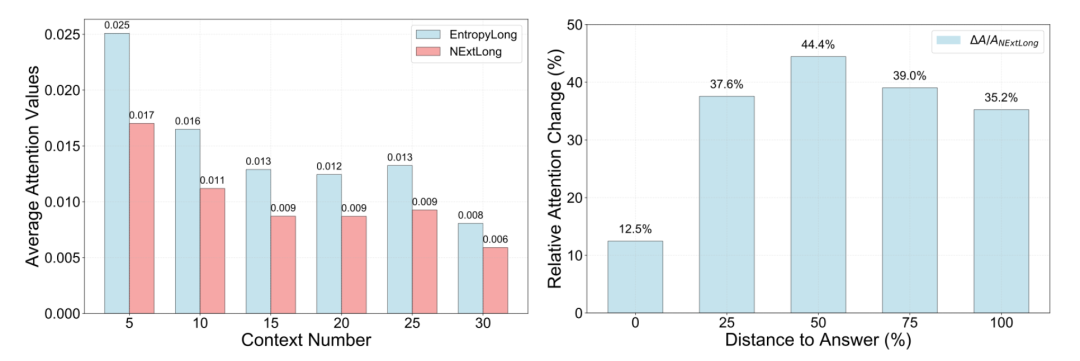
- Length expansion: EntropyLong attention stable toward correct answer across context sizes.
- Middle loss mitigation: +12–44% improvement over NExtLong at mid-sequence positions.
---
6. Conclusion
EntropyLong transforms long-text data construction from heuristic to evidence-based, leveraging model uncertainty to guide context selection.
Experiments confirm:
- Empirical validation → tangible gains.
- Threshold optimization → strong balance of quality and quantity.
- Superior performance → across synthetic and real-world long-text benchmarks.



---
Further Reading:


